-
日志收集分析平台原理
日志收集分析平台原理
集群 – 服务
集群好处:负载均衡 高可用
故障时:应急预案
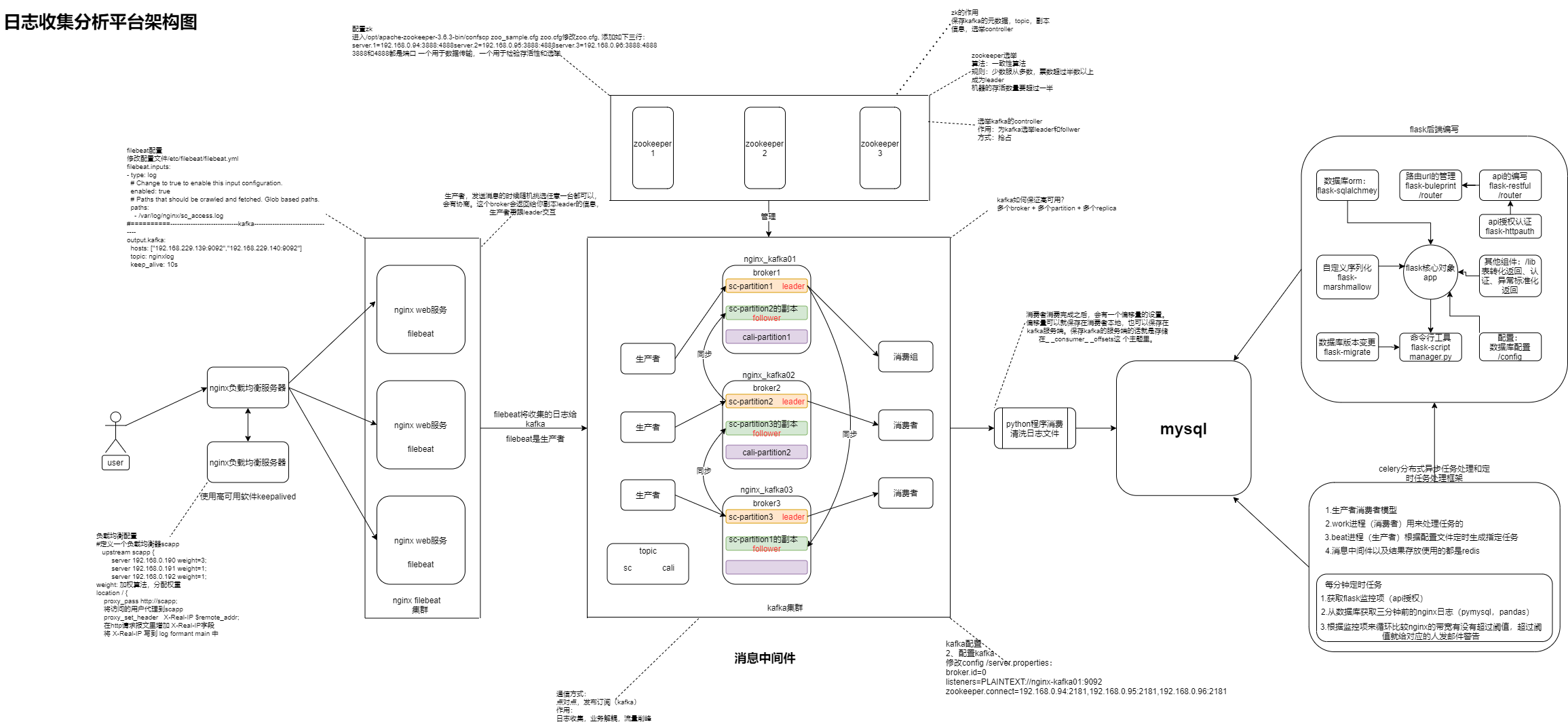
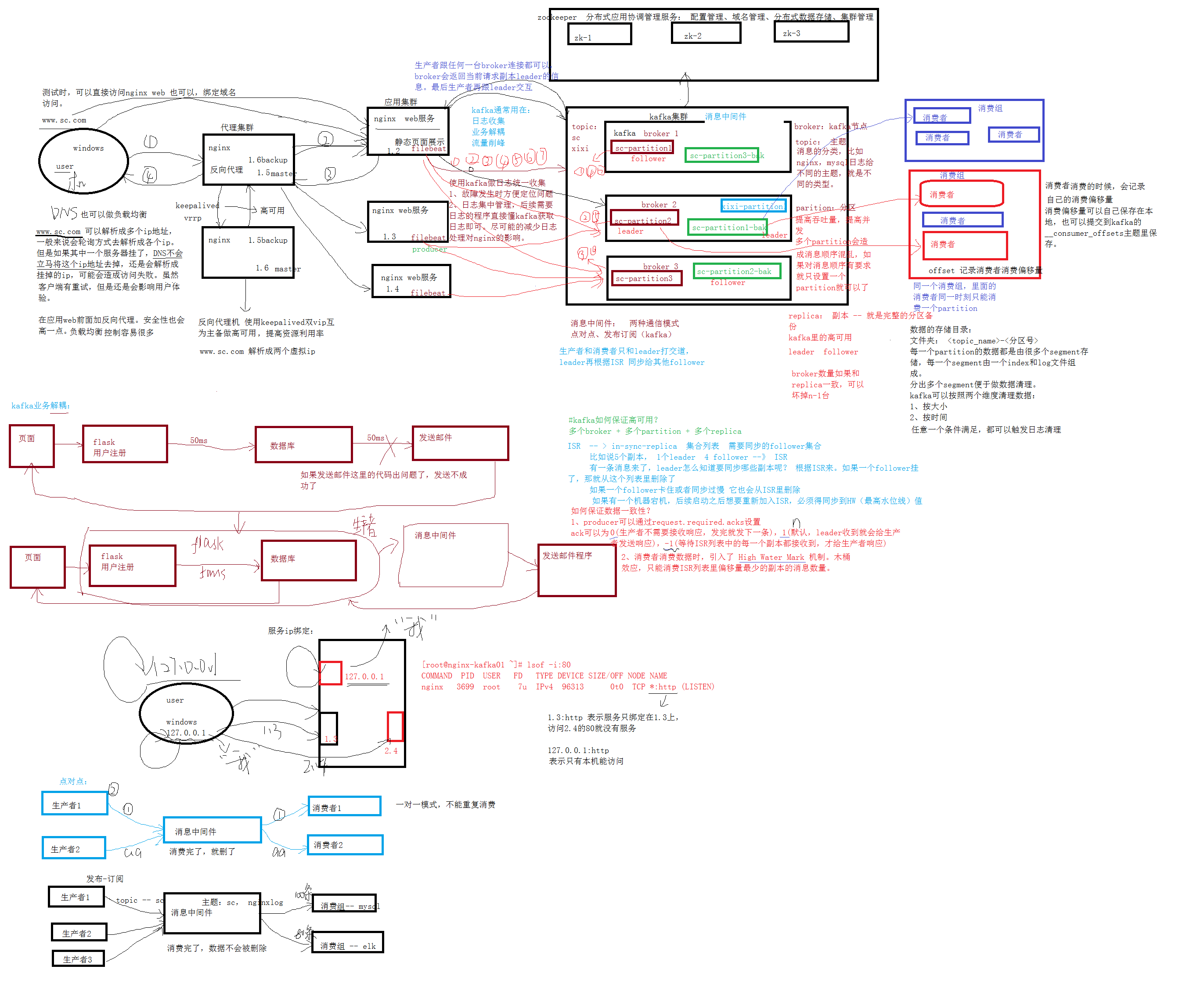
整个框架中filebeat将日志文件整理写入kafka,filebeat相当于是一个生产者
写入数据的就是生产者,读取数据的是消费者
高可用
硬件层面:
网卡(bonding 物理层面2块网卡 逻辑层面1块)
磁盘 磁盘阵列 raid
架构层面
集群
异地多活
信息:集中处理
效率:瓶颈 – 引入中间层
反向代理:代理服务器
测试时,可以直接访问nginx web,也可以绑定域名访问
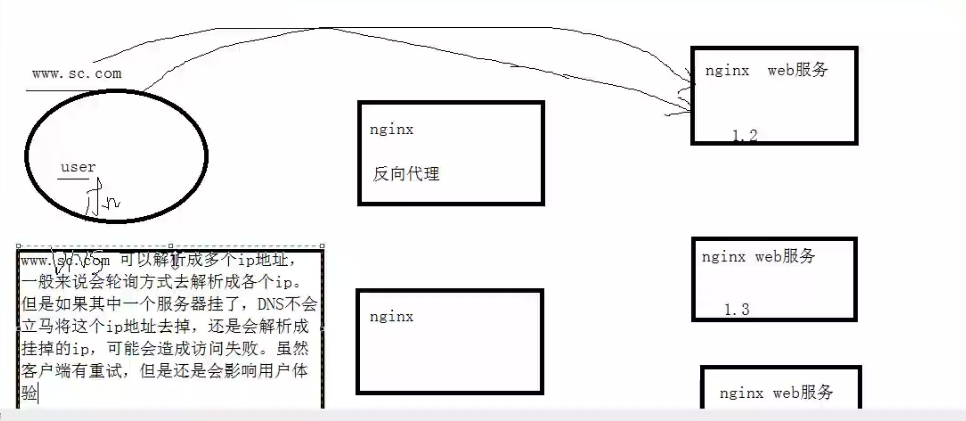
所以在应用web前面加反向代理。安全性也会高一点。负载均衡控制容易很多
DNS也可以做负载均衡,但是局限性很高。当其中的一个服务器挂掉时,DNS还是会解析到挂掉的服务器的ip地址上。
反向代理使用keepalived做高可用,双vip(虚拟ip)互为主备提高资源利用率
www.sc.com 解析成两个虚拟ip
正向代理:代理客户机 使用vpn就是正向代理
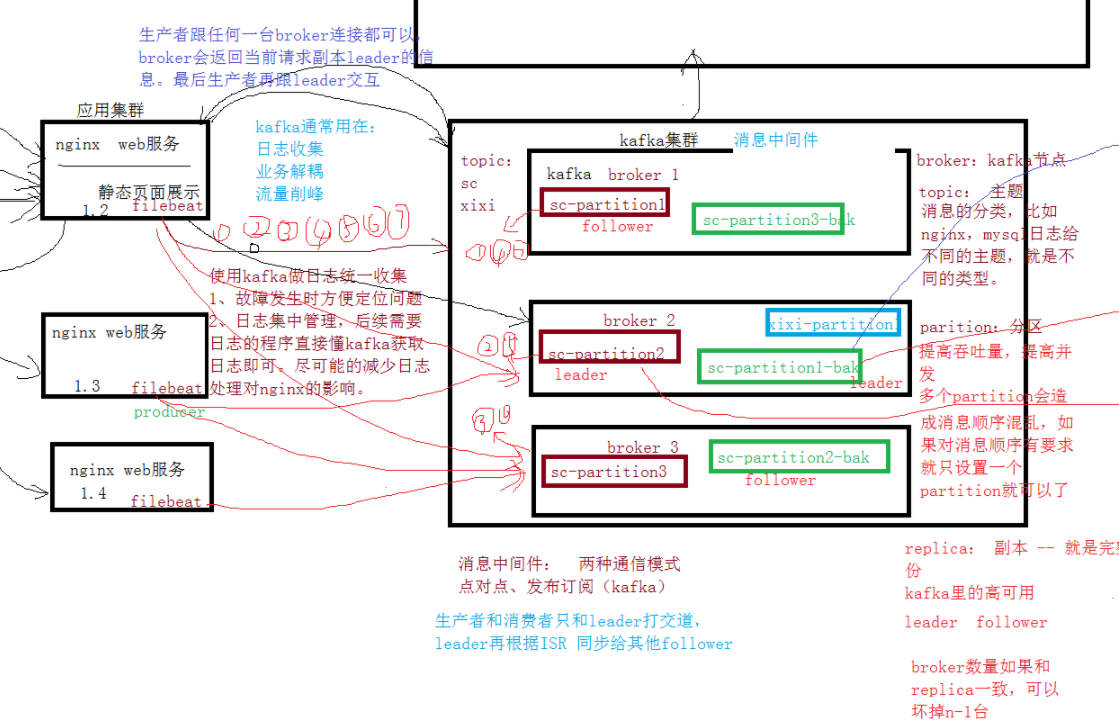
kafka
kafka集群
kafka的并发性非常好
broker:kafka的节点
==topic:==主题
消息的分类,比如nginx,mysql日志给不同的主题,就是不同的类型
partition:分区
提高并发,提高吞吐量,提高效率,一般跟broker数量相同
设置多个partition时,消息的顺序会被打乱,所以对消息顺序有要求时只设置一个partiton
replica:副本 – 就是完整的分区备份
kafka里的高可用
多个副本时,选取一个作为leader,其他的都是follower,生产者把消息同步给leader
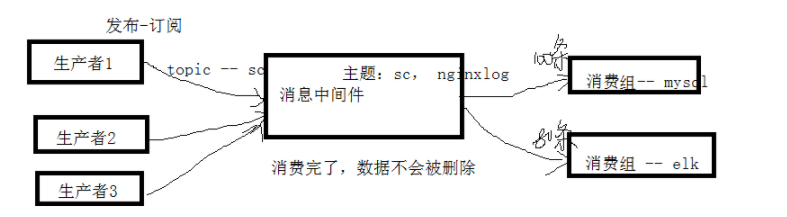
消息中间件
消息中间件有两种通信模式:点对点、发布订阅(kafka)
kafka就是一个消息中间件,kafka只支持发布订阅

/etc/hosts:本地的ip与域名映射服务
使用kafka的原因
- 数据库相通,但是日志文件不相通 => kafka方便定位故障
- 边缘服务影响主要业务 => 不要在主要业务的机器写别的程序影响运行 => kafka方便扩展其他功能、业务使用kafka做日志统一收集:
1、故障发生时方便定位问题
2、日志集中管理,后续需要日志的程序直接读kafka获取日志即可。尽可能的减少日志处理对nginx的影响
kafka通常用在:
日志收集
业务解耦:
业务解耦用于边缘业务和核心业务,降低耦合度,方便扩展
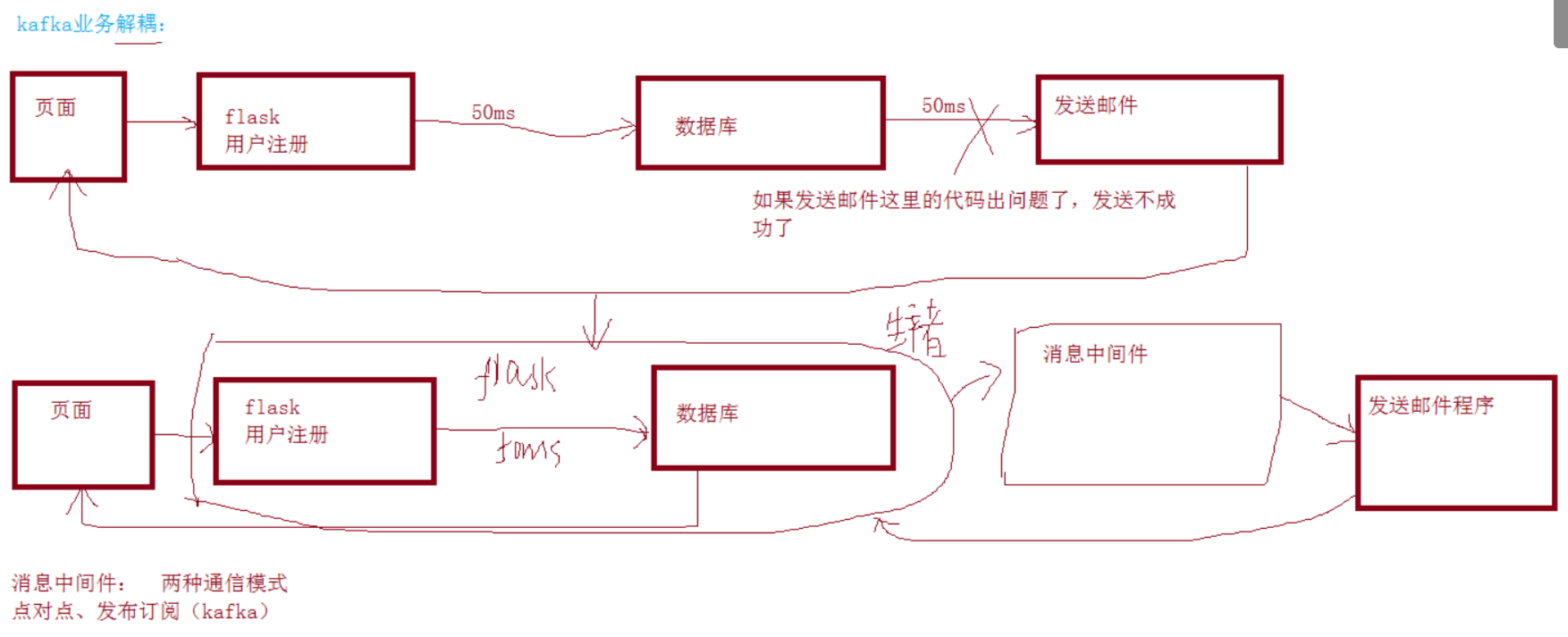
流量削峰
主要就是将缓存放入kafka中,再一个一个取出来
kafka是如何保证高可用的?
多个broker + 多个partition + 多个replica
broker数量(n)如果和replica数量一致,那么可以坏掉n-1台后还可以继续运行
ISR
in-sync-replica 列表集合 需要同步的follower集合
比如说5个副本,1个leader,4个follower —》ISR
有一条消息来了,leader怎么知道要同步哪些副本?
leader只会根据ISR来同步,如果一个follower挂掉了或者同步过慢,ISR就会把它删除;如果leader挂掉了,ISR就会重新选一个leader
如果有一个机器宕机,后续启动之后想要加入ISR,必须得同步到HW(最高水位线值),才能加入ISR
生产者和消费者值和leader打交道,leader再根据ISR同步给其他的follower
如何保证数据一致性?
1、producer可以通过request.required.acks设置,ack可以为0,1,-1
acks=0:生产者不会等待任何来自服务器的响应。
acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应
acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应
2、消费者消费数据时,引入了 High Water Mark 机制。木桶效应,只能消费ISR列表里偏移量最少的副本的消息数量。

因为replica2才同步到Message 1,所以消费者最多只能消费到Message 1
生产者
生产者跟任何一台broker连接都可以,broker会返回当前请求副本leader的信息。最后生产者再跟leader交互。
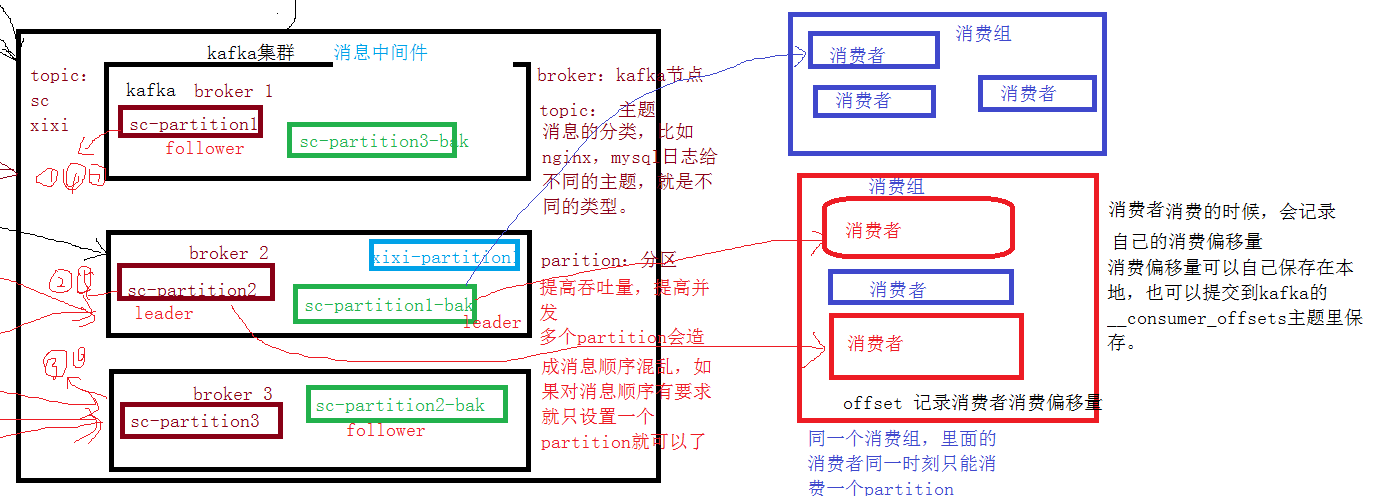
消费者
消费者可以组成一个消费组,同一个消费组中的消费者同一时间只能消费不同的partition,所以一般消费者的个数跟partion、broker一致。
消费者消费的时候,会记录自己的消费偏移量
消费偏移量可以自己保存在本地,也可以提交到kafka的__consumer_offsets主题里(kafka的配置文件指定的数据保存路径/data 可以查看)保存

查看kafka的数据保存路径:
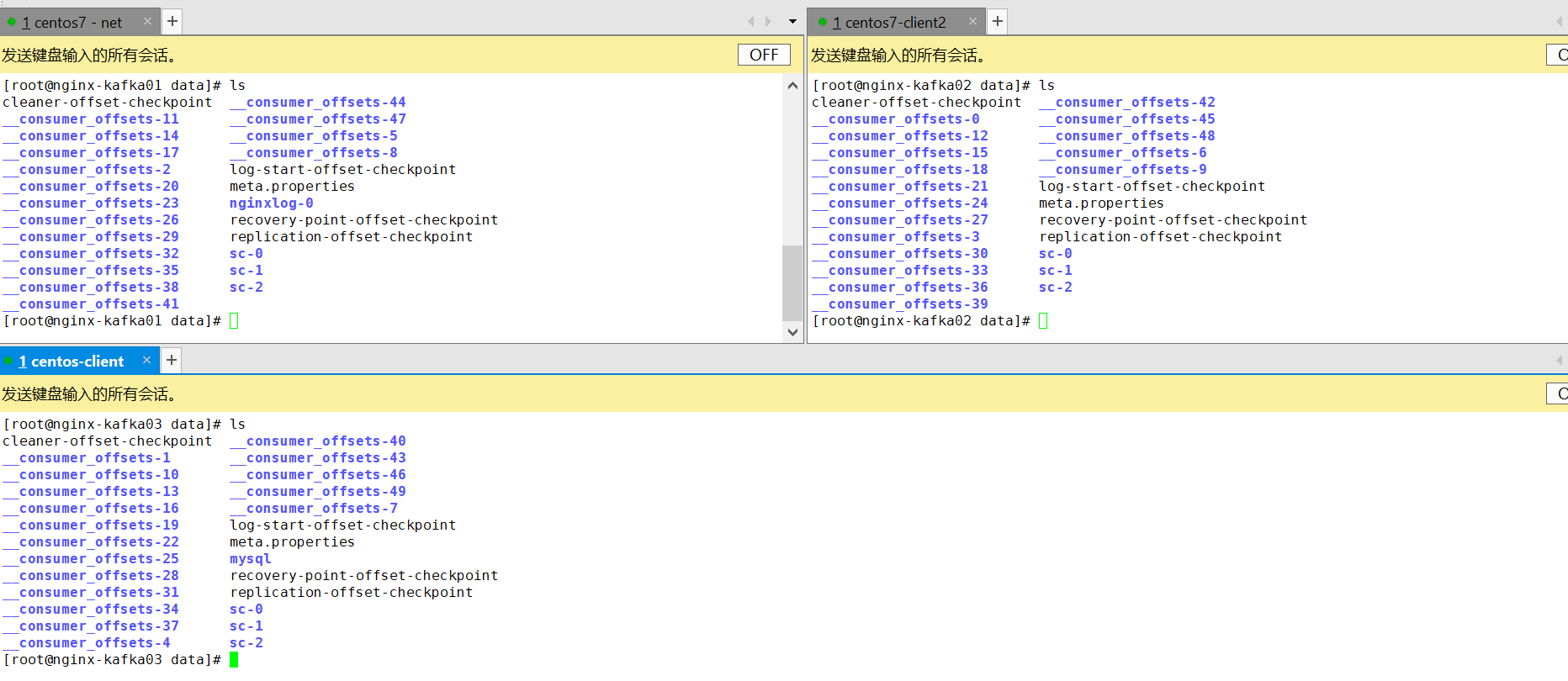
因为kafka指定了3个broker,所以每一个broker里面的偏移量都是不重复的
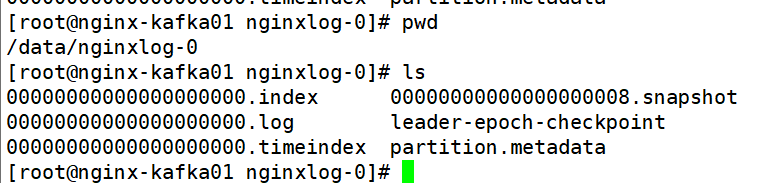
kafka的数据存储目录
文件夹:
-<分区> 每一个partition的数据都是由很多个segment存储,每一个segment由一个index和log文件组成。
分出多个segment便于做数据清理。
kafka可以按照两个维度清理数据:
1、按大小
2、按时间
任意一个条件满足,都可以触发日志清理
zookeeper
zk是分布式应用协调管理服务:配置管理、域名管理、分布式数据存储、集群管理
zookeeper中的选举
遵循一致性算法:zab
少数服从多数的原则,票数过半的当选为leader
zookeeper中的节点有n个,leader的票数应为>=n//2 + 1
zookeeper的数据同步
只要过半节点同步完成,就表示数据已经commit,zk中允许有节点的数据跟leader没有同步到,所以消费的zk节点可能会出现没有消息的情况。但是zookeeper中的每个节点数据量默认不超过1M,所以同步数据比较快。
zk不是强一致性,它属于最终一致性。
客户端连接任意一台zk都可以操作,但是数据新增修改等事物操作必须在leader上运行,客户端如果连接到follower上进行事物操作,follower会返回给leader的ip,最终客户端还是会在leader上操作。
zk的存活数量
zk集群中,节点存活数必须过半,集群才能正常使用,zk集群的节点数一般都设置为奇数,方便选举。
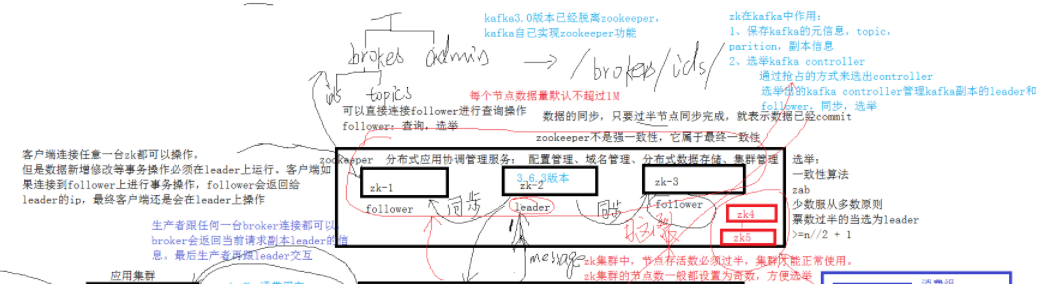
因为zk集群中的选举是少数服从多数的原则,如果因为网络原因将zk集群又划分为了两个集群,那么两个集群中又会分别重新选举leader,当网络恢复时,一个集群中就有两个leader了。为了避免这种情况的出现,只有节点存活数过半的集群才能正常使用,这样zk-1、zk-2、zk-3的集群就可以存活,zk-4、zk-5的集群不能存活下来。
zk在kafka中的作用
1、保存kafka的原信息:topic,partition,副本信息
2、选举 kafka controller。
通过抢占的方式来选出controller,选举出的kafka controller管理kafka副本的leader和follower,同步,选举
kafka3.0版本已经脱离zookeeper,kafka自己实现zookeeper功能
-
相关阅读:
设计模式-单例模式
Spring Security —漏洞防护—跨站请求伪造(CSRF)
通过Java Reflection实现编译时注解处理
Django 06
Win11怎么显示固定应用?
智慧楼宇3D数据可视化大屏交互展示实现了楼宇能源的高效、智能、精细化管控
七、stm32-TIM定时器(通用定时器中断)
基于SSM框架实现的房屋租赁管理系统
微服务·架构组件之网关
Windows11搭建FTP服务器后,无法访问,提示:ftp: connect :连接超时
- 原文地址:https://blog.csdn.net/liwenqianye/article/details/125902589