-
第2周学习:卷积神经网络基础
卷积神经网络基本组成结构
卷积

特征图的大小:(N-F)/stride+1(未加padding)
(N+padding*2-F)/stride+1 n是输入的小,f是卷积核/感受野的大小池化
Pooling:
- 保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。
- 它一般处于卷积层与卷积层之间,全连接层与全连接层之间
Pooling的类型:
- Maxpooling:最大值池化
- Averagepooling:平均池化
全连接
- 两层之间所有神经元都有权重链接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常最大
AlexNet

AlexNet创新点:
- Relu激活函数
- 数据增强
- 重叠池化
- 使用局部归一化的方案有助于增加泛化能力
- Dropout随机失活操作
AlexNet的缺陷: - 第一个卷积层使用了非常大的卷积核,导致计算量大
- 网络的深度不够
C1,C2 : 卷积 - ReLu - 池化
C3,C4 : 卷积 - ReLu
C5 : 卷积 - ReLu - 池化
F1,F2 : 全连接 - ReLu - Dropout
F3 : 全连接 - SoftMax
后边使用了大量的全连接,所以参数数量非常的大。VGG

VGG的优点:- 结构非常简洁,整个网络都使用了同样大小的卷积核(3* 3)和最大池化尺寸(2*2)
- 几个小滤波器(3* 3)卷积层的组合比一个大滤波器(5*5)卷积层好、
- 非线性变换更多
GoogleNet
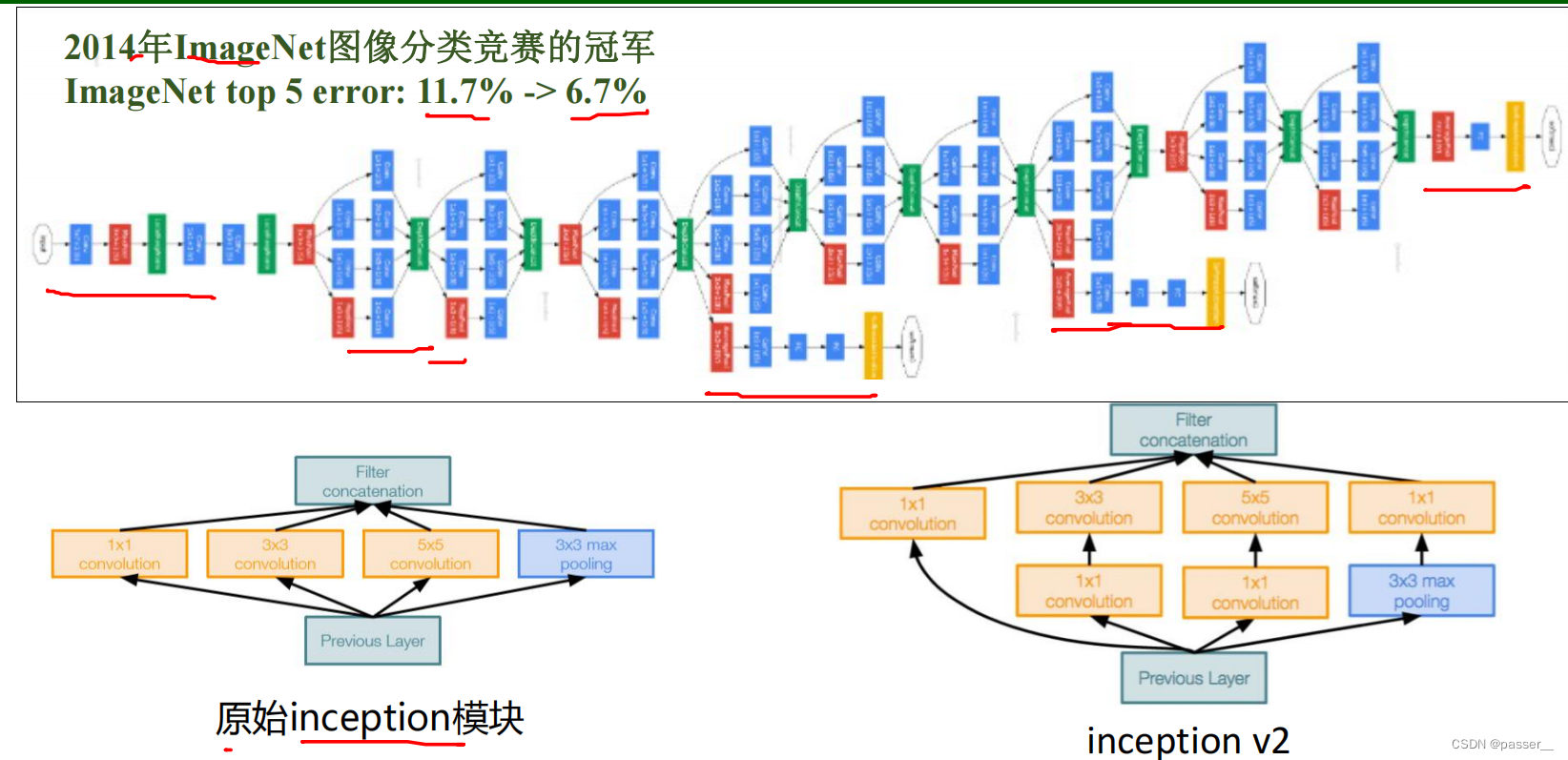
GoogleNet的创新点:
- inception V1 具有22层。包括池化层的话是 27 层,该模型在最后一个 inception 模块处使用全局平均池化。
- Inception V2学习了VGGNet,用两个33的卷积代替55的大卷积(用以降低参数量并减轻过拟合),插入1*1卷积核进行降维,还提出了著名的Batch Normalization方法。
- Inception V3网络引入了Factorization into smallconvolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积,1* n结合n* 1来代替n*n的卷积
ResNet

残差的思想: 去掉相同的主体部分,从而突出微小的变化。

代码练习
MNIST 数据集分类
在小型全连接网络上训练(Fully-connected network)

在卷积神经网络上训练

打乱像素顺序再次在两个网络上训练与测试
全连接网络 卷积神经网络 
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。 这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10 数据集分类

预测结果和实际情况存在冲突,说明效果一般。

使用 VGG16 对 CIFAR10 分类

VGG16运行中碰到问题

将cfg改变self.cfg解决问题

根据错误提示改成512即可
思考问题
1、dataloader 里面 shuffle 取不同值有什么区别?
DataLoader中的shuffer=False表示不打乱数据的顺序,然后以batch为单位从头到尾按顺序取用数据。shuffer=Ture表示在每一次epoch中都打乱所有数据的顺序,然后以batch为单位从头到尾按顺序取用数据。
2、transform 里,取了不同值,这个有什么区别?
3、epoch 和 batch 的区别?
Epoch : 使用训练集的全部数据对模型进行了一次完整的训练,被称为一代训练
Batch : 使用训练集的一小部分样本对模型权重进行一次反向传播的参数更新,这一小部分样本被称为 一批数据4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1×1卷积核是对输入的每一个特征图进行线性组合,而全连接层是对输入的每一个数进行线性组合。
1*1卷积主要是起到了降维、加入非线性、channal 的变换的作用
全连接层就是将最后一层卷积得到的特征图(矩阵)展开成一维向量,并为分类器提供输入。5、residual leanring 为什么能够提升准确率?
 有效的避免了梯度消失和梯度爆炸,可以使得网络模型更深
有效的避免了梯度消失和梯度爆炸,可以使得网络模型更深6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?

class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
代码二 LeNet 三通道 单通道 ReLu激活函数 sigmoid激活函数 最大池化 平均池化 7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
添加一个1*1的卷积核 进行调整
8、有什么方法可以进一步提升准确率?
增加数据集的大小
修改网络结构模型
增加训练的轮数
使用不同的激活函数,交叉熵函数 -
相关阅读:
长期主义,vivo的“逆周期”生长之道
卷起来了 手把手带你写一个中高级程序员必会的分布式RPC框架
React 路由/6版本
java中如何将嵌套循环性能提高500倍
Android14 WMS-IWindow介绍
(附源码)计算机毕业设计ssm 基于Java宠物寄存管理系统
postman环境变量的设置
Flutter的Event Loop
QML + KDDockWidget 实现 tabwidget效果( 窗口可独立浮动和缩放)
Vue3项目练习详细步骤(第三部分:文章分类页面模块)
- 原文地址:https://blog.csdn.net/passer__/article/details/125884461
