-
采用混合搜索策略的阿奎拉优化算法
一、理论基础
1、AO算法
请参考这里。
2、HAO算法
(1)动态调整
固定的探索与开发概率容易导致搜索之间的不平衡,进而降低算法的搜索效率。AO算法中不难看出,算法在执行探索步骤与开发步骤之间缺乏信息交流,导致探索与开发各自为政,探索与开发之间存在严重不平衡。为了克服这一缺陷,通过一种震荡变化的函数作为切换探索与开发之间的动态调整概率系数。动态调整的函数如式(1)所示,其中动态调整函数变化曲线,如图1所示。 r ( t ) = ( exp ( − 5 t / T ) × cos ( 5 t ) + l ) / 2 (1) r(t)=(\exp(-5t/T)\times\cos(5t)+l)/2\tag{1} r(t)=(exp(−5t/T)×cos(5t)+l)/2(1)其中 l = 1 l=1 l=1,当 r ( t ) < 0.5 r(t)<0.5 r(t)<0.5时,其值变换为 1 − r ( t ) 1-r(t) 1−r(t)。在改进算法中通过 r a n d ≤ r ( t ) rand\leq r(t) rand≤r(t)动态切换全局探索步骤与局部开发步骤,基于一般元启发式算法普遍采用“算法在搜索前期侧重进行全局探索、在后期侧重开展局部开发”搜索策略原则,HAO算法也遵循这一原则。从图1可以看出, r ( t ) r(t) r(t)的值在迭代前期表现为远离数值0.5波动变化,随着迭代次数的增加, r ( t ) r(t) r(t)值的波动幅度逐渐靠近数值0.5,最后 r ( t ) r(t) r(t)在数值0.5附近波动变化,算法在前期 r ( t ) r(t) r(t)的值大于 r a n d rand rand的概率大,在前期执行全局探索的概率较大,随着迭代次数的增加, r ( t ) r(t) r(t)波动数值减小,局部开发的概率逐渐增加,最后,全局探索与局部开发的执行概率为一种动态平衡。
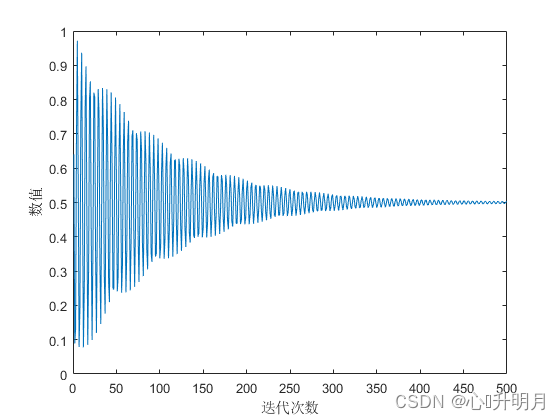
图1 动态调整函数变化曲线 (2)混沌自适应权重
较大的惯性权重有利于算法的探索行为,较小的惯性权重有利于算法的开发行为。为此,设计一种非线性递减的惯性权重,并引入 l o g i s t i c logistic logistic混沌系数的混沌自适应权重。混沌自适应权重的公式如式(2)所示,混沌自适应权重的变化曲线如图2所示。 w ( t ) = z ( t ) × w 1 − ( w 1 − w 2 ) × ( 2 t / T − ( t / T ) 2 ) (2) w(t)=z(t)\times w_1-(w_1-w_2)\times(2t/T-(t/T)^2)\tag{2} w(t)=z(t)×w1−(w1−w2)×(2t/T−(t/T)2)(2) z ( t ) = a × z ( t − 1 ) × ( 1 − z ( t − 1 ) ) (3) z(t)=a\times z(t-1)\times(1-z(t-1))\tag{3} z(t)=a×z(t−1)×(1−z(t−1))(3)其中, w 1 = 0.9 w_1=0.9 w1=0.9, w 2 = 0.4 w_2=0.4 w2=0.4, a = 3 a=3 a=3, z ( t ) z(t) z(t)表示 l o g i s t i c logistic logistic混沌系数。从图2可以看出混沌自适应权重的变化曲线整体上是非线性递减,这样的策略既使得算法在前期有着高效的探索效率,加快算法目标收敛区域的确定,在算法后期又能提升算法开发效率,快速确定目标位置,提升算法收敛速度。引入混沌自适应权重之后 ,其位置更新公式分别如式(4)(5)(6)(7)所示。 X ( t + 1 ) = w ( t ) × X b e s t ( t ) × ( 1 − t / T ) + ( X M ( t ) − r a n d ∗ X b e s t ( t ) ) (4) X(t+1)=w(t)\times X_{best}(t)\times(1-t/T)+(X_M(t)-rand^*X_{best}(t))\tag{4} X(t+1)=w(t)×Xbest(t)×(1−t/T)+(XM(t)−rand∗Xbest(t))(4) X ( t + 1 ) = w ( t ) × X b e s t ( t ) × l e v y ( D ) + X R ( t ) + r a n d ∗ ( y − x ) (5) X(t+1)=w(t)\times X_{best}(t)\times levy(D)+X_R(t)+rand^*(y-x)\tag{5} X(t+1)=w(t)×Xbest(t)×levy(D)+XR(t)+rand∗(y−x)(5) X ( t + 1 ) = w ( t ) × ( X b e s t ( t ) − X M ( t ) ) × α − r a n d + ( ( U B − L B ) × r a n d + L B ) + δ (6) X(t+1)=w(t)\times(X_{best}(t)-X_M(t))\times\alpha-rand+((UB-LB)\times rand+LB)+\delta\tag{6} X(t+1)=w(t)×(Xbest(t)−XM(t))×α−rand+((UB−LB)×rand+LB)+δ(6) X ( t + 1 ) = w ( t ) × Q F ( t ) × X b e s t ( t ) − ( G 1 × X ( t ) × r a n d ) − G 2 × l e v y ( D ) + r a n d × G 1 (7) X(t+1)=w(t)\times QF(t)\times X_{best}(t)-(G_1\times X(t)\times rand)-G_2\times levy(D)+rand\times G_1\tag{7} X(t+1)=w(t)×QF(t)×Xbest(t)−(G1×X(t)×rand)−G2×levy(D)+rand×G1(7)
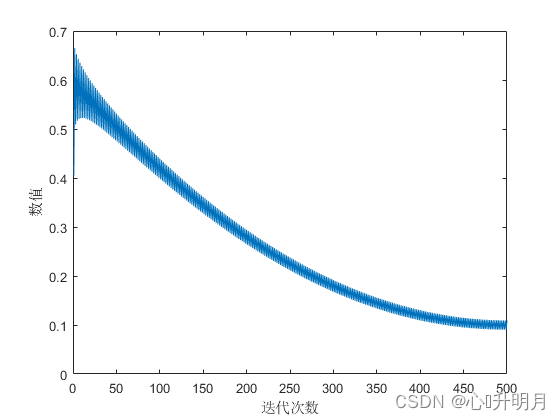
图2 混沌自适应权重变化曲线 (3)改进型差分变异策略
提升种群多样性是算法避免陷入局部最优的关键所在。利用改进型差分变异策略,对种群中非最优个体进行变异操作,以此增加种群的多样性,增强算法跳出局部最优的能力。
a)变异概率系数的设计。本文主要对非最优个体进行变异操作,采用传统的固定变异概率系数具有一定的随机性与盲目性。因此,本文设计一种新的变异概率系数,其具有明确的指向性,使变异向有助于算法收敛的方向进行,进而加快算法的收敛。其变异概率系数如式(8)所示。 p ( i ) = { 0 , f i t i = f i t min 0.3 ( f i t i − f i t min ) f i t max − f i t min , f i t i < ( f i t max + f i t min ) / 2 0.3 , f i t i ≥ ( f i t max + f i t min ) / 2 (8) p(i)=\tag{8} p(i)=⎩ ⎨ ⎧0,fiti=fitminfitmax−fitmin0.3(fiti−fitmin),fiti<(fitmax+fitmin)/20.3,fiti≥(fitmax+fitmin)/2(8)其中, p ( i ) p(i) p(i)表示第 i i i个个体的变异概率, f i t i fit_i fiti表示第 i i i个个体的适应度值, f i t min fit_{\min} fitmin表示群体中最小适应度值, f i t max fit_{\max} fitmax表示群体的最大适应度值,当个体的变异概率 r a n d < p ( i ) rand\begin{dcases}0,\quad\quad\quad\quad\quad\quad\quad\quad\, fit_i=fit_{\min}\\[2ex]\frac{0.3(fit_i-fit_{\min})}{fit_{\max}-fit_{\min}},\quad fit_i<(fit_{\max}+fit_{\min})/2\\[2ex]0.3,\quad\quad\quad\quad\quad\quad\quad\,\, fit_i\geq(fit_{\max}+fit_{\min})/2\end{dcases}
b)变异操作。本文采用改进型差分变异策略进行变异操作,以提升算法的多样性。差分变异方法主要有:DE/rand/1、DE/rand/2 、 DE/best/1 、 DE/best/2 、 DE/current-to-rand/1 、DE/current-to-best/1等。本文选取DE/best/2并加以改进,然后将其用于AO的变异操作。DE/best/2变异公式如式(9)所示。 X ( t + 1 ) = X b e s t ( t ) + F × ( X r 1 ( t ) − X r 2 ( t ) ) + F × ( X r 3 ( t ) − X r 4 ( t ) ) (9) X(t+1)=X_{best}(t)+F\times(X_{r1}(t)-X_{r2}(t))+F\times(X_{r3}(t)-X_{r4}(t))\tag{9} X(t+1)=Xbest(t)+F×(Xr1(t)−Xr2(t))+F×(Xr3(t)−Xr4(t))(9)其中, X b e s X_{bes} Xbes为群体当前最优个体, X r 1 X_{r1} Xr1、 X r 2 X_{r2} Xr2、 X r 3 X_{r3} Xr3、 X r 4 X_{r4} Xr4为种群中的随机个体, F F F为比例因子,为0到1之间的随机数。本文对式(9)作如下改进(见式(10)): X n e w ( t + 1 ) = X α ( t ) + X β ( t ) + X δ ( t ) 3 + F × sgn ( m 1 ) × ( X r 1 ( t ) − X r 2 ( t ) ) + F × sgn ( m 2 ) × ( X r 3 ( t ) − X r 4 ( t ) ) (10) X_{new}(t+1)=\frac{X_\alpha(t)+X_\beta(t)+X_\delta(t)}{3}+F\times\text{sgn}(m1)\times(X_{r1}(t)-X_{r2}(t))\\[2ex]+F\times\text{sgn}(m2)\times(X_{r3}(t)-X_{r4}(t))\tag{10} Xnew(t+1)=3Xα(t)+Xβ(t)+Xδ(t)+F×sgn(m1)×(Xr1(t)−Xr2(t))+F×sgn(m2)×(Xr3(t)−Xr4(t))(10) m 1 = f i t ( X r 1 ( t ) ) − f i t ( X r 2 ( t ) ) , m 2 = f i t ( X r 3 ( t ) ) − f i t ( X r 4 ( t ) ) (11) m1=fit(X_{r1}(t))-fit(X_{r2}(t)),m2=fit(X_{r3}(t))-fit(X_{r4}(t))\tag{11} m1=fit(Xr1(t))−fit(Xr2(t)),m2=fit(Xr3(t))−fit(Xr4(t))(11)其中, f i t ( X ) fit(X) fit(X)表示 X X X的适应度值, sgn ( ⋅ ) \text{sgn}(\cdot) sgn(⋅)为符号函数。式(10)首先将 X b e s t X_{best} Xbest改为种群中个体适应度前三个体的均值。通过适应度前三个体进行引导,个体的更新将不会盲目的趋向最优个体附近,且个体的分布在搜索空间将更加灵活,从而整个种群的多样性将会得到改善,种群多样性增加有利于算法跳出局部最优,从而提升算法的收敛精度;其次,在扰动项上增加符号函数,利用随机个体的适应度信息来增强扰动项的离散性,个体的更新将更加灵活,种群多样性进一步得到改善。通过式(10)变异后的 X n e w X_{new} Xnew与当前个体进行适应度值对比,如果变异后适应度值更优,则保留变异个体。(4)HAO算法流程
综上所述,HAO算法执行的流程如图3所示。
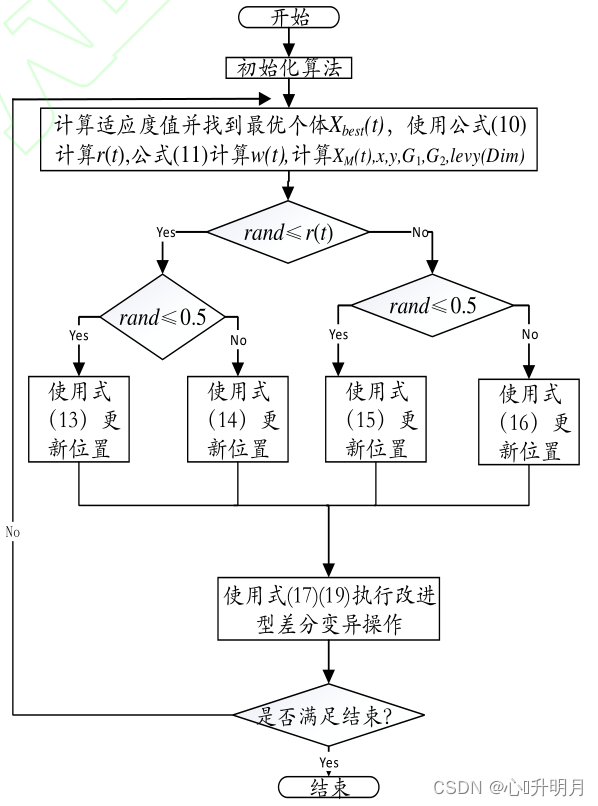
图3 HAO算法流程图 二、仿真实验与结果分析
将HAO与AO、SOA、AOA和HHO进行对比,以文献[1]中表1的8个测试函数为例,实验设置种群规模为30,最大迭代次数为500,每种算法独立运算30次,结果显示如下:
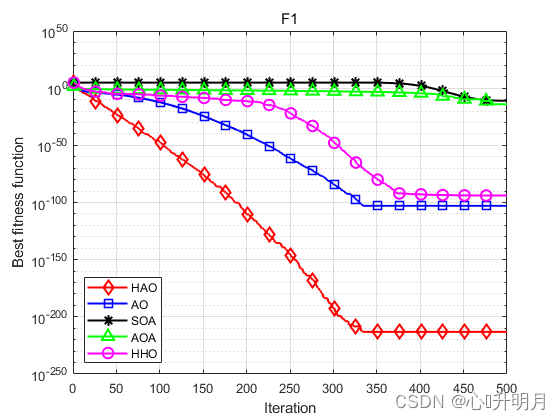
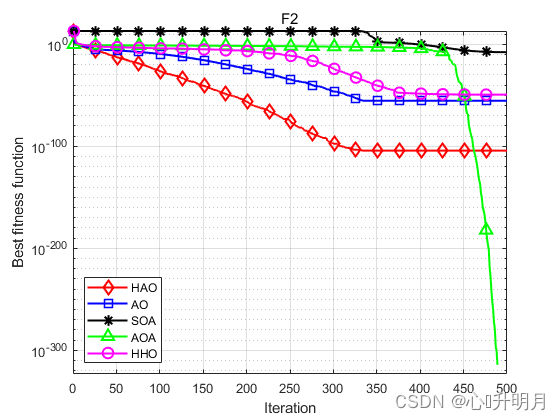
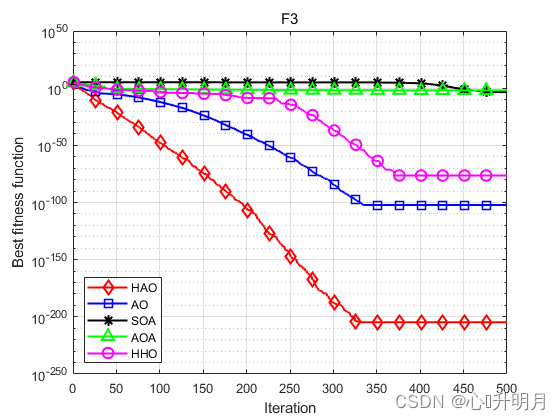
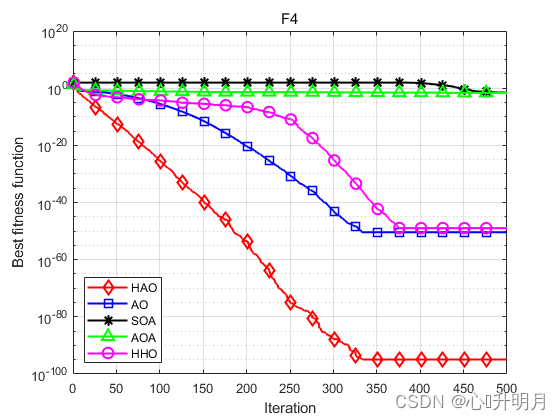
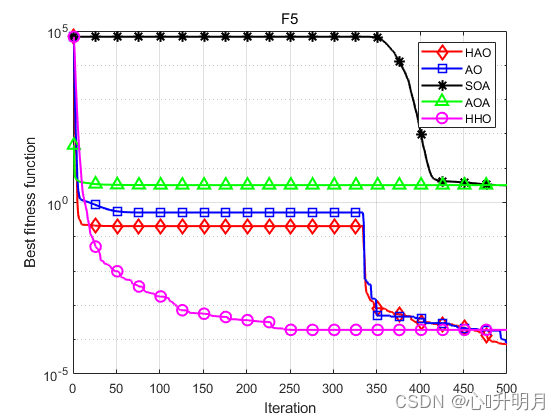
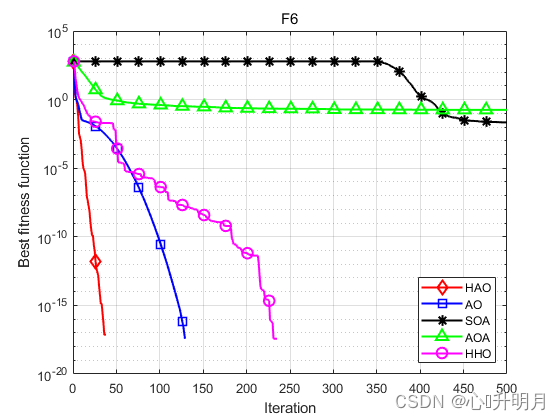
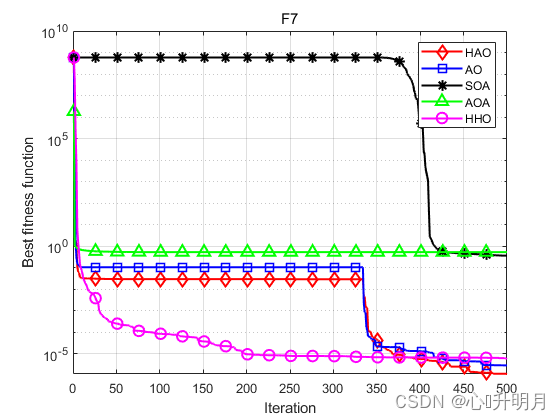
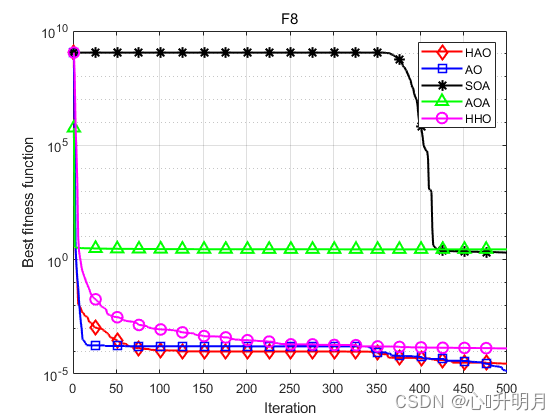
函数:F1 HAO:最差值:2.2583e-212,最优值:6.4617e-279,平均值:7.5795e-214,标准差:0,秩和检验:1 AO:最差值:3.6817e-102,最优值:1.2496e-158,平均值:1.2689e-103,标准差:6.7178e-103,秩和检验:3.0199e-11 SOA:最差值:3.4828e-11,最优值:3.1647e-14,平均值:8.5622e-12,标准差:1.0596e-11,秩和检验:3.0199e-11 AOA:最差值:2.3172e-13,最优值:2.2368e-136,平均值:8.6958e-15,标准差:4.2457e-14,秩和检验:3.0199e-11 HHO:最差值:3.0736e-93,最优值:2.8838e-113,平均值:1.2488e-94,标准差:5.6336e-94,秩和检验:3.0199e-11 函数:F2 HAO:最差值:1.6886e-103,最优值:1.1609e-141,平均值:5.6287e-105,标准差:3.0829e-104,秩和检验:1 AO:最差值:1.3712e-54,最优值:1.6531e-78,平均值:4.5708e-56,标准差:2.5035e-55,秩和检验:3.0199e-11 SOA:最差值:6.8491e-08,最优值:1.1122e-09,平均值:1.6246e-08,标准差:1.5762e-08,秩和检验:3.0199e-11 AOA:最差值:0,最优值:0,平均值:0,标准差:0,秩和检验:1.2118e-12 HHO:最差值:7.2555e-49,最优值:1.7732e-60,平均值:3.9513e-50,标准差:1.5065e-49,秩和检验:3.0199e-11 函数:F3 HAO:最差值:5.8352e-204,最优值:2.1433e-273,平均值:1.9451e-205,标准差:0,秩和检验:1 AO:最差值:1.9062e-101,最优值:9.3269e-156,平均值:6.3539e-103,标准差:3.4802e-102,秩和检验:3.0199e-11 SOA:最差值:0.0083859,最优值:2.7631e-07,平均值:0.00034351,标准差:0.0015222,秩和检验:3.0199e-11 AOA:最差值:0.056385,最优值:4.5756e-103,平均值:0.01053,标准差:0.017227,秩和检验:3.0199e-11 HHO:最差值:9.3006e-76,最优值:7.5776e-96,平均值:4.156e-77,标准差:1.7748e-76,秩和检验:3.0199e-11 函数:F4 HAO:最差值:3.4183e-94,最优值:8.7216e-143,平均值:1.1401e-95,标准差:6.2409e-95,秩和检验:1 AO:最差值:8.2826e-50,最优值:5.7737e-82,平均值:3.9266e-51,标准差:1.6198e-50,秩和检验:3.0199e-11 SOA:最差值:0.52732,最优值:8.2512e-05,平均值:0.028393,标准差:0.099327,秩和检验:3.0199e-11 AOA:最差值:0.052154,最优值:7.0346e-66,平均值:0.0225,标准差:0.020262,秩和检验:3.0199e-11 HHO:最差值:1.3474e-48,最优值:6.6686e-58,平均值:1.0442e-49,标准差:3.3477e-49,秩和检验:3.0199e-11 函数:F5 HAO:最差值:0.00057547,最优值:1.2209e-20,平均值:7.2897e-05,标准差:0.00012585,秩和检验:1 AO:最差值:0.00040602,最优值:1.3353e-07,平均值:8.2005e-05,标准差:0.00010515,秩和检验:0.27719 SOA:最差值:3.9717,最优值:2.2187,平均值:3.157,标准差:0.49098,秩和检验:3.0199e-11 AOA:最差值:3.6751,最优值:2.6408,平均值:3.2086,标准差:0.2593,秩和检验:3.0199e-11 HHO:最差值:0.00076521,最优值:2.8978e-07,平均值:0.00019343,标准差:0.000238,秩和检验:0.032651 函数:F6 HAO:最差值:0,最优值:0,平均值:0,标准差:0,秩和检验:NaN AO:最差值:0,最优值:0,平均值:0,标准差:0,秩和检验:NaN SOA:最差值:0.13894,最优值:1.8563e-13,平均值:0.02163,标准差:0.035302,秩和检验:1.2118e-12 AOA:最差值:0.59786,最优值:0.0098399,平均值:0.18008,标准差:0.15527,秩和检验:1.2118e-12 HHO:最差值:0,最优值:0,平均值:0,标准差:0,秩和检验:NaN 函数:F7 HAO:最差值:5.5292e-06,最优值:3.6926e-10,平均值:1.1636e-06,标准差:1.6196e-06,秩和检验:1 AO:最差值:2.1551e-05,最优值:5.7119e-08,平均值:2.9172e-06,标准差:4.7847e-06,秩和检验:0.021506 SOA:最差值:0.81435,最优值:0.18961,平均值:0.36473,标准差:0.15645,秩和检验:3.0199e-11 AOA:最差值:0.63,最优值:0.43692,平均值:0.53116,标准差:0.041229,秩和检验:3.0199e-11 HHO:最差值:2.2475e-05,最优值:1.2639e-08,平均值:5.8567e-06,标准差:6.2317e-06,秩和检验:0.00020058 函数:F8 HAO:最差值:0.00051771,最优值:3.7389e-10,平均值:2.8387e-05,标准差:9.3468e-05,秩和检验:1 AO:最差值:9.1412e-05,最优值:4.5631e-08,平均值:1.3187e-05,标准差:1.9221e-05,秩和检验:0.95873 SOA:最差值:2.2585,最优值:1.5947,平均值:2.0366,标准差:0.17433,秩和检验:3.0199e-11 AOA:最差值:2.9979,最优值:2.5728,平均值:2.8355,标准差:0.12468,秩和检验:3.0199e-11 HHO:最差值:0.00044877,最优值:9.5859e-07,平均值:0.00013127,标准差:0.00014729,秩和检验:9.7917e-05- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
实验结果表明:HAO算法在优化精度、收敛速度方面得到了明显地提升,且跳出局部最优的能力得到了增强。
三、参考文献
[1] 付小朋, 王勇, 冯爱武. 采用混合搜索策略的阿奎拉优化算法[J/OL]. 计算机应用研究: 1-8 [2022-07-18].
-
相关阅读:
认识3dmax 轴心
JVM(八股文)
Web前端—小兔鲜儿电商网站底部设计及网站中间过渡部分设计
C++ 不知图系列之基于链接表的无向图最短路径搜索
RHCSA认证考试---12.查找字符串
AJAX学习(四)
ES 11 新特性
java中的this引用和对象的构造及初始化
计算机网络 —— 运输层
MySQL的结构化语言 DDL DML DQL DCL
- 原文地址:https://blog.csdn.net/weixin_43821559/article/details/125846814