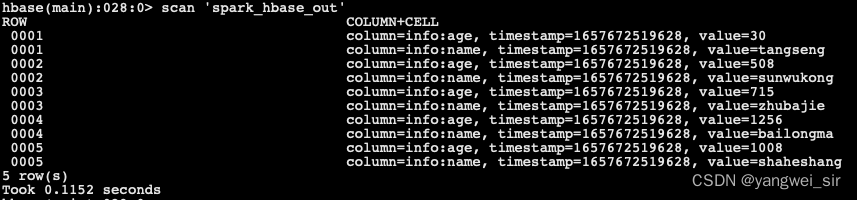
我们可以通过 Spark 整合 HBase,实现通过 Spark 来读取 HBase 的数据。 数据准备:创建 HBase 表,并插入数据: create 'spark_hbase' ,'info'
put 'spark_hbase' ,'0001' ,'info:name' ,'tangseng'
put 'spark_hbase' ,'0001' ,'info:age' ,'30'
put 'spark_hbase' ,'0001' ,'info:sex' ,'0'
put 'spark_hbase' ,'0001' ,'info:addr' ,'beijing'
put 'spark_hbase' ,'0002' ,'info:name' ,'sunwukong'
put 'spark_hbase' ,'0002' ,'info:age' ,'508'
put 'spark_hbase' ,'0002' ,'info:sex' ,'0'
put 'spark_hbase' ,'0002' ,'info:addr' ,'shanghai'
put 'spark_hbase' ,'0003' ,'info:name' ,'zhubajie'
put 'spark_hbase' ,'0003' ,'info:age' ,'715'
put 'spark_hbase' ,'0003' ,'info:sex' ,'0'
put 'spark_hbase' ,'0003' ,'info:addr' ,'shenzhen'
put 'spark_hbase' ,'0004' ,'info:name' ,'bailongma'
put 'spark_hbase' ,'0004' ,'info:age' ,'1256'
put 'spark_hbase' ,'0004' ,'info:sex' ,'0'
put 'spark_hbase' ,'0004' ,'info:addr' ,'donghai'
put 'spark_hbase' ,'0005' ,'info:name' ,'shaheshang'
put 'spark_hbase' ,'0005' ,'info:age' ,'1008'
put 'spark_hbase' ,'0005' ,'info:sex' ,'0'
put 'spark_hbase' ,'0005' ,'info:addr' ,'tiangong'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
create 'spark_hbase_out' ,'info'
< repositories> < repository> < id> id > < url> url > repository > repositories > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 object Case09_SparkWithHBase {
def main( args: Array[ String ] ) : Unit = {
val conf = new SparkConf( ) . setAppName( this . getClass. getSimpleName) . setMaster( "local[*]" )
val sc = new SparkContext( conf)
val hbaseConf = HBaseConfiguration. create( )
hbaseConf. set( "hbase.zookeeper.quorum" , "node01:2181,node02:2181,node03:2181" ) ;
hbaseConf. set( TableInputFormat. INPUT_TABLE, "spark_hbase" )
val resultRDD: RDD[ ( ImmutableBytesWritable, Result) ] = sc. newAPIHadoopRDD( hbaseConf, classOf[ TableInputFormat] ,
classOf[ ImmutableBytesWritable] , classOf[ Result] )
resultRDD. foreach( x => {
val result = x. _2
val rowKey = Bytes. toString( result. getRow)
val name = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "name" ) ) )
val age = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "age" ) ) )
println( rowKey + ":" + name + ":" + age)
} )
hbaseConf. set( TableOutputFormat. OUTPUT_TABLE, "spark_hbase_out" )
val job = Job. getInstance( hbaseConf)
job. setOutputKeyClass( classOf[ ImmutableBytesWritable] )
job. setOutputValueClass( classOf[ Result] )
job. setOutputFormatClass( classOf[ TableOutputFormat[ ImmutableBytesWritable] ] )
val outRDD: RDD[ ( ImmutableBytesWritable, Put) ] = resultRDD. mapPartitions( eachPartition => {
eachPartition. map( keyAndEachResult => {
val result = keyAndEachResult. _2
val rowKey = Bytes. toString( result. getRow)
val name = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "name" ) ) )
val age = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "age" ) ) )
val put = new Put( Bytes. toBytes( rowKey) )
val immutableBytesWritable = new ImmutableBytesWritable( Bytes. toBytes( rowKey) )
put. addColumn( Bytes. toBytes( "info" ) , Bytes. toBytes( "name" ) , Bytes. toBytes( name) )
put. addColumn( Bytes. toBytes( "info" ) , Bytes. toBytes( "age" ) , Bytes. toBytes( age) )
( immutableBytesWritable, put)
} )
} )
outRDD. saveAsNewAPIHadoopDataset( job. getConfiguration)
sc. stop( )
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
参考资料:
https://github.com/cloudera-labs/SparkOnHBase/blob/cdh5-0.0.2/src/main/scala/com/cloudera/spark/hbase/HBaseContext.scala https://issues.apache.org/jira/browse/HBASE-13992 https://github.com/cloudera-labs/SparkOnHBase 优势:
无缝的使用 HBase Connection 和 Kerberos 无缝集成 通过 get 或 scan 直接生成 RDD 利用 RDD 支持 HBase 的任何组合操作 为通用操作提供简单的方法,同时通过 API 允许不受限制的未知高级操作 支持 Java 和 Scala 为 Spark 和 Spark Streaming 提供相似的 API 由于 hbaseContext 是一个只依赖 hadoop、hbase、spark 的 jar 包的工具类,因此可以拿过来直接用 添加依赖包:
< dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency > < dependency> < groupId> groupId > < artifactId> artifactId > < version> version > dependency >
object Case10_SparkOnHBase {
def main( args: Array[ String ] ) : Unit = {
val conf = new SparkConf( ) . setAppName( this . getClass. getSimpleName) . setMaster( "local[*]" )
val sc = new SparkContext( conf)
val hbaseConf = HBaseConfiguration. create( )
hbaseConf. set( "hbase.zookeeper.quorum" , "node01:2181,node02:2181,node03:2181" ) ;
hbaseConf. set( TableInputFormat. INPUT_TABLE, "spark_hbase" )
val hbaseContext = new HBaseContext( sc, hbaseConf)
val scan = new Scan( )
val hbaseRDD: RDD[ ( ImmutableBytesWritable, Result) ] = hbaseContext. hbaseRDD( TableName. valueOf( "spark_hbase" ) , scan)
hbaseRDD. map( eachResult => {
val result: Result = eachResult. _2
val rowKey = Bytes. toString( result. getRow)
val name = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "name" ) ) )
val age = Bytes. toString( result. getValue( Bytes. toBytes( "info" ) , Bytes. toBytes( "age" ) ) )
println( rowKey + ":" + name + ":" + age)
} ) . foreach( println)
sc. stop( )
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 序列化 与反序列化Spark 是分布式执行引擎,其核心抽象是弹性分布式数据集 RDD,其代表了分布在不同节点的数据。 Spark 的计算是在 Executor 上分布式执行的,故用户开发的关于 RDD 的 map、flatMap、reduceByKey 等 transformation 操作(闭包)有如下执行过程:
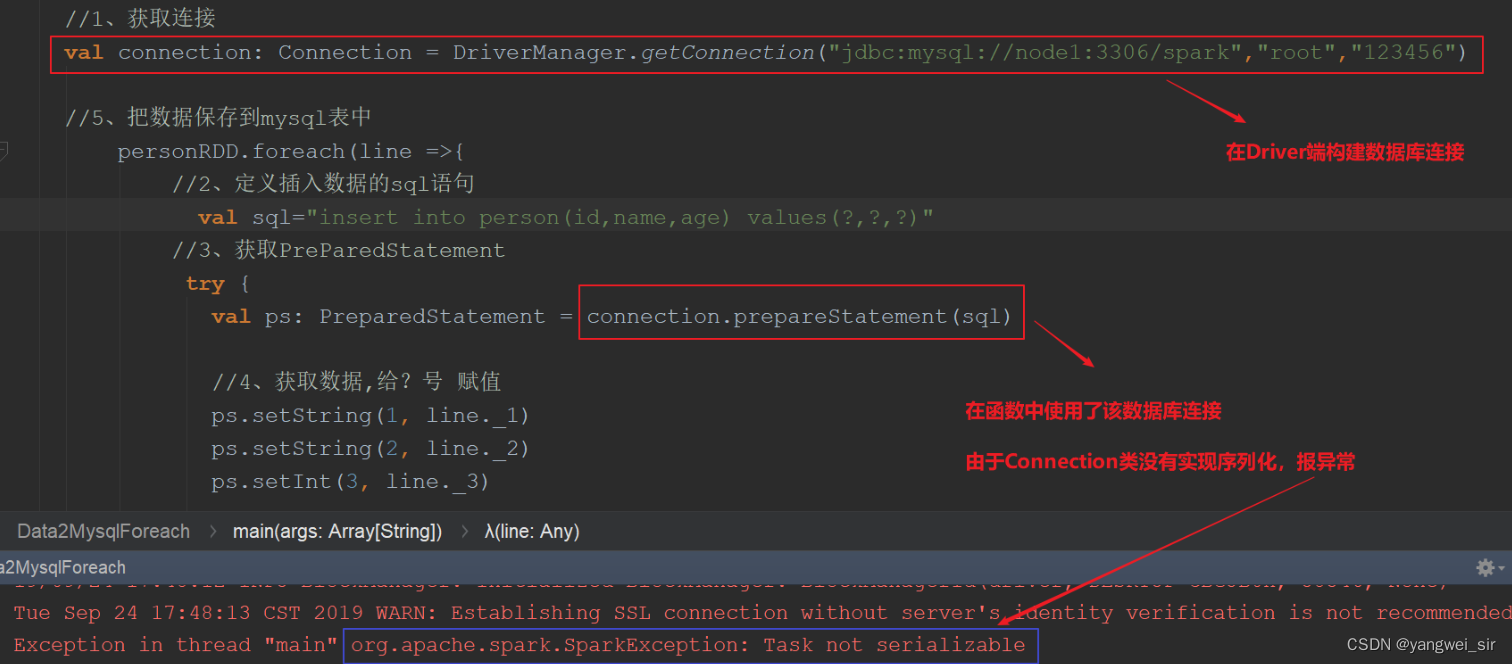
① 代码中对象在 Driver 本地序列化; ② 对象序列化后传输到远程 Executor 节点; ③ 远程 Executor 节点反序列化对象; ④ 最终远程节点执行。 故对象在执行中需要序列化通过网络传输,则必须经过序列化过程。 在编写 spark 程序中,由于在 map、foreachPartition 等算子内部使用了外部定义的变量和函数 ,从而引发 Task 未序列化问题。 然而 spark 算子在计算过程中使用外部变量在许多情形下确实在所难免:
比如在 filter 算子根据外部指定的条件进行过滤; map根据相应的配置进行变换。 经常会出现“org.apache.spark.SparkException: Task not serializable ”这个错误
其原因就在于这些算子使用了外部的变量 ,但是这个变量不能序列化。 当前类使用了“extends Serializable”声明支持序列化,但是由于某些字段不支持序列化 ,仍然会导致整个类序列化时出现问题,最终导致出现 Task 未序列化问题。
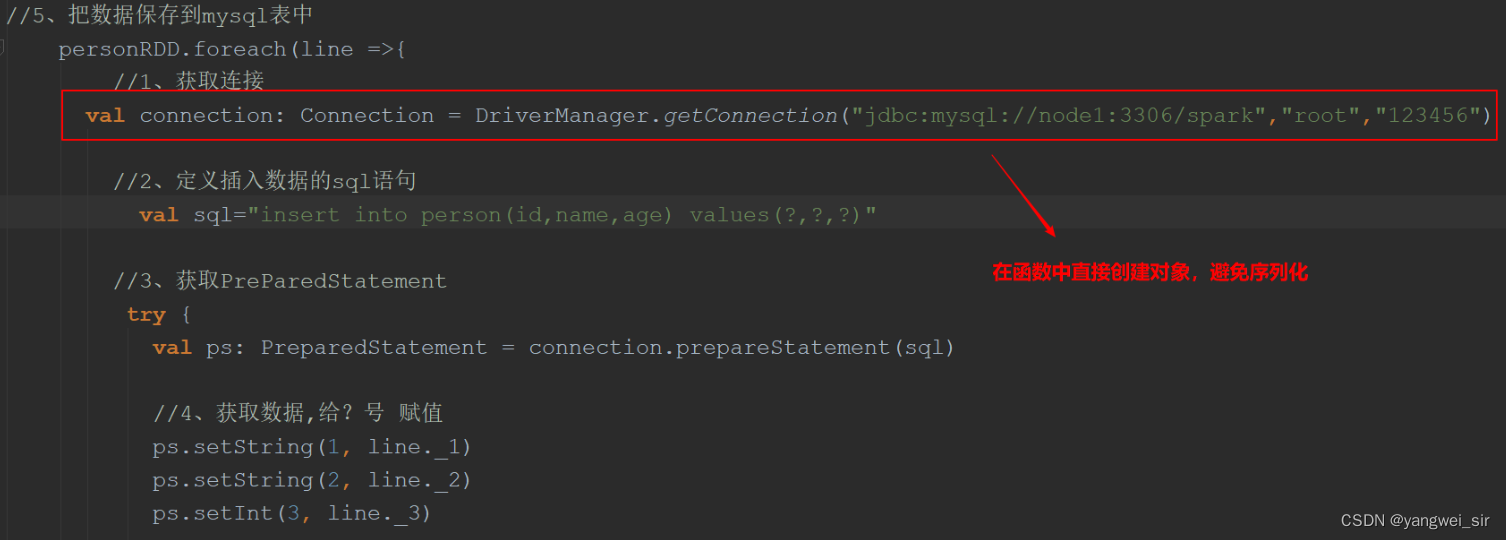
如果函数中使用了该类对象,该类要实现序列化:类 extends Serializable 。 如果函数中使用了该类对象的成员变量,该类除了要实现序列化之外,所有的成员变量必须要实现序列化。 对于不能序列化的成员变量使用==“@transient”==标注,告诉编译器不需要序列化。 也可将依赖的变量独立放到一个小的class中,让这个class支持序列化,这样做可以减少网络传输量,提高效率。 可以把对象的创建直接在该函数中构建这样避免需要序列化。
在分布式应用中,经常会进行IO操作,传递对象,而网络传输过程中就必须要序列化。 Java序列化可以序列化任何类,比较灵活,但是相当慢,并且序列化后对象的提交也比较大。 Spark 出于性能考虑,在 2.0 以后,开始支持 kryo 序列化机制,速度是 Serializable 的 10 倍以上,当 RDD 在 Shuffle 数据的时候,简单数据类型,简单数据类型数组,字符串类型 已经使用 kryo 来序列化。 也可以通过 kyro 对我们需要序列化的对象,进行序列化标价 val conf = new SparkConf( ) . setMaster( . . . ) . setAppName( . . . )
conf. registerKryoClasses( Array( classOf[ MyClass1] , classOf[ MyClass2] ) )
val sc = new SparkContext( conf)
case class MySearcher( val query: String ) {
def getMatchRddByQuery( rdd: RDD[ String ] ) : RDD[ String ] = {
rdd. filter( x => x. contains( query) )
}
}
object Case11_Kyro {
def main( args: Array[ String ] ) : Unit = {
val conf = new SparkConf( ) . setAppName( this . getClass. getSimpleName) . setMaster( "local[*]" )
. set( "spark.serializer" , "org.apache.spark.serializer.KryoSerializer" )
. registerKryoClasses( Array( classOf[ MySearcher] ) )
val sc = new SparkContext( conf)
val rdd1: RDD[ String ] = sc. parallelize( Array( "hadoop yarn" , "hadoop hdfs" , "c" ) )
val rdd2: RDD[ String ] = MySearcher( "hadoop" ) . getMatchRddByQuery( rdd1)
rdd2. foreach( println)
}
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时 Spark 作业的性能会比期望差很多。 数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证 Spark 作业的性能。 ① 绝大多数task执行得都非常快,但个别 task 执行极慢
你的大部分的 task,都执行的特别快,很快就执行完了,剩下几个 task,执行的特别特别慢; 前面的 task,一般 10s 可以执行完5个,最后发现某个task,要执行 1 个小时、2 个小时才能执行完一个 task; 这个时候就出现数据倾斜了。这种方式还算好的,因为虽然老牛拉破车一样,非常慢,但是至少还能跑。 ② 绝大数 task 执行很快,有的 task 直接报OOM (Jvm Out Of Memory) 异常
运行的时候,其他 task 都很快执行完了,也没什么特别的问题; 但是有的 task,就是会突然间报了一个 OOM,内存溢出了,task failed、task lost、resubmitting task等日志异常信息。 反复执行几次某个 task 就是跑不通,最后就挂掉。 某个 task 就直接 OOM,那么基本上也是因为数据倾斜了,task 分配的数量实在是太大了!!!所以内存放不下,然后你的 task 每处理一条数据,还要创建大量的对象。内存爆掉了。
如上图所示:在进行任务计算 shuffle 操作的时候,第一个 task 和第二个 task 各分配到了 1 万条数据;需要 5 分钟计算完毕;第三个 task要 98万 条数据,98 * 5 = 490分钟 = 8个小时; 本来另外两个 task 很快就运行完毕了(5分钟),第三个task数据量比较大,要 8 个小时才能运行完,就导致整个 spark 作业,也得 8 个小时才能运行完。最终导致整个 spark 任务计算特别慢。 主要是根据log日志信息去定位:
数据倾斜只会发生在shuffle过程 中。这里给大家罗列一些常用的并且可能会触发 shuffle 操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。 出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。因为某个或者某些 key 对应的数据,远远的高于其他的key。 分析定位逻辑:
由于代码中有大量的 shuffle 操作,一个 job 会划分成很多个 stage 首先要看的,就是数据倾斜发生在第几个 stage 中。 可以在任务运行的过程中,观察任务的 UI 界面,可以观察到每一个 stage 中运行的 task 的数据量,从而进一步确定是不是 task 分配的数据不均匀导致了数据倾斜。 比如下图中,倒数第三列显示了每个 task 的运行时间。明显可以看到,有的 task 运行特别快,只需要几秒钟就可以运行完;而有的 task 运行特别慢,需要几分钟才能运行完,此时单从运行时间 上看就已经能够确定发生数据倾斜了。 此外,倒数第一列显示了每个 task 处理的数据量,明显可以看到,运行时间特别短的 task 只需要处理几百 KB 的数据即可,而运行时间特别长的 task 需要处理几千 KB 的数据,处理的数据量 差了 10 倍。此时更加能够确定是发生了数据倾斜。
某个task莫名其妙内存溢出的情况
这种情况下去定位出问题的代码就比较容易了。 建议直接看 yarn-client 模式下本地 log 的异常栈,或者是通过 YARN 查看 yarn-cluster 模式下的 log 中的异常栈。一般来说,通过异常栈信息 就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找,一般也会有 shuffle 类算子,此时很可能就是这个算子导致了数据倾斜。 但是需要注意的是,不能单纯靠偶然的内存溢出就判定发生了数据倾斜。因为自己编写的代码的 bug,以及偶然出现的数据异常,也可能会导致内存溢出。因此还是要按照上面所讲的方法,通过 Spark Web UI 查看报错的那个 stage 的各个 task 的运行时间以及分配的数据量 ,才能确定是否是由于数据倾斜才导致了这次内存溢出。 查看导致数据倾斜的key的数据分布情况
知道了数据倾斜发生在哪里之后,通常需要分析一下那个执行了 shuffle 操作并且导致了数据倾斜的 RDD/Hive 表,查看一下其中 key 的分布情况。 这主要是为之后选择哪一种技术方案提供依据。针对不同的 key 分布与不同的 shuffle 算子 组合起来的各种情况,可能需要选择不同的技术方案来解决。 此时根据你执行操作的情况不同,可以有很多种查看key分布的方式:
① 如果是 Spark SQL 中的 group by、join 语句导致的数据倾斜,那么就查询一下 SQL 中使用的表的 key 分布情况。 ② 如果是对 Spark RDD 执行 shuffle 算子导致的数据倾斜,那么可以在 Spark 作业中加入查看 key 分布的代码,比如RDD.countByKey()。 然后对统计出来的各个key出现的次数,collect/take 到客户端打印一下,就可以看到 key 的分布情况。 举例来说,对于上面所说的单词计数程序,如果确定了是 stage1 的 reduceByKey 算子导致了数据倾斜,那么就应该看看进行reduceByKey 操作的 RDD 中的 key 分布情况,在这个例子中指的就是 pairs RDD。 如下示例,我们可以先对 pairs 采样 10% 的样本数据,然后使用 countByKey 算子统计出每个 key 出现的次数,最后在客户端遍历和打印样本数据中各个 key的出现次数。 val sampledPairs = pairs. sample( false , 0.1 )
val sampledWordCounts = sampledPairs. countByKey( )
sampledWordCounts. foreach( println( _) )
数据本身问题
① key 本身分布不均衡(包括大量的key为空) ② key 的设置不合理 spark使用不当的问题
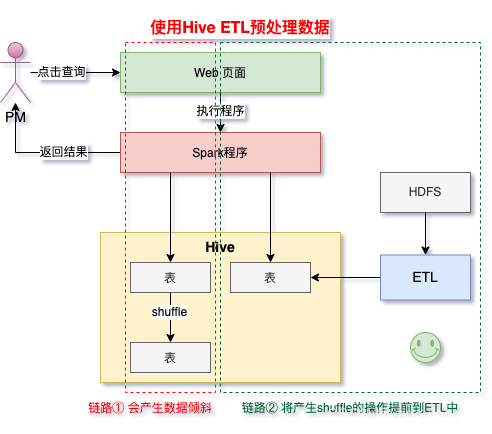
① shuffle 时的并发度不够 ② 计算方式有误 spark 中的 stage 的执行时间受限于最后那个执行完成的 task,因此运行缓慢的任务会拖垮整个程序的运行速度(分布式程序运行的速度是由最慢的那个task决定的)。 过多的数据在同一个task中运行,将会把 executor 内存撑爆,导致 OOM 内存溢出。 适用场景 :导致数据倾斜的是 Hive 表。如果该 Hive 表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用 Spark 对 Hive 表执行某个分析操作,那么比较适合使用这种技术方案。实现思路 :此时可以评估一下,是否可以通过 Hive 来进行数据预处理 (即通过 Hive ETL 预先对数据按照 key 进行聚合,或者是预先和其他表进行 join),然后在 Spark 作业中针对的数据源就不是原来的 Hive 表了,而是预处理后的 Hive 表 。此时由于数据已经预先进行过聚合或 join 操作了,那么在 Spark 作业中也就不需要使用原先的 shuffle 类算子执行这类操作了。实现原理 :这种方案从根源上解决了数据倾斜,因为彻底避免了在 Spark 中执行 shuffle 类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以 Hive ETL 中进行 group by 或者 join 等 shuffle 操作时,还是会出现数据倾斜,导致 Hive ETL 的速度很慢。我们只是把数据倾斜的发生提前到了 Hive ETL 中,避免 Spark 程序发生数据倾斜而已。优点 :实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark 作业的性能会大幅度提升。缺点 :治标不治本,Hive ETL 中还是会发生数据倾斜。实践经验 :在一些 Java 系统与 Spark 结合使用的项目中,会出现 Java 代码频繁调用 Spark 作业的场景,而且对 Spark 作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的 Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次 Java 调用 Spark 作业时,执行速度都会很快,能够提供更好的用户体验。项目经验 :有一个交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过 Java Web 系统提交数据分析统计任务,后端通过 Java 提交 Spark 作业进行数据分析统计。要求 Spark 作业速度必须要快,尽量在 10 分钟以内,否则速度太慢,用户体验会很差。所以我们将有些 Spark 作业的 shuffle 操作提前到了 Hive ETL 中,从而让 Spark 直接使用预处理的 Hive 中间表,尽可能地减少 Spark 的 shuffle 操作,大幅度提升了性能,将部分作业的性能提升了 6 倍以上。
适用场景 :如果发现导致倾斜的 key 就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如 99% 的 key 就对应 10 条数据,但是只有一个 key 对应了 100 万数据,从而导致了数据倾斜。实现思路 :如果我们判断那少数几个数据量特别多的 key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个 key。
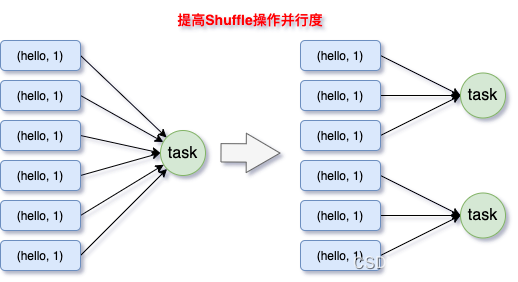
比如,在 Spark SQL 中可以使用 where 子句过滤掉这些 key 或者在 Spark Core 中对 RDD 执行 filter 算子过滤掉这些 key。 如果需要每次作业执行时,动态判定哪些 key 的数据量最多然后再进行过滤,那么可以使用 sample 算子对 RDD 进行采样,然后计算出每个 key 的数量,取数据量最多的 key 过滤掉即可。 实现原理 :将导致数据倾斜的 key 给过滤掉之后,这些 key 就不会参与计算了,自然不可能产生数据倾斜。优点 :实现简单,而且效果也很好,可以完全规避掉数据倾斜。缺点 :适用场景不多,大多数情况下,导致倾斜的 key 还是很多的,并不是只有少数几个。实践经验 :在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天 Spark 作业在运行的时候突然 OOM 了,追查之后发现,是 Hive 表中的某一个 key 在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个 key 之后,直接在程序中将那些 key 给过滤掉。适用场景 :如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。实现思路 :在对 RDD 执行 shuffle 算子时,给 shuffle 算子传入一个参数,比如 reduceByKey(_ + _, 1000),该参数就设置了这个 shuffle 算子执行时 shuffle read task 的数量。对于 Spark SQL 中的 shuffle 类语句,比如 group by、join 等,需要设置一个参数,即 spark.sql.shuffle.partitions,该参数代表了 shuffle read task 的并行度,该值默认是 200,对于很多场景来说都有点过小。实现原理 :增加 shuffle read task 的数量,可以让原本分配给一个 task 的多个 key 分配给多个 task,从而让每个 task 处理比原来更少的数据。举例来说,如果原本有 5 个 key,每个 key 对应 10 条数据,这 5 个 key 都是分配给一个 task 的,那么这个 task 就要处理 50 条数据。而增加了 shuffle read task 以后,每个 task 就分配到一个key,即每个 task 就处理10条数据,那么自然每个 task 的执行时间都会变短了。具体原理如下图所示。优点 :实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。缺点 :只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。实践经验 :该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个 key 对应的数据量有 100 万,那么无论你的 task 数量增加到多少,这个对应着 100 万数据的 key 肯定还是会分配到一个 task 中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
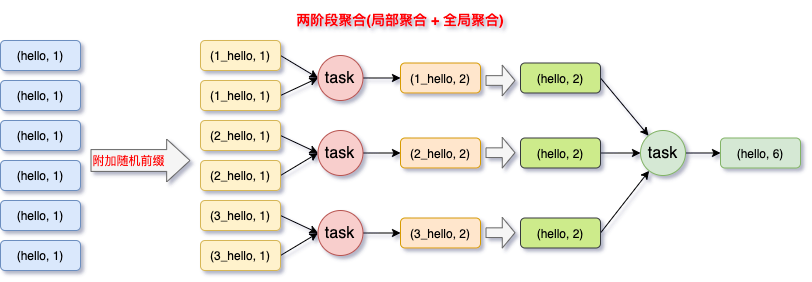
适用场景 :对 RDD 执行 reduceByKey 等聚合类 shuffle 算子 或者在 Spark SQL 中使用 group by语句 进行分组聚合时,比较适用这种方案。实现思路 :这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如 10 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个 key 的前缀给去掉,就会变成 (hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如 (hello, 4)。实现原理 :将原本相同的 key 通过附加随机前缀的方式,变成多个不同的 key,就可以让原本被一个 task 处理的数据分散到多个 task 上去做局部聚合,进而解决单个 task 处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果具体原理见下图。优点 :对于聚合类的 shuffle 操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将 Spark 作业的性能提升数倍以上。缺点 :仅仅适用于聚合类的 shuffle 操作,适用范围相对较窄。如果是 join 类的 shuffle 操作,还得用其他的解决方案。
案例 :如果使用reduceByKey因为数据倾斜造成运行失败的问题。具体操作流程如下:
object WordCountAggTest {
def main( args: Array[ String ] ) : Unit = {
val conf = new SparkConf( ) . setMaster( "local[2]" ) . setAppName( "WordCount" )
val sc = new SparkContext( conf)
val array = Array( "you you" , "you you" , "you you" ,
"you you" ,
"you you" ,
"you you" ,
"you you" ,
"jump jump" )
val rdd = sc. parallelize( array, 8 )
rdd. flatMap( line => line. split( " " ) )
. map( word => {
val prefix = ( new util. Random) . nextInt( 3 )
( prefix + "_" + word, 1 )
} ) . reduceByKey( _ + _)
. map( wc => {
val newWord = wc. _1. split( "_" ) ( 1 )
val count = wc. _2
( newWord, count)
} ) . reduceByKey( _ + _)
. foreach( wc => {
println( "单词:" + wc. _1 + " 次数:" + wc. _2)
} )
}
}
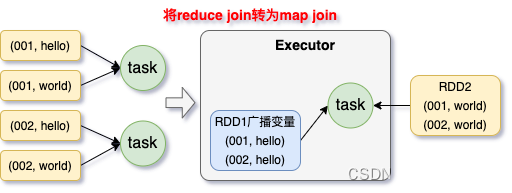
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 适用场景 :在对 RDD 使用 join 类操作,或者是在 Spark SQL 中使用 join 语句时,而且 join 操作中的一个 RDD 或表的数据量比较小(比如几百M或者一两G),比较适用此方案。实现思路 :不使用 join 算子进行连接操作,而使用 Broadcast 变量与 map 类算子实现 join 操作,进而完全规避掉 shuffle 类的操作,彻底避免数据倾斜的发生和出现。将较小 RDD 中的数据直接通过 collect 算子拉取到 Driver 端的内存中来,然后对其创建一个 Broadcast 变量;接着对另外一个 RDD 执行 map 类算子,在算子函数内,从 Broadcast 变量中获取较小 RDD 的全量数据,与当前 RDD 的每一条数据按照连接 key 进行比对,如果连接 key 相同的话,那么就将两个 RDD 的数据用你需要的方式连接起来。实现原理 :普通的 join 是会走 shuffle 过程的,而一旦 shuffle,就相当于会将相同 key 的数据拉取到一个shuffle read task 中再进行 join,此时就是 reduce join。但是如果一个 RDD 是比较小的,则可以采用广播小 RDD 全量数据 + map 算子来实现与 join 同样的效果,也就是 map join,此时就不会发生 shuffle 操作,也就不会发生数据倾斜。具体原理如下图所示。优点 :对 join 操作导致的数据倾斜,效果非常好,因为根本就不会发生 shuffle,也就根本不会发生数据倾斜。缺点 :适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver 和每个 Executor 内存中都会驻留一份小 RDD 的全量数据。如果我们广播出去的 RDD 数据比较大,比如 10G 以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
适用场景 :两个 RDD/Hive 表进行 join 的时候,如果数据量都比较大,无法采用“解决方案五”,那么此时可以看一下两个 RDD/Hive 表中的 key 分布情况。如果出现数据倾斜,是因为其中某一个 RDD/Hive 表中的少数几个 key 的数据量过大,而另一个 RDD/Hive 表中的所有 key 都分布比较均匀,那么采用这个解决方案是比较合适的。实现思路 :
① 对包含少数几个数据量过大的 key 的那个 RDD,通过 sample 算子采样出一份样本来,然后统计一下每个 key 的数量,计算出来数据量最大的是哪几个 key。 ② 然后将这几个 key 对应的数据从原来的 RDD 中拆分出来,形成一个单独的 RDD,并给每个 key 都打上 n 以内的随机数作为前缀,而不会导致倾斜的大部分 key 形成另外一个 RDD。 ③ 接着将需要 join 的另一个 RDD,也过滤出来那几个倾斜 key 对应的数据并形成一个单独的 RDD,将每条数据膨胀成 n 条数据,这 n 条数据都按顺序附加一个 0~n 的前缀,不会导致倾斜的大部分 key 也形成另外一个 RDD。 ④ 再将附加了随机前缀的独立 RDD 与另一个膨胀 n 倍的独立 RDD 进行 join,此时就可以将原先相同的 key 打散成 n 份,分散到多个 task 中去进行 join 了。 ⑤ 而另外两个普通的 RDD 就照常 join 即可。 ⑥ 最后将两次 join 的结果使用 union 算子合并起来即可,就是最终的 join 结果。 实现原理 :对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,可以将少数几个 key 分拆成独立 RDD,并附加随机前缀打散成 n 份去进行 join,此时这几个 key 对应的数据就不会集中在少数几个 task 上,而是分散到多个 task 进行 join 了。优点 :对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,采用该方式可以用最有效的方式打散 key 进行 join。而且只需要针对少数倾斜 key 对应的数据进行扩容 n 倍,不需要对全量数据进行扩容。避免了占用过多内存。缺点 :如果导致倾斜的 key 特别多的话,比如成千上万个 key 都导致数据倾斜,那么这种方式也不适合。
适用场景 :如果在进行 join 操作时,RDD 中有大量的 key 导致数据倾斜 ,那么进行分拆 key 也没什么意义,此时就只能使用这一种方案来解决问题了。实现思路 :
① 该方案的实现思路基本和“解决方案六”类似,首先查看 RDD/Hive 表中的数据分布情况,找到那个造成数据倾斜的 RDD/Hive 表,比如有多个 key 都对应了超过 1 万条数据。 ② 然后将该 RDD 的每条数据都打上一个 n 以内的随机前缀。 ③ 同时对另外一个正常的 RDD 进行扩容,将每条数据都扩容成 n 条数据,扩容出来的每条数据都依次打上一个 0~n 的前缀。 ④ 最后将两个处理后的 RDD 进行 join 即可。 实现原理 :将原先一样的 key 通过附加随机前缀变成不一样的 key,然后就可以将这些处理后的“不同key”分散到多个 task 中去处理,而不是让一个 task 处理大量的相同 key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾斜 key 对应的数据进行特殊处理,由于处理过程需要扩容 RDD,因此上一种方案扩容 RDD 后对内存的占用并不大;而这一种方案是针对有大量倾斜 key 的情况,没法将部分 key 拆分出来进行单独处理,因此只能对整个 RDD 进行数据扩容,对内存资源要求很高。优点 :对 join 类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。缺点 :该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。实践经验 :曾经开发一个数据需求的时候,发现一个 join 导致了数据倾斜。优化之前,作业的执行时间大约是 60 分钟左右;使用该方案优化之后,执行时间缩短到 10 分钟左右,性能提升了 6 倍。