-
用于增强压缩视频质量的可变形卷积密集网络
DEFORMABLE CONVOLUTION DENSE NETWORK FOR COMPRESSED VIDEO QUALITY
ENHANCEMENTABSTRACT
与传统的视频质量增强不同,压缩视频质量增强的目标是减少视频压缩带来的伪影。现有的多帧压缩视频质量增强方法严重依赖于光流,效率低,性能有限。本文提出了一种具有可变形卷积的多帧剩余密集网络(MRDN),通过利用高质量帧来补偿低质量帧来提高压缩视频的质量。具体来说,该网络由开发的运动补偿(MC)模块和质量增强(QE)模块组成,分别用于补偿和增强输入帧的质量。此外,在增强帧上进行了一种新的边缘增强损失,以增强训练期间的边缘结构。最后,在公共基准测试上的实验结果表明,我们的方法优于最先进的压缩视频质量增强方法。
1. INTRODUCTION
为了减少所需的带宽和存储空间,视频压缩算法被广泛应用于许多实际应用场景[1],但这些算法也带来了视频质量下降的问题。因此,如何提高压缩视频的质量是研究界和业界共同关注的问题。作为减少压缩伪影的一种重要方法,压缩视频质量增强包括消除块效应、减少边缘/纹理浮动以及从蚊子噪声(由于帧采样而感知到不均匀或摇摆的运动)和抖动中重建视频的技术[2]。然而,由于细节在压缩过程中丢失,因此从失真帧重建高质量帧是一个挑战。
最近,人们提出了许多增强压缩图像/视频质量的方法,特别是借助深度学习[3、4、5]。早期方法[5、6、7、8]独立增强每个帧,这些方法简单,但无法利用相邻帧的细节。为了利用时间信息,杨等人[9]首先提出了一种用于压缩视频质量增强的多帧策略。从那时起,关等人[10]通过细化关键模块进一步发展了该方法。然而,由于视频内容被压缩伪影严重失真,现有的大多数基于多帧的方法中使用的光流方法不够可靠。因此,增强视频远不能令人满意。
与在像素级预测光流相比,在接收场中提取特征可以更稳健地增强压缩视频质量。基于这一思想,我们提出了一种具有可变形卷积的多帧网络[11,12],以实现多个运动对象的运动补偿。具体来说,与视频任务中使用的传统可变形卷积网络[13、14、15]不同,我们开发了一种新的金字塔形可变形结构来提取多尺度对齐信息,并添加了一个新的约束来减少参考帧中的噪声。
此外,基于残差密集网络在图像超分辨率任务中的应用[16],我们开发了一种新的具有残差块的密集连接网络,称为MRDN,以进一步提高提取更多层次特征的能力,进而实现更好的压缩视频质量增强。此外,通过对压缩视频的分析,我们发现压缩视频的质量下降通常发生在视频中的对象边缘。因此,设计了一种边缘增强损耗,使网络更加关注边缘重建
本文的主要贡献如下:(1)提出了一种新的压缩视频质量增强方法。该方法开发了一种具有有效运动补偿约束的新型棱锥变形结构,并采用剩余密集网络来提高质量;(2) 通过分析压缩视频质量下降的原因,我们开发了一种新的loss算法来提高边缘重建的性能;(3) 我们在压缩视频质量增强基准数据库上评估了该方法,并实现了最先进的性能.

2. THE PROPOSED SYSTEM
2.1. Overview
与传统的视频质量增强不同,压缩视频增强的目标是减少或消除视频压缩带来的伪影和模糊。为此,受[9]的启发,我们提出了一种能够利用峰值质量帧(PQF)的多帧网络∗ 因此,为了补偿低质量帧,提高了压缩视频的质量。如图1所示,网络由开发的MC模块和QE模块组成。设Fnp表示当前帧,Fp1和Fp2分别是最近的先前和后续PQF。以PQF(Fp1或Fp2)为参考帧,开发了基于可变形卷积的MC模块来预测时间运动,并对输入帧Fnp进行更详细的补偿。随后,将补偿后的帧串联为QE模块的输入,该模块的开发旨在进一步提高帧的质量。最后,在增强帧上进行了一种新的边缘增强损失,以增强训练期间的边缘结构。我们的新MC、QE和边缘增强损耗的详细信息将在以下章节中介绍.
2.2. MC module
对于视频相关任务中的传统可变形卷积网络,大多数都学习参考帧上的偏移δ,然后使用可变形卷积来提取当前帧上的对齐特征。获得的具有N个像素的对齐特征Fa定义为:

其中F是当前帧的特征,在本文中定义为Fnp。pi是F中的第i个位置,K是卷积核的大小,wk是第K个位置的权重,pk是第k个位置的预先指定偏移量。例如,pk∈ (−1.−1), (−1, 0), . . . , (1,1)对于K=3。
考虑到帧上通常同时存在多个运动对象,我们将多个可变形卷积构造成金字塔结构,以提取多尺度对齐特征,并通过级联增强信息交互。具体来说,金字塔可变形结构有3层,每层以不同的分辨率从输入中提取对齐的特征。层越深,输入分辨率越小。同时,通过级联,第l层的偏移
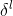 和对齐特征
和对齐特征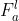 与下一层的
与下一层的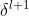 和
和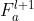 合并。对齐特征可以定义为:
合并。对齐特征可以定义为: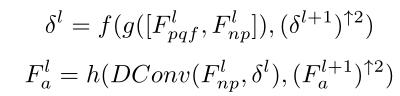
f、 g和h都是使用ReLU激活的非线性变换层,和(·)↑s是按因子s进行的上采样。本文中s为2。最后,使用另一卷积层预测对齐特征上的补偿帧。
2.3. QE module
在获得补偿后的PQFs(
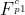 和
和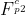 )后,需要QE模块融合补偿帧和当前帧之间的信息,进一步提高当前帧的质量。为了提高QE模块的长期记忆能力,我们采用参数
)后,需要QE模块融合补偿帧和当前帧之间的信息,进一步提高当前帧的质量。为了提高QE模块的长期记忆能力,我们采用参数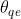 的剩余密集网络来提取更多层次特征。该QE模块将补偿帧和当前帧串联作为输入,然后输出残余
的剩余密集网络来提取更多层次特征。该QE模块将补偿帧和当前帧串联作为输入,然后输出残余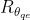 。通过将该残差添加到当前帧,可以生成更高质量的帧
。通过将该残差添加到当前帧,可以生成更高质量的帧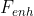 :
: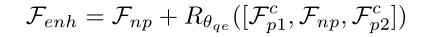
2.4. Loss functions
Edge enhancement loss:在压缩视频质量增强中,均方误差(MSE)被广泛使用。然而,MSE损耗不能很好地指导网络改善对象边缘的质量。为了使网络更加关注边缘重建,我们提出了一种边缘增强损耗。给定包含N个像素的增强帧
及其对应的原始帧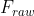 ,它们之间的边缘增强损失定义为:
,它们之间的边缘增强损失定义为:

Total Loss:
与其他视频任务不同,压缩视频质量增强任务对噪声非常敏感。因此,我们不仅优化了qe模块的参数θqe,还对mc模块的参数θmc添加了约束。具体来说,对于MC模块,补偿帧不仅需要提供对齐结果,还应该保留与原始帧Fraw类似的质量。对于QE模块,增强帧Fenh的质量要求与原始帧一样高。因此,总损失定义为:
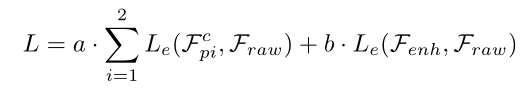
3. EXPERIMENT
3.1. Datasets
为了训练提出的模型,利用了Guan等人的数据库[10]。该数据库由从Xiph.org数据集中选择的160个未压缩视频组成。VGEG和视频编码联合协作团队(JCT-VC)[17],其中106个视频用于训练。为了进行测试,提出的模型在18个标准测试视频[18]上进行了评估,这些视频收集自JCT-VC,广泛用于视频质量评估。以上视频均采用HM 16.5在LDP模式下压缩,采用4种不同的QP,即22、27、32、37。
3.2. Implementation Details
在训练过程中,我们使用压缩帧及其先前和后续的PQF作为输入帧,然后将这些帧随机裁剪为64x64块。然后,使用Adam优化器[19]优化模型,初始学习率为1e-4,批量大小设置为16。此外,在训练期间,运动补偿模块和质量增强模块的损失权重分别设置为1和0.001。在100000次迭代后,这两个模块的损失重量将更改为0.001和1。注意,我们为QP 22、27、32和37训练了四个模型。此外,为了更清楚地比较实验结果,我们根据增量峰值信噪比(
 PSNR)和结构相似性(SSIM)评估了我们和比较的方法,这些方法测量了增强帧和原始帧之间的PSNR和SSIM差。
PSNR)和结构相似性(SSIM)评估了我们和比较的方法,这些方法测量了增强帧和原始帧之间的PSNR和SSIM差。3.3. Comparison with state of the art
定量比较。我们将提出的方法与五种最先进的方法进行了比较,4PSSNR和4SSIM结果如表1所示。在比较的方法中,ARCNN[5]、DnCNN[6]和RNAN[7]是用于压缩图像质量增强的方法,它们独立增强每个帧,并且性能有限。MFQE 1.0[9]提出了一种新策略,即在当前帧附近寻找PQF,并从多个帧中提取更多信息。在MFQE 1.0的基础上,MFQE 2.0[10]通过使用更好的PQF检测器和QE模块,进一步提高了性能。在我们的工作中,为多帧策略开发了一种有效的金字塔形可变形结构和剩余密集网络。可以看出,与其他五种方法相比,该方法实现了更好的
PSNR和SSIM。更重要的是,对于QP 37,我们相对于MFQE 2.0的改进是MFQE 2.0相对于to MFQE 1.0的两倍。Qualitative comparison:
图2显示了5种方法的定性比较,很明显,提出的方法可以提供更高质量的增强帧。以图2中的球、伞骨和嘴巴为例,我们的方法恢复了更清晰的对象边缘和更多细节。结果表明,对于视频中快速移动的对象(如球),我们的棱锥变形结构可以更准确地补偿运动,并且在有效的QE模块和边缘增强损失的指导下,该模型在对象边缘重建和细节补充方面具有更好的性能。


3.4. Effects of the proposed module
Effects of MC module
MC模块是多帧策略的关键部分,为了更好地理解基于光流估计的MC模块和拟议的基于可变形卷积的MC模块之间的差异,我们比较了这两个模块的效果。我们分别使用光流方法和拟议的金字塔变形卷积来训练两个模型,结果如表2所示。在相同的训练策略和QE模块下,使用我们的MC模块的模型的结果具有更高的质量,表明金字塔变形卷积更可靠。
Effects of QE module:
QE模块从其输入中提取信息,进一步丰富压缩帧的细节,其输出决定了整个模型的性能。我们使用通用CNN(用于MFQE 1.0)和拟议的MRDN分别训练两个模型,这些模型使用相同的设置和相同的MC模块。表2提供了评估结果。可以看出,MRDN在
PSNR和SSIM上获得的结果比一般CNN更高。这意味着MRDN中使用的剩余密集连接有效地利用了特征信息,并且比一般CNN中使用的超大接收场具有更好的性能。4. CONCLUSION
在本文中,我们提出了一种新的用于压缩视频质量增强的多帧网络,该网络使用金字塔形可变形结构来补偿运动,并通过多帧剩余密集网络来提高压缩帧的质量。此外,还设计了一种边缘增强损耗,用于强大的边缘重建。该模型在基准数据库上实现了最先进的性能,模型大小为1.32M,比大多数比较方法都小。未来的工作重点是进一步降低计算复杂度。
-
相关阅读:
Kotlin面向对象基础使用方法(继承、接口、Lambda、空指针检查机制等)
数字化时代,数据分析到底有什么意义
JVM(二十三) -- JVM运行时参数
【GD32】GD32F303串口设置DMA发生中断无法进入中断函数
深入探索STARK的安全性和可靠性——STARKs全面安全分析
[PAT练级笔记] 31 Basic Level 1031 查验身份证
day24每日一考
从零在AutoDL调试一份目标检测代码
Leetcode 50. Pow(x, n)
关于api设计的一些思考-restful理想主义与商业需求的无解冲突
- 原文地址:https://blog.csdn.net/mytzs123/article/details/125633265