-
Kotlin协程分析(三)——理解协程上下文
协程上下文——CoroutineContext 是协程中很重要的环节,可以这么说,几乎整个协程的业务能力都是由它去完成的。
说实话,这段源码不是很好看,要具体解释出来也比较困难,如果在接下来的阅读过程中有任何疑惑,我们一起探讨学习。
一、简单介绍 CoroutineContext
协程上下文实际上是一个集合,里面可以放很多业务相关的 Context,例如:Job,用于控制协程任务的对象;Dispatcher,用于调度协程线程的对象。
在任意协程内,甚至包括挂起函数,都能够获取 coroutineContext,通过 get() 方法来获取具体的 Context 来进行业务。
二、CoroutineContext 的数据结构
了解其数据结构是很重要的一个环节,这样你才能看懂它的一些正常操作,例如之前出现过的:
context = SupervisorJob() + Dispatchers.Main是怎么回事,coroutineContext[Job]这又是做了什么事情?正如第一小节所说, CoroutineContext 是一个集合,那么这是怎样的一个集合呢?我们先看一下他的注释:
Persistent context for the coroutine. It is an indexed set of Element instances.
An indexed set is a mix between a set and a map. Every element in this set has a unique Key.翻译:这是一个元素为 Element 的集合,一个介于 set 和 map 之间的集合,任何一个 element 在该集合中有一个唯一 Key。
既然这是一个集合,我们直接阅读他的 “put” 和 get 方法:
1.“put”(进一步了解CoroutineContext的数据结构)
CoroutineContext 的 “put” 方法并不是直接 “put”,CoroutineContext 本身就是一个集合,在实现 “put” 时,它使用了一个小技巧——重写 “+号” 操作符:

1). 这个函数在加入新的 CoroutineContext 之后,会返回一个包含所有上下文的 CoroutineContext(这里需要对其理解,类似于链表/树的结节点)。2). 先判断要加入的 context 是否为 EmptyCoroutineContext,如果是空的 CoroutineContext,直接返回当前 CoroutineContext。
3). 如果加入的 context 不是 EmptyCoroutineContext,那么就调用
CoroutineContext.fold()进行 “折叠” 加入。4). 纵观所有
fold()函数的实现,总共有 3 处:EmptyCoroutineContext、Element 和 CombinedContext,到这里,我们就需要简单的看看这三类的相关函数源码了(别看多了,只看 fold 函数)。我们一个一个来分析:
1.1 EmptyCoroutineContext
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = initial- 1
这个是最好理解的,
EmptyCoroutineContext.fold(任意Context)=任意Context
即:EmptyCoroutineContext + 任意Context = 任意Context。1.2 Element
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = operation(initial, this)- 1
- 2
这个也很好理解,直接把 被foldConext 和 自己Context 放入 operation 中,看 operation 的操作。
即:Element + 任意Context = 任意Context.fold(Element) = { acc(自身Context),element(目标Context) -> return 操作之后的CoroutineContext }- 1
- 2
- 3
- 4
1.2 CombinedContext
关于 CombinedContext 我们就先不要看它的
fold()函数,先看名字:意思是组合(合二为一的)的Context,这就有点意思了,我们先看它的构造函数:internal class CombinedContext( private val left: CoroutineContext, private val element: Element ) : CoroutineContext, Serializable- 1
- 2
- 3
- 4
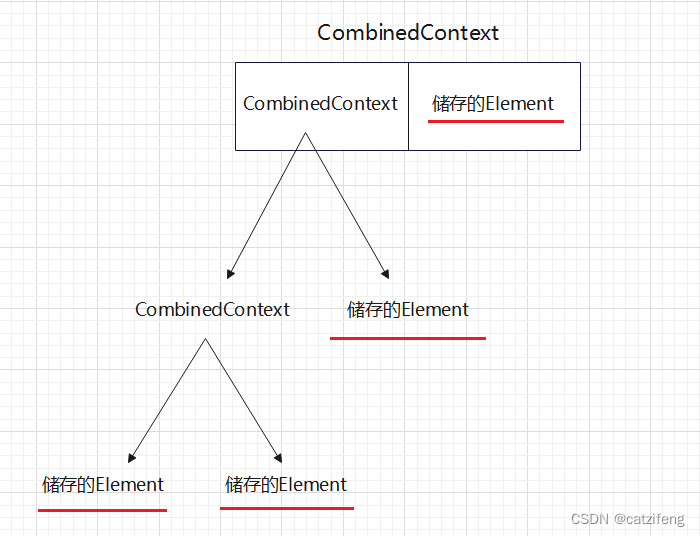
看注释,它说这是一个左向链表结构,包含了 left 的 CoroutineContext元素,和自己本身的 Element(Element继承于 CoroutineContext),看到这里实际上就差不多进一步了解了 CoroutineContext 的数据结构。
关于其
fold()函数,我们还是先不要看。现在我们先假设一个场景:任意Context(继承于 Element,下文称作自身Context) + 任意其他Context(继承于 Element,下文称作目标Context)会是怎样的流程?
结合源码和上面 1.2 Element相加是怎样的结果一起来分析,那么就会走 operation 里面的内容:
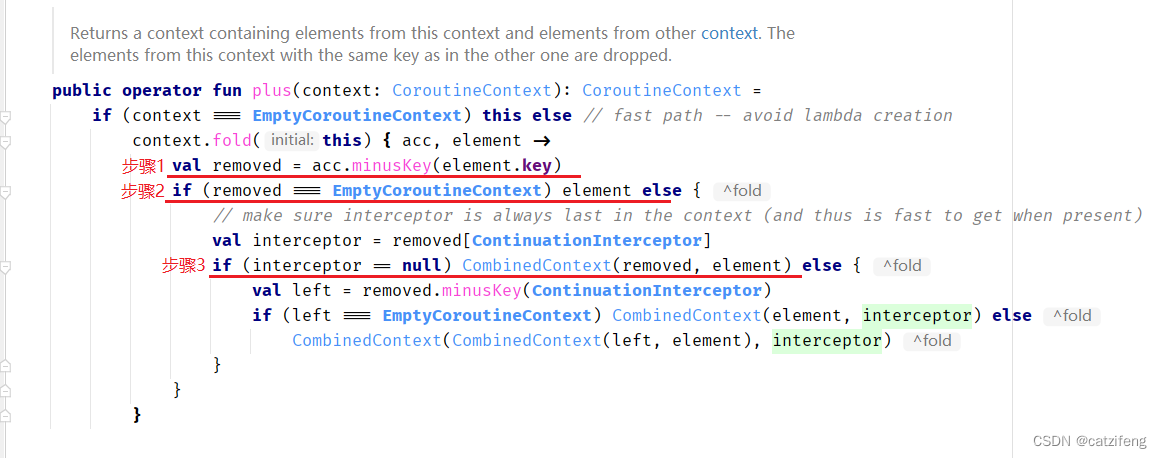
先看 operation 的两个参数分别是什么,acc == 自身Context,element == 目标Context步骤1:自身Context 移除掉目标Context,并且返回移除后的 CoroutineContext
步骤2:判断移除后的 CoroutineContext 是否为 EmptyCoroutineContext,如果为 EmptyCoroutineContext,那就直接返回 目标Context,这是什么意思呢?
假设自身Context 和目标Context 相等(Key相等),那么移除后的 CoroutineContext == EmptyCoroutineContext,所以就没有相加的必要了,直接返回目标Context。
假设自身Contxt 和目标Context 不相等,那么就来到下一个步骤
步骤3:先看上面的注释,说这段操作就是为了让一个名叫 ContinuationInterceptor 的Context能够始终在最后一个位置,方便快速获取,
这里我们假设目标Context和自身Context都没有包含 ContinuationInterceptor,那么 interceptor == null,
最后直接返回: CombinedContext(removed-移除目标Context之后的Context, element-目标Context)。
大伙们,源码读到这里,大家应该就已经很清楚了 CoroutineContext 的数据结构了吧,这里我来画一张图,更能清晰的表现出来(重点):
2.get
CoroutineContext 重写 “get操作符”:
public operator fun <E : Element> get(key: Key<E>): E?- 1
同样的也有好几处实现,分别是 Element、CombinedContext、EmptyCoroutineContext 和 ContinuationInterceptor,关于 ContinuationInterceptor 这里不作过多介绍,这和CoroutineContext 的数据结构无关,属具体CoroutineContext 的业务能力。
1.1 EmptyCoroutineContext
直接看源码:
public override fun <E : Element> get(key: Key<E>): E? = null- 1
因为本身就是代表着空的 CoroutineContext,所以直接返回 null。
1.2 Element
直接看源码:
public override operator fun <E : Element> get(key: Key<E>): E? = if (this.key == key) this as E else null- 1
- 2
作为元素本身,所以直接判断 key 是否相等,如果相等直接返回自身CoroutineContext。
1.3 CombinedContext
作为重要级的嘉宾,其源码还是很重要的:
override fun <E : Element> get(key: Key<E>): E? { var cur = this while (true) { cur.element[key]?.let { return it } val next = cur.left if (next is CombinedContext) { cur = next } else { return next[key] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我觉得看源码,再结合上面画的图应该很容易理解它查找的顺序吧。
-
相关阅读:
Python里的list是数组吗?
闰年计算-第13届蓝桥杯Scratch选拔赛真题精选
肌肉骨骼康复学-习题-单选
AI项目八:yolo5+Deepsort实现目标检测与跟踪(CPU版)
Choose the WiFi card that suits you: QCA9882 vs. MT7915/QCN6024
你接受不了60%的暴跌,就没有资格获得6000%的涨幅 2021-05-27
一文了解微服务低代码实现方式
Linux内核的配置和编译(3)——Linux内核加载自己的驱动(编译最新内核Linux-5.18.7)
金九银十进大厂必刷的Java面试题 (全彩版)
springboot+websocket+vue聊天室
- 原文地址:https://blog.csdn.net/catzifeng/article/details/124019166
{kind=link}