-
SIndex: A Scalable Learned Index for String Keys
学习过的索引结构改变了我们对传统数据结构设计的看法。通过机器学习(ML)技术,它们可以实现比现有索引更好的查找性能。然而,当前学习的索引主要集中在整键工作负载上,无法有效地索引可变长度的字符串键。我们引入了SIndex,这是一个并发学习的索引,专门用于变长字符串关键工作负载。为了降低模型推断和数据访问的成本,SIndex使用共享前缀对键进行分组,并使用每个键唯一的部分进行模型训练。我们使用真实数据集和合成数据集来评估SIndex。结果表明,与其他最先进的索引结构相比,SIndex的性能提高了91%。我们已经开源了我们的实现
挑战:随着key长度的增加,模型推断和数据访问的成本也会增加
方法:本文介绍了一种可扩展的学习索引SIndex,它可以有效地支持字符串键。SIndex利用常见的前缀来提高查找延迟。具体来说,SIndex贪婪地将具有公共前缀的键聚集到组中。然后,在每个组中,SIndex使用每个键的唯一部分,即部分键,来训练模型和索引数据
读者总结:文中利用基于机器学习方法实现key的index建立,因此可以学习的1)文中提出的key分组方法。在根节点使用分段线性的模型,这样有利于降低推断成本
Problem Statement:在字符串键下,它们的性能会显著下降。随着key长度的增加,XIndex的读写性能会显著下降
1)首先,随着key长度的增加,模型的计算成本急剧增加
2)But they come with unacceptable prediction cost and training cost
3)第三,二进制搜索在字符串键下也会产生很大的开销

框架:

SIndex也采用两层设计,顶层一个根节点,底层多个组节点。每个组负责存储特定键范围的记录。记录存储在一个已排序的数据数组中,使用线性模型建立索引,如果插入引入了增量索引,则使用增量索引。对于索引组,根节点存储每个组的主键,即组负责范围的下界。根利用多个线性模型来索引组。SIndex在后台不断检查所有组。如果组的增量索引大小大于用户指定的大小阈值,则SIndex执行压缩。在压缩过程中,SIndex将增量索引与旧的已排序数组合并到一个新的已排序数组中,并重新训练模型
模型的特征:
SIndex为字符串键做了三个重要的设计选择。首先,SIndex使用部分键来降低模型的计算成本和比较成本
其次,SIndex利用贪婪分组策略自适应地将键分区到不同的组中。分区后,每个组包含最大数量的键,这将使组的模型错误和部分键长度低于指定的阈值。
第三,SIndex在索引组的根节点中使用分段线性模型,而不是RMI模型
EVALUATION
我们在c++中实现了SIndex。我们将部分key的元数据存储为组元数据的一部分,包括常用的前缀长度和有效key长度。每次压缩后都会重新计算部分key。SIndex在初始化时采用贪婪分组算法
1)Overall Performance

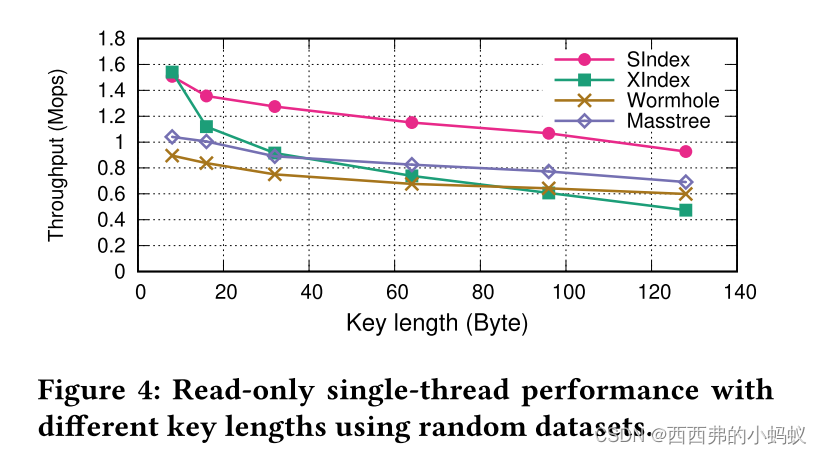

结论:
在本文中,我们提出了第一个用于字符串键的并发学习索引SIndex。为了缓解字符串键工作负载和ML方法结合带来的独特挑战,我们提出了三种创新设计:用于降低模型推断和数据访问成本的部分键,用于限制每个组中部分键长度的贪婪分组策略,以及用于重用部分键的根的分段线性模型和贪婪分组策略。我们的评估表明,在使用合成数据集和真实数据集的字符串工作负载下,SIndex能够保持具有竞争力的性能。
-
相关阅读:
【Python 千题 —— 基础篇】分句成词
自动化测试下拉框选项定位报错
新160个CrackMe分析-第2组:11-20(下)
基于Java中的SSM框架实现网上花店管理平台项目【项目源码+论文说明】
Chrome 浏览器经常卡死问题解决
ChatGPT带你飞,送3本《巧用ChatGPT快速搞定数据分析》
7 支持向量机
DeepStream系列之命令行pipeline帧率检测
monaco-editor 动态插入文本到光标处
我的四周年创作纪念日
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/125626325