-
SpringCloud
🏳️🌈个人网站:code宝藏 👈,欢迎访问
🎉我的公众号:code宝藏 👨💻,分享自己的学习资源,欢迎关注🌻
🤝非常感谢大家的支持与点赞👍
📚笔记整理自动力节点最新SpringCloud视频教学微服务
什么是微服务
就是将一个大的应用,拆分成多个小的模块,每个模块都有自己的功能和职责,每个模块可以 进行交互,这就是微服务
微服务架构的风格,就是将单一程序开发成一个微服务, 每个微服务运行在自己的进程中,并使用轻量级通信机制,通常是 HTTP RESTFUL API 。这些服务围绕业务能力来划分构建的,并通过完全自动化部署机制来独立部署这些服务可以使用不同的编程语言,以及不同数据存储技术,以保证最低限度的集中式管理
优势
- 服务按照业务拆分,编码也是按照业务来拆分,代码的可读性和可扩展性增加。
- 由于微服务系统是分布式系统,服务与服务之间没有任何的耦合。随着业务的增加,可以根据业务再拆分服务,具有极强的横向扩展能力。随着应用的用户量的增加,井发量增加,可以将微服务集群化部署,从而增加系统的负载能力。
- 微服务的每个服务单元都是独立部署的,即独立运行在某个进程里。微服务的修改和部署对其他服务没有影响。
- 微服务在 CAP 理论中采用的是 AP 架构,即具有高可用和分区容错的特点。
CAP 原则又称 CAP 定理,指的是在一个分布式系统中,
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)(这个特性是不可避免的)
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
缺点
- 微服务的复杂度
- 分布式事务问题
- 服务的划分(按照功能划分 还是按照组件来划分呢) 分工
- 服务的部署(不用自动化部署 自动化部署)
SpringCloud
SpringCloud 就是微服务理念的一种具体落地实现方式,帮助微服务架构提供了必备的功能
常用组件
- 服务的注册和发现。(eureka,nacos,consul)
- 服务的负载均衡。(ribbon,dubbo)
- 服务的相互调用。(openFeign,dubbo)
- 服务的容错。(hystrix,sentinel)
- 服务网关。(gateway,zuul)
- 服务配置的统一管理。(config-server,nacos,apollo)
- 服务消息总线。(bus)
- 服务安全组件。(security,Oauth2.0)
- 服务监控。(admin) (jvm)
- 链路追踪。(sleuth+zipkin)
Eureka
注册发现中心,提供了让别人注册的功能,类似于zookeeper
Spring Cloud Eureka 和 Zookeeper 的区别
- Zookeeper 注重数据的一致性
- Eureka注重服务的可用性
概念
服务的注册
当项目启动时(eureka 的客户端),就会向 eureka-server 发送自己的元数据(原始数据) (运行的 ip,端口 port,健康的状态监控等,因为使用的是 http/ResuFul 请求风格), eureka-server 会在自己内部保留这些元数据(内存中)。
服务的续约
项目启动成功了,除了向 eureka-server 注册自己成功,还会定时的向 eureka-server 汇报自己,心跳,表示自己还活着。
服务的下线(主动下线)
当项目关闭时,会给 eureka-server 报告,说明自己要下机
服务的剔除(被动下线,主动剔除)
当项目超过了指定时间没有向 eureka-server 汇报自己,那么 eureka-server 就会认为此 节点死掉了,会把它剔除掉,也不会放流量和请求到此节点了
搭建Eureka-server
引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.3.12.RELEASEversion> <relativePath/> parent> <groupId>com.powernodegroupId> <artifactId>eureka-serverartifactId> <version>0.0.1-SNAPSHOTversion> <name>01-eureka-servername> <description>Demo project for Spring Bootdescription> <properties> <java.version>1.8java.version> <spring-cloud.version>Hoxton.SR12spring-cloud.version> properties> <dependencies> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-netflix-eureka-serverartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-dependenciesartifactId> <version>${spring-cloud.version}version> <type>pomtype> <scope>importscope> dependency> dependencies> dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-maven-pluginartifactId> plugin> plugins> build> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
修改启动类
@SpringBootApplication @EnableEurekaServer // 开启eureka的注册中心的功能 public class EurekaServerApplication { public static void main(String[] args) { SpringApplication.run(EurekaServerApplication.class, args); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改配置文件
server: port: 8762 spring: application: name: eureka-server # 应用名称不能改 eureka: client: service-url: defaultZone: http://peer1:8761/eureka,http://peer3:8763/eureka instance: # 实例的配置 instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} # 主机名称 : 应用名称 : 端口号 hostname: peer2 # 主机名称 或者服务的ip prefer-ip-address: true # 以ip的形式显示具体的服务信息 lease-renewal-interval-in-seconds: 5 # 服务实例的续约的时间间隔- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
然后就可以访问http://localhost:8762
搭建Eureka-client
引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <parent> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-parentartifactId> <version>2.3.12.RELEASEversion> <relativePath/> parent> <groupId>com.powernodegroupId> <artifactId>eureka-client-bartifactId> <version>0.0.1-SNAPSHOTversion> <name>02-eureka-client-bname> <description>Demo project for Spring Bootdescription> <properties> <java.version>1.8java.version> <spring-cloud.version>Hoxton.SR12spring-cloud.version> properties> <dependencies> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-netflix-eureka-clientartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-dependenciesartifactId> <version>${spring-cloud.version}version> <type>pomtype> <scope>importscope> dependency> dependencies> dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-maven-pluginartifactId> plugin> plugins> build> project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
修改启动类
@SpringBootApplication @EnableEurekaClient // 开启客户端的功能 public class EurekaClientAApplication { public static void main(String[] args) { SpringApplication.run(EurekaClientAApplication.class, args); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改配置文件
server: port: 8080 # 客户端的端口没有要求 spring: application: name: eureka-client-a # 注册的含义是什么? 就是将自己的一些信息(什么信息ip port...) 发送过去 (发到哪里) eureka: client: # 客户端的相关配置 service-url: # 指定注册的地址 defaultZone: http://localhost:8761/eureka register-with-eureka: true # 可以不往eureka-server注册 fetch-registry: true # 应用是否去拉去服务列表到本地 registry-fetch-interval-seconds: 10 # 为了缓解服务列表的脏读问题 时间越短脏读越少 性能消耗大 instance: hostname: localhost # 应用的主机名称 最好写主机ip instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port} prefer-ip-address: true # 显示ip lease-renewal-interval-in-seconds: 10 # 示例续约的时间- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Ribbon
概述
主要功能是提供客户端负载均衡算法和 服务调用。Ribbon 客户端组件提供了一套完善的配置项,比如连接超时,重试等。
在 Spring Cloud 构建的微服务系统中, Ribbon 作为服务消费者的负载均衡器,有两种使用方式,一种是和 RestTemplate 相结合,另一种是和 OpenFeign相结合
Ribbon 负载均衡的实现和几种算法
-
RoundRobinRule–轮询 请求次数 % 机器数量
-
RandomRule–随机
-
权重
-
iphash
-
AvailabilityFilteringRule --会先过滤掉由于多次访问故障处于断路器跳闸状态的服 务,还有并发的连接数量超过阈值的服务,然后对于剩余的服务列表按照轮询的策略进行访问
-
WeightedResponseTimeRule–根据平均响应时间计算所有服务的权重,响应时间越快服 务权重越大被选中的概率越大。刚启动时如果同统计信息不足,则使用轮询的策略,等统计信 息足够会切换到自身规则
-
RetryRule-- 先按照轮询的策略获取服务,如果获取服务失败则在指定的时间内会进行重 试,获取可用的服务
-
BestAvailableRule --会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后 选择一个并发量小的服务
-
ZoneAvoidanceRule – 默认规则,复合判断 Server 所在区域的性能和 Server 的可用 行选择服务器。
Ribbon 默认使用哪一个负载均衡算法:
ZoneAvoidanceRule :区间内亲和轮询的算法!通过一个 key 来区分
OpenFeign
概述
Feign 是声明性(注解)Web 服务客户端。Feign 是一个远程调用的组件 (接口,注解)
使用
引入依赖
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-openfeignartifactId> dependency>- 1
- 2
- 3
- 4
创建接口
/** * @Author: 动力节点 * * @FeignClient 声明是 feign 的调用 * value = "provider-order-service" value 后面的值必须和提供者的服 务名一致 */ @FeignClient(value = "provider-order-service") public interface UserOrderFeign { /** * 描述: 下单的方法 这里的路径必须和提供者的路径一致 * * @param : * @return java.lang.String */ @GetMapping("doOrder") String doOrder(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
直接调用doOrder()方法即可,它会查找provider-order-service 这个应用中方法路径为doOrder的方法进行调用
方法签名
Feign 传参确保消费者和提供者的参数列表一致 包括返回值 方法签名要一致
- 通过 URL 传参数,GET 请求,参数列表使用@PathVariable
- 如果是 GET 请求,每个基本参数必须加@RequestParam
- 如果是 POST 请求,而且是对象集合等参数,必须加@Requestbody 或者@RequestParam
时间日期问题
使用 feign 远程调用时,传递 Date 类型,接收方的时间会相差 14 个小时,是因为时区造成 的
处理方案:
-
使用字符串传递参数,接收方转换成时间类型(推荐使用)不要单独传递时间
-
使用 JDK8 的 LocalDate(日期) 或 LocalDateTime(日期和时间,接收方只有秒,没有毫 秒)
-
自定义转换方法
Hystrix
概述
熔断器,也叫断路器!(正常情况下 断路器是关的 只有出了问题才打开)用来保护微服务不 雪崩的方法。
它提供了熔断器功能,能够阻止分布式系统中出现 联动故障。Hystrix 是通过隔离服务的访问点阻止联动故障的,并提供了故障的解决方案,从 而提高了整个分布式系统的弹性
当有服务调用的时候,才会出现服务雪崩,所以 Hystrix 常和 OpenFeign,Ribbon 一起出现
使用
修改 OrderServiceFeign 增加一个fallback
@FeignClient(value = "provider-order-service", fallback =OrderServiceHystrix.class)- 1
修改 yml 配置文件
feign: hystrix: enabled: true #开启断路器的使用- 1
- 2
- 3
常用配置
hystrix: #hystrix的全局控制 command: default: #default是全局控制,也可以换成单个方法控制,把default换成方法名即可 circuitBreaker: enabled: true #开启断路器 requestVolumeThreshold: 3 #失败次数(阀值) 10次 sleepWindowInMilliseconds: 20000 #窗口时间 errorThresholdPercentage: 60 #失败率 execution: isolation: Strategy: thread #隔离方式 thread线程隔离集合和semaphore信号量隔离级别 thread: timeoutInMilliseconds: 3000 #调用超时时长 fallback: isolation: semaphore: maxConcurrentRequests: 1000 #信号量隔离级别最大并发数 ribbon: ReadTimeout: 5000 #要结合feign的底层ribbon调用的时长 ConnectTimeout: 5000 #隔离方式 两种隔离方式 thread线程池 按照group(10个线程)划分服务提供者,用户请求的线程和做远程的线程不一样 # 好处 当B服务调用失败了 或者请求B服务的量太大了 不会对C服务造成影响 用户访问比较大的情况下使用比较好 异步的方式 # 缺点 线程间切换开销大,对机器性能影响 # 应用场景 调用第三方服务 并发量大的情况下 # SEMAPHORE信号量隔离 每次请进来 有一个原子计数器 做请求次数的++ 当请求完成以后 -- # 好处 对cpu开销小 # 缺点 并发请求不易太多 当请求过多 就会拒绝请求 做一个保护机制 # 场景 使用内部调用 ,并发小的情况下 # 源码入门 HystrixCommand AbstractCommand HystrixThreadPool- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Sleuth
概念
链路追踪,追踪微服务的调用路径。
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协 同产生最后的请求结果,每一个请求都会开成一条复杂的分布式服务调用链路,链路中的任何 一环出现高延时或错误都会引导起整个请求最后的失败。(不建议微服务中链路调用超过 3 次)。
分布式链路调用的监控
sleuth+zipkin(zipkin 就是一个可视化的监控控制台)
Zipkin 是 Twitter 的一个开源项目,允许开发者收集 Twitter 各个服务上的监控数据,并提 供查询接口。
该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处 理时间等,可方便的监测系统中存在的瓶颈。
下载zipkin(可视化平台)
下载 zipkin
SpringCloud 从 F 版以后已不需要自己构建 Zipkin server 了,只需要调用 jar 包即可 https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/ https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/
运行 zipkin
java -jar zipkin-server-2.12.9-exec.jar
使用
引入依赖
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-zipkinartifactId> dependency>- 1
- 2
- 3
- 4
修改配置文件
spring: zipkin: base-url: http://localhost:9411 sleuth: sampler: probability: 1 #配置采样率 默认的采样比例为: 0.1,即 10%,所设置的值介于 0 到 1 之间,1 则表示全部采集 rate: 10 #为了使用速率限制采样器,选择每秒间隔接受的 trace 量,最小数字为 0,最大值为 2,147,483,647(最大 int) 默认为- 1
- 2
- 3
- 4
- 5
- 6
- 7
查看zipkin
Gateway
什么是网关
网关是微服务最边缘的服务,直接暴露给用户,用来做用户和微服务的桥梁
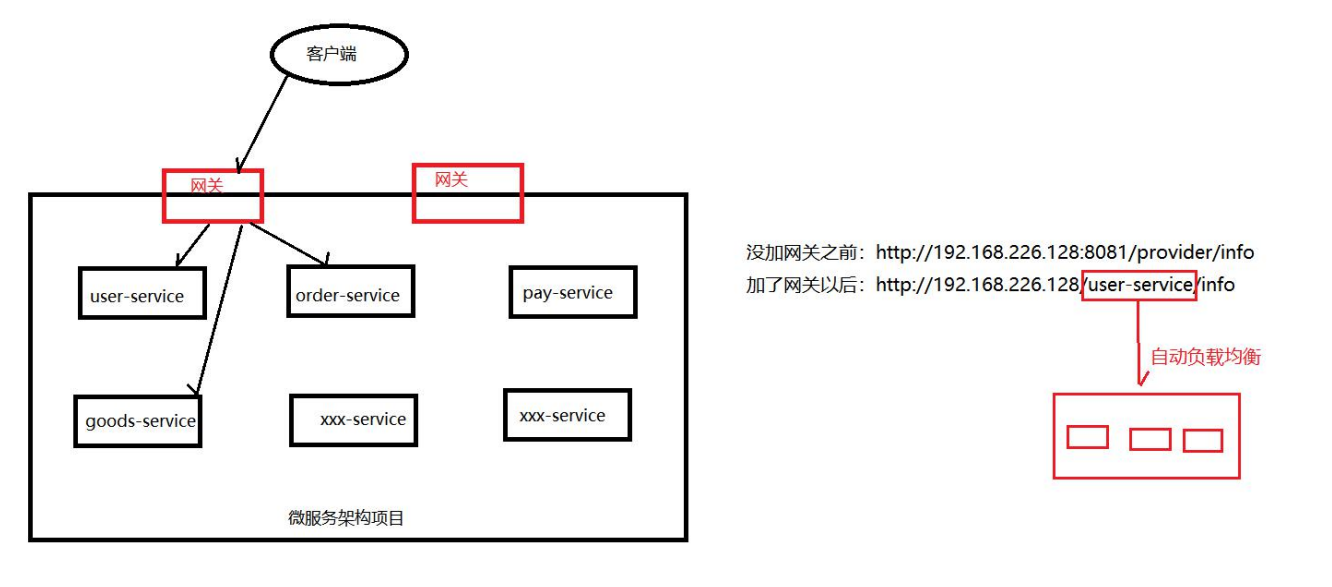
- 没有网关:客户端直接访问我们的微服务,会需要在客户端配置很多的 ip:port,如果 user-service 并发比较大,则无法完成负载均衡
- 有网关:客户端访问网关,网关来访问微服务,(网关可以和注册中心整合,通过服务名 称找到目标的 ip:prot)这样只需要使用服务名称即可访问微服务,可以实现负载均衡,可 以实现 token 拦截,权限验证,限流等操作
Spring Cloud Gateway 工作流程
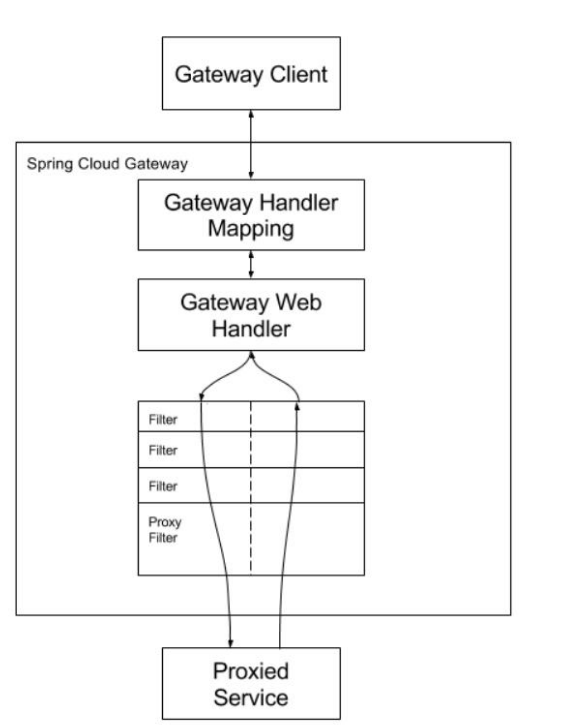
客户端向 springcloud Gateway 发出请求,然后在 Gateway Handler Mapping 中找到与 请求相匹配的路由,将其发送到 Gateway Web Handler。
Handler 再通过指定的过滤器来将请求发送到我们实际的服务的业务逻辑,然后返回。 过滤器之间用虚线分开是因为过滤器可能会在发送爱丽请求之前【pre】或之后【post】执行业务 逻辑,对其进行加强或处理。
Filter 在 【pre】 类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等
在【post】 类型的过滤器中可以做响应内容、响应头的修改、日志的输出,流量监控等有着 非常重要的作用。
总结:Gateway 的核心逻辑也就是 路由转发 + 执行过滤器链
Spring Cloud Gateway 三大核心
Route(路由)(重点 和 eureka 结合做动态路由)
路由信息的组成: 由一个 ID、一个目的 URL、一组断言工厂、一组 Filter 组成。 如果路由断言为真,说明请求 URL 和配置路由
Predicate(断言)(就是一个返回 bool 的表达式)
Spring Cloud Gateway中的 断 言 函 数 输 入 类 型 是 Spring 5.0 框 架 中 的 ServerWebExchange。Spring Cloud Gateway 的断言函数允许开发者去定义匹配来自于 Http Request 中的任何信息比如请求头和参数
Filter(过滤) (重点)
Spring Cloud Gateway 中的 Filter 分为两种类型的 Filter,分别是== Gateway Filter ==和 Global Filter。过滤器 Filter 将会对请求和响应进行修改处理。
一个是针对某一个路由(路径)的 filter ,可以对某一个接口做限流
一个是针对全局的 filter ,可以用在token验证, ip 黑名单处理
Nginx 和 Gateway 的区
-
Nginx 在做路由,负载均衡,限流之前,都有修改 nginx.conf 的配置文件,把需要负载均衡, 路由,限流的规则加在里面。Eg:使用 nginx做 tomcat 的负载均衡
-
但是 gateway 不同,gateway 自动的负载均衡和路由,gateway 和 eureka 高度集成,实现自动的路由,和 Ribbon 结合,实现了负载均衡(lb),gateway 也能轻易的实现限流和权限验证
-
Nginx(c)比 gateway(java)的性能高
-
本质的区别:Nginx (更大 服务器级别的),Gateway (项目级别的)
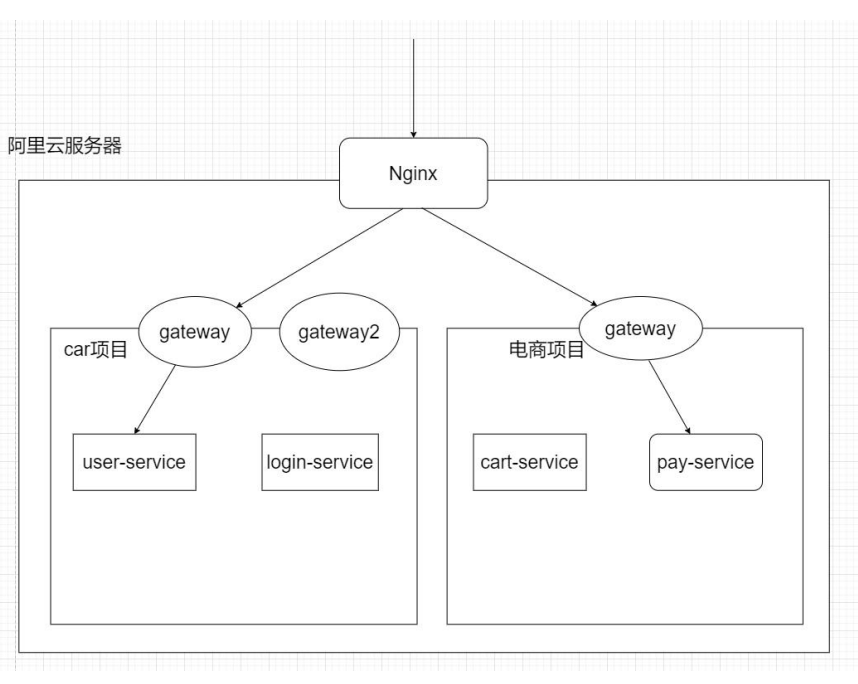
使用
引入依赖
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-gatewayartifactId> dependency>- 1
- 2
- 3
- 4
修改启动类
@SpringBootApplication @EnableEurekaClient//网关也是 eureka 的客户端 public class GatewayServerApplication { public static void main(String[] args) { SpringApplication.run(GatewayServerApplication.class, args); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改配置文件

Gateway 微服务名动态路由,负载均衡
从之前的配置里面我们可以看到我们的 URL 都是写死的,这不符合我们微服务的要求,我们 微服务是只要知道服务的名字,根据名字去找,而直接写死就没有负载均衡的效果了
默认情况下 Gateway 会根据注册中心的服务列表,以注册中心上微服务名为路径创建动态路 由进行转发,从而实现动态路由的功能
需要注意的是 uri 的协议为 lb(load Balance),表示启用 Gateway 的负载均衡功能。 lb://serviceName 是 spring cloud gateway 在微服务中自动为我们创建的负载均衡 uri 协议:就是双方约定的一个接头暗号
server: port: 80 # 网关一般是80 spring: application: name: gateway-server cloud: gateway: enabled: true # =只要加了依赖 默认开启 routes: # 如果一个服务里面有100个路径 如果我想做负载均衡 ?? 动态路由 - id: login-service-route # 这个是路由的id 保持唯一即可 # uri: http://localhost:8081 # uri统一资源定位符 url 统一资源标识符 uri: lb://login-service # uri统一资源定位符 url 统一资源标识符 discovery: locator: enabled: true # 开启动态路由 开启通用应用名称 找到服务的功能 lower-case-service-id: true # 开启服务名称小写 eureka: client: service-url: defaultZone: http://47.100.238.122:8761/eureka registry-fetch-interval-seconds: 3 # 网关拉去服务列表的时间缩短 instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
断言
断言就是路由添加一些条件(丰富路由功能的)
通俗的说,断言就是一些布尔表达式,满足条件的返回 true,不满足的返回 false。 Spring Cloud Gateway 将路由作为 Spring WebFlux HandlerMapping 基础架构的一部分 进行匹配。Spring Cloud Gateway 包括许多内置的路由断言工厂。所有这些断言都与 HTTP 请求的不同属性匹配。您可以将多个路由断言可以组合使用
Spring Cloud Gateway 创建对象时,使用 RoutePredicateFactory 创建 Predicate 对象, Predicate 对象可以赋值给 Route。
server: port: 80 # 网关一般是80 spring: application: name: gateway-server cloud: gateway: enabled: true # =只要加了依赖 默认开启 routes: # 如果一个服务里面有100个路径 如果我想做负载均衡 ?? 动态路由 - id: login-service-route # 这个是路由的id 保持唯一即可 # uri: http://localhost:8081 # uri统一资源定位符 url 统一资源标识符 uri: lb://login-service # uri统一资源定位符 url 统一资源标识符 predicates: # 断言是给某一个路由来设定的一种匹配规则 默认不能作用在动态路由上 - Path=/doLogin # 匹配规则 只要你Path匹配上了/doLogin 就往 uri 转发 并且将路径带上 - After=2022-03-22T08:42:59.521+08:00[Asia/Shanghai] - Method=GET,POST # - Query=name,admin. #正则表达式的值 discovery: locator: enabled: true # 开启动态路由 开启通用应用名称 找到服务的功能 lower-case-service-id: true # 开启服务名称小写 eureka: client: service-url: defaultZone: http://47.100.238.122:8761/eureka registry-fetch-interval-seconds: 3 # 网关拉去服务列表的时间缩短 instance: hostname: localhost instance-id: ${eureka.instance.hostname}:${spring.application.name}:${server.port}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Predicate 就是为了实现一组匹配规则,让请求过来找到对应的 Route 进行处理
Filter 过滤器工厂(重点)
gateway 里面的过滤器和 Servlet 里面的过滤器,功能差不多,路由过滤器可以用于修改进入 Http 请求和返回 Http 响应
分类
-
按生命周期分两种
pre 在业务逻辑之前 ;
post 在业务逻辑之后
-
按种类分也是两种
GatewayFilter 需要配置某个路由,才能过滤。如果需要使用全局路由,需要配置 Default Filters
GlobalFilter 全局过滤器,不需要配置路由,系统初始化作用到所有路由上
-
相关阅读:
JavaSE---二叉树
2_企业级Nginx使用-day1
JAVA在线招投标系统计算机毕业设计Mybatis+系统+数据库+调试部署
基于 Jenkins 搭建一套 CI/CD 系统
详解(一)-ThreadPollExecutor-并发编程(Java)
雪花雪花雪花
一键批量按比例修改视频尺寸:视频剪辑软件使用技巧
基于ruoyi框架项目-部署到服务器上
dubbo原理和机制
如此简单的K8S,来玩下pv和pvc,利用nfs来实现持久化存储(内网环境,非常详细)
- 原文地址:https://blog.csdn.net/weixin_65349299/article/details/125876368
