-
这几个Python实战项目,让大家了解到它的神奇
Python 是一种极具可读性和通用性的编程语言。Python 易于设置,并且是用相对直接的风格来编写,对错误会提供即时反馈,对初学者而言是个很好的选择。
Python 是一种多范式语言,也就是说,它支持多种编程风格,包括脚本和面向对象,这使得它适用于通用目的。

Python项目练习一:即时标记
这个项目分为四个模块:
分析器:负责读取文本,管理其他的类
规则:检测文本块的类型(标题,列表等),使用相对应的规则
过滤器:处理一些内嵌元素,比如
处理程序:为文本块添加标记
目的就是要将一段文本根据文本的格式转换成HTML

Python项目练习二:画幅好画
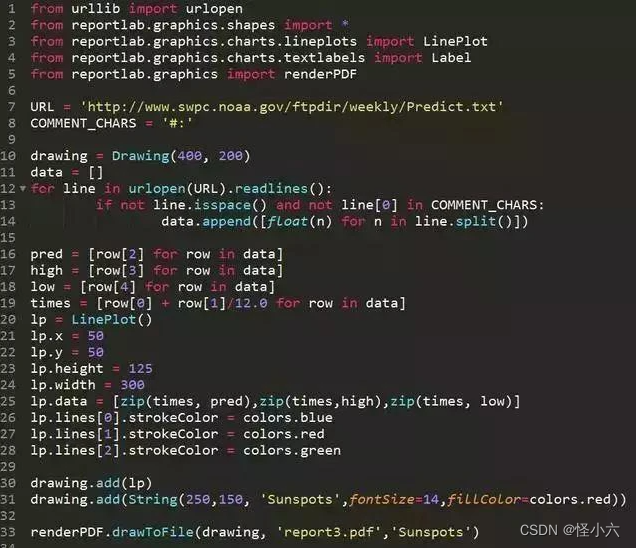
这是《python基础教程》中的第二个项目,关于python操作PDF
涉及到的知识点
1、urllib的使用
2、reportlab库的使用
这个例子着实很简单,不过我发现在python里面可以直接在数组[]里面写for循环,真是越用越方便。
下面是代码:
Python项目练习三:新闻聚合
新闻聚合,现在很少见的一类应用,至少我从来没有用过,又叫做Usenet。
这个程序的主要功能是用来从指定的来源(这里是Usenet新闻组)收集信息,然后讲这些信息保存到指定的目的文件中(这里使用了两种形式:纯文本和html文件)。from nntplib import NNTP from time import strftime,time,localtime from email import message_from_string from urllib import urlopen import textwrap import re day = 24*60*60 def wrap(string,max=70): ''' ''' return '\n'.join(textwrap.wrap(string)) + '\n' class NewsAgent: ''' ''' def __init__(self): self.sources = [] self.destinations = [] def addSource(self,source): self.sources.append(source) def addDestination(self,dest): self.destinations.append(dest) def distribute(self): items = [] for source in self.sources: items.extend(source.getItems()) for dest in self.destinations: dest.receiveItems(items) class NewsItem: def __init__(self,title,body): self.title = title self.body = body class NNTPSource: def __init__(self,servername,group,window): self.servername = servername self.group = group self.window = window def getItems(self): start = localtime(time() - self.window*day) date = strftime('%y%m%d',start) hour = strftime('%H%M%S',start) server = NNTP(self.servername) ids = server.newnews(self.group,date,hour)[1] for id in ids: lines = server.article(id)[3] message = message_from_string('\n'.join(lines)) title = message['subject'] body = message.get_payload() if message.is_multipart(): body = body[0] yield NewsItem(title,body) server.quit() class SimpleWebSource: def __init__(self,url,titlePattern,bodyPattern): self.url = url self.titlePattern = re.compile(titlePattern) self.bodyPattern = re.compile(bodyPattern) def getItems(self): text = urlopen(self.url).read() titles = self.titlePattern.findall(text) bodies = self.bodyPattern.findall(text) for title.body in zip(titles,bodies): yield NewsItem(title,wrap(body)) class PlainDestination: def receiveItems(self,items): for item in items: print item.title print '-'*len(item.title) print item.body class HTMLDestination: def __init__(self,filename): self.filename = filename def receiveItems(self,items): out = open(self.filename,'w') print >> out,'''Today's News Today's News '''
print >> out, '- '
- %s
' % (id,item.title) print >> out, '' id = 0 for item in items: id += 1 print >> out, '%s
' % (id,item.title) print >> out, '%s
' % item.body print >> out, ''' ''' def runDefaultSetup(): agent = NewsAgent() bbc_url = 'http://news.bbc.co.uk/text_only.stm' bbc_title = r'(?s)a href="[^" rel="external nofollow" ]*">\s*\s*(.*?)\s*' bbc_body = r'(?s)\s*
\s*(.*?)\s*<' bbc = SimpleWebSource(bbc_url, bbc_title, bbc_body) agent.addSource(bbc) clpa_server = 'news2.neva.ru' clpa_group = 'alt.sex.telephone' clpa_window = 1 clpa = NNTPSource(clpa_server,clpa_group,clpa_window) agent.addSource(clpa) agent.addDestination(PlainDestination()) agent.addDestination(HTMLDestination('news.html')) agent.distribute() if __name__ == '__main__': runDefaultSetup()from nntplib import NNTP from time import strftime,time,localtime from email import message_from_string from urllib import urlopen import textwrap import re day = 24*60*60 def wrap(string,max=70): ''' ''' return '\n'.join(textwrap.wrap(string)) + '\n' class NewsAgent: ''' ''' def __init__(self): self.sources = [] self.destinations = [] def addSource(self,source): self.sources.append(source) def addDestination(self,dest): self.destinations.append(dest) def distribute(self): items = [] for source in self.sources: items.extend(source.getItems()) for dest in self.destinations: dest.receiveItems(items) class NewsItem: def __init__(self,title,body): self.title = title self.body = body class NNTPSource: def __init__(self,servername,group,window): self.servername = servername self.group = group self.window = window def getItems(self): start = localtime(time() - self.window*day) date = strftime('%y%m%d',start) hour = strftime('%H%M%S',start) server = NNTP(self.servername) ids = server.newnews(self.group,date,hour)[1] for id in ids: lines = server.article(id)[3] message = message_from_string('\n'.join(lines)) title = message['subject'] body = message.get_payload() if message.is_multipart(): body = body[0] yield NewsItem(title,body) server.quit() class SimpleWebSource: def __init__(self,url,titlePattern,bodyPattern): self.url = url self.titlePattern = re.compile(titlePattern) self.bodyPattern = re.compile(bodyPattern) def getItems(self): text = urlopen(self.url).read() titles = self.titlePattern.findall(text) bodies = self.bodyPattern.findall(text) for title.body in zip(titles,bodies): yield NewsItem(title,wrap(body)) class PlainDestination: def receiveItems(self,items): for item in items: print item.title print '-'*len(item.title) print item.body class HTMLDestination: def __init__(self,filename): self.filename = filename def receiveItems(self,items): out = open(self.filename,'w') print >> out,'''Today's News Today's News '''
print >> out, '- '
- %s
' % (id,item.title) print >> out, '' id = 0 for item in items: id += 1 print >> out, '%s
' % (id,item.title) print >> out, '%s
' % item.body print >> out, ''' ''' def runDefaultSetup(): agent = NewsAgent() bbc_url = 'http://news.bbc.co.uk/text_only.stm' bbc_title = r'(?s)a href="[^" rel="external nofollow" ]*">\s*\s*(.*?)\s*' bbc_body = r'(?s)\s*
\s*(.*?)\s*<' bbc = SimpleWebSource(bbc_url, bbc_title, bbc_body) agent.addSource(bbc) clpa_server = 'news2.neva.ru' clpa_group = 'alt.sex.telephone' clpa_window = 1 clpa = NNTPSource(clpa_server,clpa_group,clpa_window) agent.addSource(clpa) agent.addDestination(PlainDestination()) agent.addDestination(HTMLDestination('news.html')) agent.distribute() if __name__ == '__main__': runDefaultSetup()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
这个程序,首先从整体上进行分析,重点部分在于NewsAgent,它的作用是存储新闻来源,存储目标地址,然后在分别调用来源服务器(NNTPSource以及SimpleWebSource)以及写新闻的类(PlainDestination和HTMLDestination)。所以从这里也看的出,NNTPSource是专门用来获取新闻服务器上的信息的,SimpleWebSource是获取一个url上的数据的。而PlainDestination和HTMLDestination的作用很明显,前者是用来输出获取到的内容到终端的,后者是写数据到html文件中的。

以上就是本次分享的所有内容,如果你觉得文章还不错,欢迎关注公众号:Python日志,资料源码领取加QQ群:676910747
-
相关阅读:
Linux开发——Ubuntu 下文本编辑(三)
若依 vue前端 动态设置路由path不同参数 在页面容器里打开新页面,面包屑和标签页标题根据参数动态改变
【项目】实现一个mini的tcmalloc(高并发内存池)
res_company_white_url.py 详解
g2o中的核函数
Bun v0.8.0 正式发布,Zig 编写的 JavaScript 运行时
Linux学习笔记14—IO多路复用:select/poll/epoll与Reactor模式
【算法优选】 前缀和专题——贰
Java Agent 踩坑之 appendToSystemClassLoaderSearch 问题
Go Zero微服务个人探究之路(十六)回顾api服务和rpc服务的本质
- 原文地址:https://blog.csdn.net/m0_66903902/article/details/125815952
