-
面试突击:MySQL 中如何去重?

在 MySQL 中,最常见的去重方法有两个:使用 distinct 或使用 group by,那它们有什么区别呢?接下来我们一起来看。
1.创建测试数据
- -- 创建测试表
- drop table if exists pageview;
- create table pageview(
- id bigint primary key auto_increment comment '自增主键',
- aid bigint not null comment '文章ID',
- uid bigint not null comment '(访问)用户ID',
- createtime datetime default now() comment '创建时间'
- ) default charset='utf8mb4';
- -- 添加测试数据
- insert into pageview(aid,uid) values(1,1);
- insert into pageview(aid,uid) values(1,1);
- insert into pageview(aid,uid) values(2,1);
- insert into pageview(aid,uid) values(2,2);
最终展现效果如下:
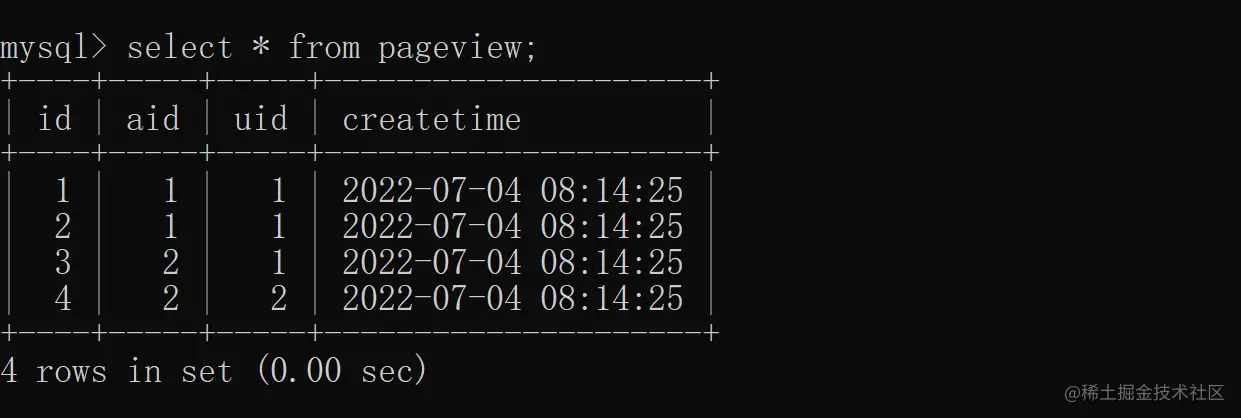
2.distinct 使用
distinct 基本语法如下:
SELECT DISTINCT column_name,column_name FROM table_name;2.1 单列去重
我们先用 distinct 实现单列去重,根据 aid(文章 ID)去重,具体实现如下:

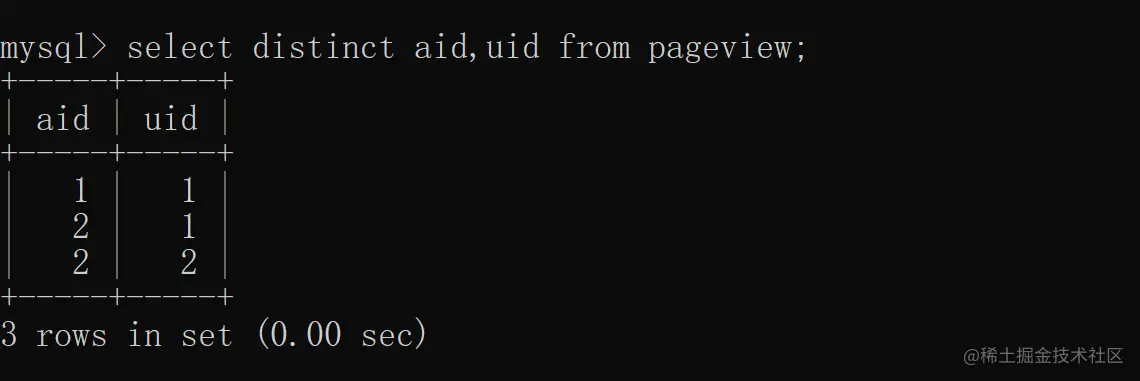
2.2 多列去重
除了单列去重之外,distinct 还支持多列(两列及以上)去重,我们根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
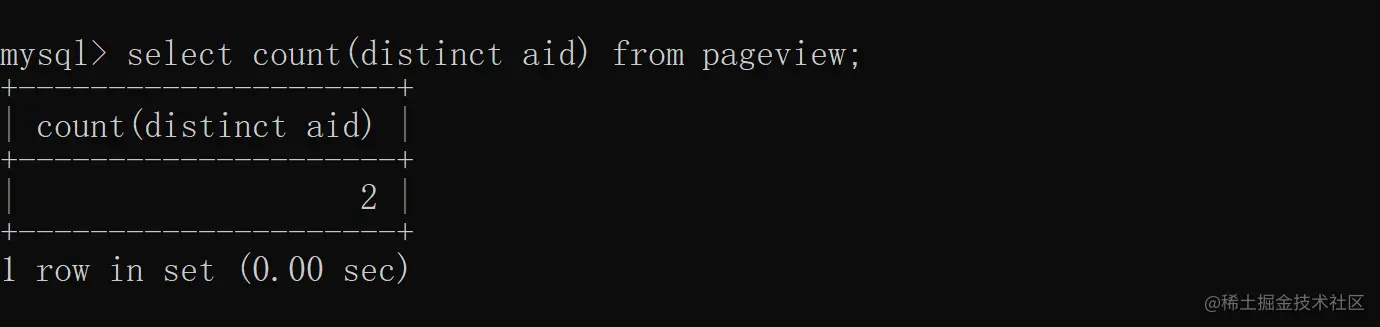
2.3 聚合函数+去重
使用 distinct + 聚合函数去重,计算 aid 去重之后的总条数,具体实现如下:
3.group by 使用
group by 基础语法如下:
- SELECT column_name,column_name FROM table_name
- WHERE column_name operator value
- GROUP BY column_name
3.1 单列去重
根据 aid(文章 ID)去重,具体实现如下:
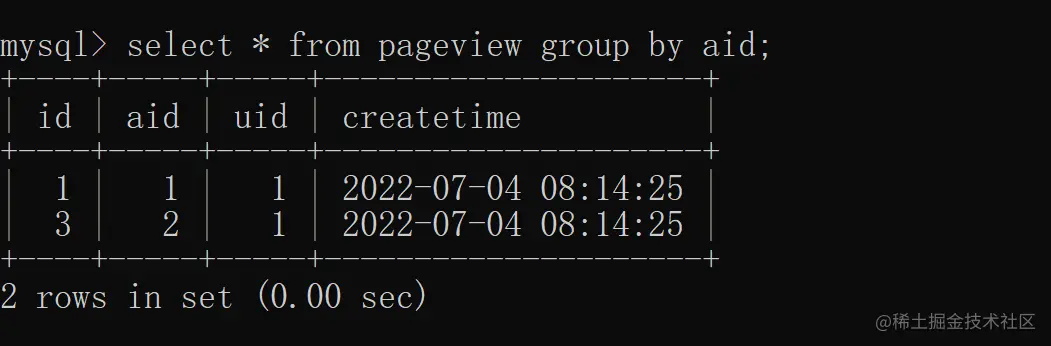
与 distinct 相比 group by 可以显示更多的列,而 distinct 只能展示去重的列。
3.2 多列去重
根据 aid(文章 ID)和 uid(用户 ID)联合去重,具体实现如下:
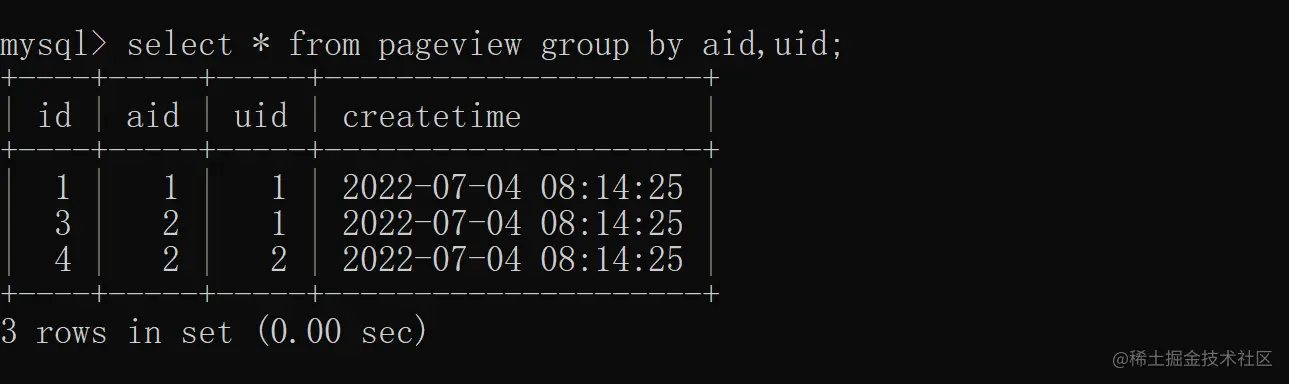
3.3 聚合函数 + group by
统计每个 aid 的总数量,SQL 实现如下:
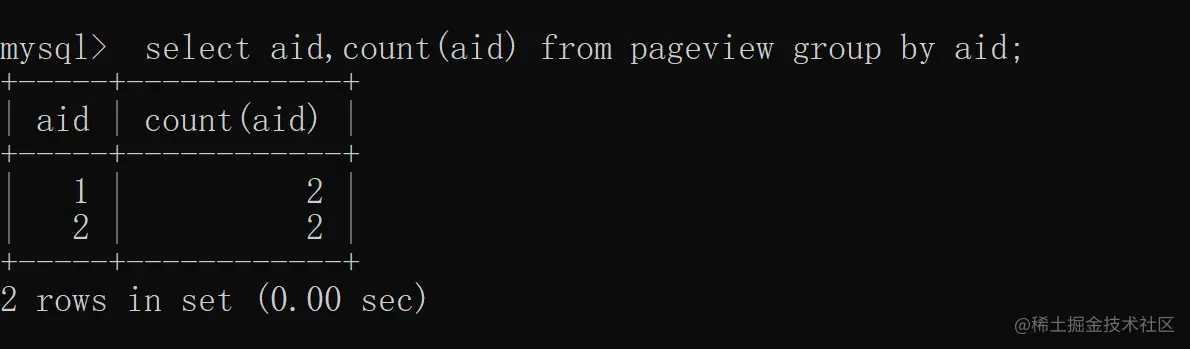
从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
4.distinct 和 group by 的区别
官方文档在描述 distinct 时提到:在大多数情况下 distinct 是特殊的 group by,如下图所示:

官方文档地址:dev.mysql.com/doc/refman/… 但二者还是有一些细微的不同的,比如以下几个。
区别1:查询结果集不同
当使用 distinct 去重时,查询结果集中只有去重列信息,如下图所示:

当你试图添加非去重字段(查询)时,SQL 会报错如下图所示: 而使用 group by 排序可以查询一个或多个字段,如下图所示:
区别2:使用业务场景不同
统计去重之后的总数量需要使用 distinct,而统计分组明细,或在分组明细的基础上添加查询条件时,就得使用 group by 了。 使用 distinct 统计某列去重之后的总数量:
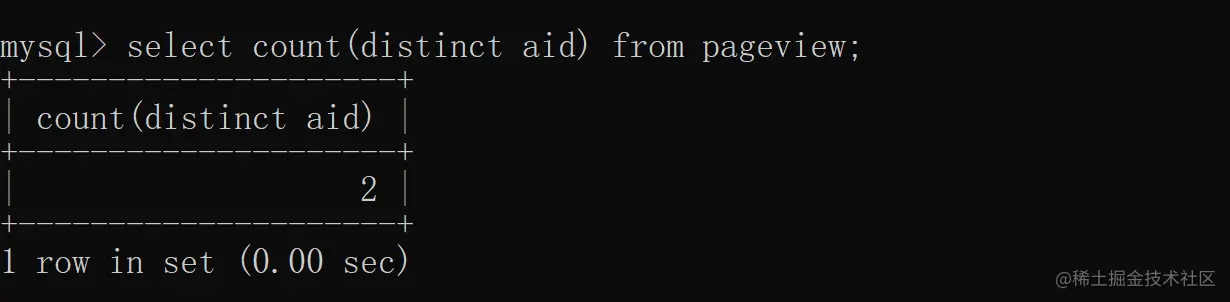
统计分组之后数量大于 2 的文章,就要使用 group by 了,如下图所示:
区别3:性能不同
如果去重的字段有索引,那么 group by 和 distinct 都可以使用索引,此情况它们的性能是相同的;而当去重的字段没有索引时,distinct 的性能就会高于 group by,因为在 MySQL 8.0 之前,group by 有一个隐藏的功能会进行默认的排序,这样就会触发 filesort 从而导致查询性能降低。
总结
大部分场景下 distinct 是特殊的 group by,但二者也有细微的区别,比如它们在查询结果集上、使用的具体业务场景上,以及性能上都是不同的。

-
相关阅读:
[附源码]Python计算机毕业设计Django的小区宠物管理系统
(c/c++)——函数指针(回调函数)
php组件漏洞
Java项目:94 springboot大学城水电管理系统
opencv-图片水印
Gradle 笔记 2
pta——建立学生信息链表,逆序数据建立链表,删除单链表偶数节点,链表拼接,统计专业人数,链表逆置
qt6 多媒体开发代码分析(四、视频播放)
警惕国外科技断供风险:CACTER邮件网关信创一体机为商业银行提供全国产化防护
C# Winform编程(9)网络编程
- 原文地址:https://blog.csdn.net/m0_71777195/article/details/125636200