-
1.30.Flink SQL案例将Kafka数据写入hive
1.30.Flink SQL案例将Kafka数据写入hive
1.30.1.1.场景,环境,配置准备
1.30.1.2.案例代码
1.30.1.2.1.编写pom.xml文件
1.30.1.2.2.Maven工程resources下编写配置文件log4j2.properties
1.30.1.2.3.Maven工程resources下编写配置文件logback.xml
1.30.1.2.4.Maven工程resources下编写配置文件project-config-test.properties
1.30.1.2.5.编写com.xxxxx.log.utils.PropertiesUtils
1.30.1.2.6.编写com.xxxxx.log.flink.handler.ExceptionLogHandlerBySql
1.30.1.2.7.执行命令1.30.Flink SQL案例将Kafka数据写入hive
1.30.1.1.场景,环境,配置准备
场景:通过Flink SQL的方式,将Kafka的数据实时写入到hive中。
(1)环境hadoop 3.1.1.3.1.4-315 hive 3.1.0.3.1.4-315 flink 1.12.1- 1
- 2
- 3
前置准备:
将以下几个包添加到$FLINK_HOME/lib,其中hive-exec-3.1.0.3.1.4.0-315.jar和libfb303-0.9.3.jar从/usr/hdp/current/hive-client/lib中拷贝
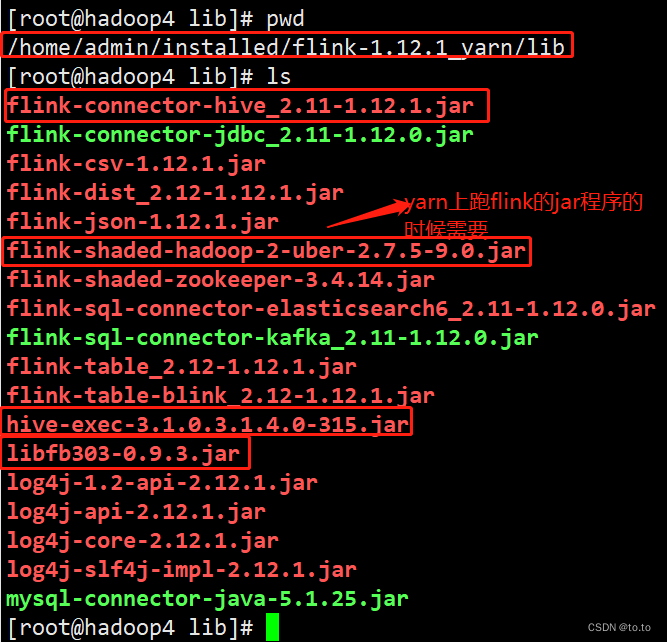
1.30.1.2.案例代码
1.30.1.2.1.编写pom.xml文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.xxxxx.zczl</groupId> <artifactId>flink-log-handler</artifactId> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!--maven properties --> <maven.test.skip>true</maven.test.skip> <maven.javadoc.skip>true</maven.javadoc.skip> <!-- compiler settings properties --> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <slf4j.version>1.7.25</slf4j.version> <fastjson.version>1.2.73</fastjson.version> <joda-time.version>2.9.4</joda-time.version> <flink.version>1.12.1</flink.version> <scala.binary.version>2.11</scala.binary.version> <hive.version>3.1.2</hive.version> <hadoop.version>3.1.4</hadoop.version> <!-- <hive.version>3.1.0.3.1.4.0-315</hive.version> <hadoop.version>3.1.1.3.1.4.0-315</hadoop.version>--> <!--<hadoop.version>3.3.0</hadoop.version>--> <mysql.connector.java>8.0.22</mysql.connector.java> <fileName>flink-log-handler</fileName> <!--<mainClass>com.xxxxx.issue.flink.handler.IssueHandleFlinkHandlerByCustomRedisSink</mainClass>--> </properties> <version>1.0-SNAPSHOT</version> <!--<distributionManagement> <repository> <id>releases</id> <layout>default</layout> <url>http://nexus.xxxxx.cn/nexus/content/repositories/releases/</url> </repository> <snapshotRepository> <id>snapshots</id> <name>snapshots</name> <url>http://nexus.xxxxx.cn/nexus/content/repositories/snapshots/</url> </snapshotRepository> </distributionManagement>--> <repositories> <!-- <repository> <id>releases</id> <layout>default</layout> <url>http://nexus.xxxxx.cn/nexus/content/repositories/releases/</url> </repository> <repository> <id>snapshots</id> <name>snapshots</name> <url>http://nexus.xxxxx.cn/nexus/content/repositories/snapshots/</url> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> <checksumPolicy>warn</checksumPolicy> </snapshots> </repository> <repository> <id>xxxxx</id> <name>xxxxx</name> <url>http://nexus.xxxxx.cn/nexus/content/repositories/xxxxx/</url> </repository> <repository> <id>public</id> <name>public</name> <url>http://nexus.xxxxx.cn/nexus/content/groups/public/</url> </repository>--> <!-- 新加 --> <repository> <id>cloudera</id> <layout>default</layout> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <!-- <repositories> <!– Cloudera –> <repository> <id>cloudera-releases</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> <!– Hortonworks –> <repository> <id>HDPReleases</id> <name>HDP Releases</name> <url>https://repo.hortonworks.com/content/repositories/releases/</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> <repository> <id>HortonworksJettyHadoop</id> <name>HDP Jetty</name> <url>https://repo.hortonworks.com/content/repositories/jetty-hadoop</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> <!– MapR –> <repository> <id>mapr-releases</id> <url>https://repository.mapr.com/maven/</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> </repositories>--> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <!-- flink以yarn模式启动,执行flink->sql->hive会用到flink-shaded-hadoop-2-uber包 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-shaded-hadoop-2-uber</artifactId> <version>2.7.5-9.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-sequence-file</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!-- <scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.connector.java}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-hive_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>${flink.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>${hive.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-metastore</artifactId> <version>${hive.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>${hive.version}</version> <!--<scope>compile</scope>--> <scope>provided</scope> </dependency> <!-- <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.9.1</version> <scope>provided</scope> </dependency>--> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>${joda-time.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>${fastjson.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>test</scope> </dependency> </dependencies> <build> <finalName>${fileName}</finalName> <plugins> <!-- 编译插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>${maven.compiler.source}</source> <target>${maven.compiler.target}</target> <encoding>${project.build.sourceEncoding}</encoding> <compilerVersion>${maven.compiler.source}</compilerVersion> <showDeprecation>true</showDeprecation> <showWarnings>true</showWarnings> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.12.4</version> <configuration> <skipTests>${maven.test.skip}</skipTests> </configuration> </plugin> <plugin> <groupId>org.apache.rat</groupId> <artifactId>apache-rat-plugin</artifactId> <version>0.12</version> <configuration> <excludes> <exclude>README.md</exclude> </excludes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-javadoc-plugin</artifactId> <version>2.10.4</version> <configuration> <aggregate>true</aggregate> <reportOutputDirectory>javadocs</reportOutputDirectory> <locale>en</locale> </configuration> </plugin> <!-- scala编译插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.1.6</version> <configuration> <scalaCompatVersion>2.11</scalaCompatVersion> <scalaVersion>2.11.12</scalaVersion> <encoding>UTF-8</encoding> </configuration> <executions> <execution> <id>compile-scala</id> <phase>compile</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>test-compile-scala</id> <phase>test-compile</phase> <goals> <goal>add-source</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!-- 打jar包插件(会包含所有依赖) --> <plugin> <!--<groupId>org.apache.maven.plugins</groupId>--> <artifactId>maven-assembly-plugin</artifactId> <!--<version>2.6</version>--> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <!--<archive> <manifest> <mainClass>${mainClass}</mainClass> </manifest> </archive>--> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
1.30.1.2.2.Maven工程resources下编写配置文件log4j2.properties
具体内容如下:
rootLogger.level = ERROR rootLogger.appenderRef.console.ref = ConsoleAppender appender.console.name = ConsoleAppender appender.console.type = CONSOLE appender.console.layout.type = PatternLayout appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.30.1.2.3.Maven工程resources下编写配置文件logback.xml
<configuration> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{60} %X{sourceThread} - %msg%n</pattern> </encoder> </appender> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- Daily rollover --> <fileNamePattern>log/generator.%d{yyyy-MM-dd}.log</fileNamePattern> <!-- Keep 7 days' worth of history --> <maxHistory>7</maxHistory> </rollingPolicy> <encoder> <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern> </encoder> </appender> <root level="ERROR"> <appender-ref ref="FILE" /> <appender-ref ref="STDOUT" /> </root> </configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
1.30.1.2.4.Maven工程resources下编写配置文件project-config-test.properties
# 测试环境 ####################################业务方kafka相关配置 start########################################### kafka.bootstrap.servers=xxx.xxx.xxx.xxx:9094 # 消费者配置 kafka.consumer.group.id=logkit kafka.consumer.enableAutoCommit=true kafka.consumer.autoCommitInterval=1000 kafka.consumer.key.deserializer=org.apache.kafka.common.serialization.StringDeserializer kafka.consumer.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer # 主题 kafka.exception.topic=lk_exception_log_statistics kafka.log.topic=lk_log_info_statistics ####################################flink相关配置 start########################################### # 间隔5s产生checkpoing flink.checkpoint.interval=5000 # 确保检查点之间有至少1000 ms的间隔(可以把这个注释掉:提高checkpoint的写速度===todo===) flink.checkpoint.minPauseBetweenCheckpoints=1000 # 检查点必须在1min内完成,或者被丢弃【checkpoint的超时时间】 flink.checkpoint.checkpointTimeout=60000 # 同一时间只允许进行一个检查点 flink.checkpoint.maxConcurrentCheckpoints=3 # 尝试重启次数 flink.fixedDelayRestart.times=3 # 每次尝试重启时之间的时间间隔 flink.fixedDelayRestart.interval=5 ####################################source和sink # kafka source读并发 flink.kafka.source.parallelism=1 # hive下沉的并发 flink.hive.sink.parallelism=1 #hive.conf=/usr/hdp/current/hive-client/conf hive.conf=/usr/hdp/3.1.4.0-315/hive/conf/ hive.zhoushan.database=xxxx_158- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
1.30.1.2.5.编写com.xxxxx.log.utils.PropertiesUtils
package com.xxxxx.log.utils; import java.io.IOException; import java.io.InputStream; import java.util.Properties; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public final class PropertiesUtils { private static Logger logger = LoggerFactory.getLogger(PropertiesUtils.class); private static PropertiesUtils instance = null; /** 间隔xxx秒产生checkpoing **/ private Integer flinkCheckpointsInterval = null; /** 确保检查点之间有至少xxx ms的间隔 **/ private Integer flinkMinPauseBetweenCheckpoints = null; /** 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 **/ private Integer flinkCheckpointTimeout = null; /** 同一时间只允许进行一个检查点 **/ private Integer flinkMaxConcurrentCheckpoints = null; /** 尝试重启次数 **/ private Integer flinkFixedDelayRestartTimes = null; /** 每次尝试重启时之间的时间间隔 **/ private Integer flinkFixedDelayRestartInterval = null; /** kafka source 的并行度 **/ private Integer kafkaSourceParallelism = null; /** hive sink 的并行度 **/ private Integer hiveSinkParallelism = null; /** kafka集群 **/ private String kafkServer = null; /** 消费者组id **/ private String groupId = null; private Boolean enableAutoCommit = null; private Long autoCommitInterval = null; private String keyDeserializer = null; private String valueDeserializer = null; private String exceptionTopic = null; private String logTopic = null; private String hiveConf = null; private String database = null; /** * 静态代码块 */ private PropertiesUtils() { InputStream in = null; try { // 读取配置文件,通过类加载器的方式读取属性文件 in = PropertiesUtils.class.getClassLoader().getResourceAsStream("project-config-test.properties"); // in = PropertiesUtils.class.getClassLoader().getResourceAsStream("test-win10.properties"); // in = PropertiesUtils.class.getClassLoader().getResourceAsStream("test-linux.properties"); Properties prop = new Properties(); prop.load(in); // flink配置 flinkCheckpointsInterval = Integer.parseInt(prop.getProperty("flink.checkpoint.interval").trim()); flinkMinPauseBetweenCheckpoints = Integer.parseInt(prop.getProperty("flink.checkpoint.minPauseBetweenCheckpoints").trim()); flinkCheckpointTimeout = Integer.parseInt(prop.getProperty("flink.checkpoint.checkpointTimeout").trim()); flinkMaxConcurrentCheckpoints = Integer.parseInt(prop.getProperty("flink.checkpoint.maxConcurrentCheckpoints").trim()); flinkFixedDelayRestartTimes = Integer.parseInt(prop.getProperty("flink.fixedDelayRestart.times").trim()); flinkFixedDelayRestartInterval = Integer.parseInt(prop.getProperty("flink.fixedDelayRestart.interval").trim()); kafkaSourceParallelism = Integer.parseInt(prop.getProperty("flink.kafka.source.parallelism").trim()); hiveSinkParallelism = Integer.parseInt(prop.getProperty("flink.hive.sink.parallelism").trim()); // kafka配置 kafkServer = prop.getProperty("kafka.bootstrap.servers").trim(); groupId = prop.getProperty("kafka.consumer.group.id").trim(); enableAutoCommit = Boolean.valueOf(prop.getProperty("kafka.consumer.enableAutoCommit").trim()); autoCommitInterval = Long.valueOf(prop.getProperty("kafka.consumer.autoCommitInterval").trim()); keyDeserializer = prop.getProperty("kafka.consumer.key.deserializer").trim(); valueDeserializer = prop.getProperty("kafka.consumer.value.deserializer").trim(); exceptionTopic = prop.getProperty("kafka.exception.topic").trim(); logTopic = prop.getProperty("kafka.log.topic").trim(); hiveConf = prop.getProperty("hive.conf").trim(); database = prop.getProperty("hive.zhoushan.database").trim(); } catch (Exception e) { throw new ExceptionInInitializerError(e); } finally { try { if (in != null) { in.close(); } } catch (IOException e) { e.printStackTrace(); logger.error("流关闭失败"); } } } public static PropertiesUtils getInstance() { if (instance == null) { instance = new PropertiesUtils(); } return instance; } public Integer getFlinkCheckpointsInterval() { return flinkCheckpointsInterval; } public Integer getFlinkMinPauseBetweenCheckpoints() { return flinkMinPauseBetweenCheckpoints; } public Integer getFlinkCheckpointTimeout() { return flinkCheckpointTimeout; } public Integer getFlinkMaxConcurrentCheckpoints() { return flinkMaxConcurrentCheckpoints; } public Integer getFlinkFixedDelayRestartTimes() { return flinkFixedDelayRestartTimes; } public Integer getFlinkFixedDelayRestartInterval() { return flinkFixedDelayRestartInterval; } public Integer getKafkaSourceParallelism() { return kafkaSourceParallelism; } public Integer getHiveSinkParallelism() { return hiveSinkParallelism; } public String getKafkServer() { return kafkServer; } public String getGroupId() { return groupId; } public Boolean getEnableAutoCommit() { return enableAutoCommit; } public Long getAutoCommitInterval() { return autoCommitInterval; } public String getKeyDeserializer() { return keyDeserializer; } public String getValueDeserializer() { return valueDeserializer; } public String getExceptionTopic() { return exceptionTopic; } public String getLogTopic() { return logTopic; } public String getHiveConf() { return hiveConf; } public String getDatabase() { return database; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
1.30.1.2.6.编写com.xxxxx.log.flink.handler.ExceptionLogHandlerBySql
具体内容是:
package com.xxxxx.log.flink.handler; import java.util.concurrent.TimeUnit; import org.apache.flink.api.common.restartstrategy.RestartStrategies; import org.apache.flink.api.common.time.Time; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.TimeCharacteristic; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.SqlDialect; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.table.catalog.hive.HiveCatalog; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.xxxxx.log.utils.PropertiesUtils; public class ExceptionLogHandlerBySql { private static final Logger logger = LoggerFactory.getLogger(ExceptionLogHandlerBySql.class); public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); PropertiesUtils instance = PropertiesUtils.getInstance(); //重启策略之固定间隔 (Fixed delay) env.setRestartStrategy(RestartStrategies.fixedDelayRestart(instance.getFlinkFixedDelayRestartTimes(), Time.of(instance.getFlinkFixedDelayRestartInterval(), TimeUnit.MINUTES))); //设置间隔多长时间产生checkpoint env.enableCheckpointing(instance.getFlinkCheckpointsInterval()); //设置模式为exactly-once (这是默认值) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】 // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(instance.getFlinkMinPauseBetweenCheckpoints()); //检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】 env.getCheckpointConfig().setCheckpointTimeout(instance.getFlinkCheckpointTimeout()); //同一时间只允许进行一个检查点 env.getCheckpointConfig().setMaxConcurrentCheckpoints(instance.getFlinkMaxConcurrentCheckpoints()); // 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】 env.getCheckpointConfig() .enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env.setParallelism(1); // flink table EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings); // 构造 kafka source, 用 DEFAULT tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT); String sourceDrop = "drop table if exists kafka_exception"; String sourceTable = "CREATE TABLE kafka_exception (" + " serviceId STRING," + " serverName STRING," + " serverIp STRING," + " title STRING," + " operationPath STRING," + " url STRING," + " stack STRING," + " exceptionName STRING," + " exceptionInfo STRING," + " operationUser STRING," + " operationIp STRING," + " orgId BIGINT," + " methodClass STRING," + " fileName STRING," + " methodName STRING," + " operationData STRING," + " occurrenceTime BIGINT" + ") WITH (" + " 'connector' = 'kafka'," + " 'topic' = '" + instance.getExceptionTopic() + "'," + " 'properties.bootstrap.servers' = '" + instance.getKafkServer() + "'," + " 'properties.group.id' = '" + instance.getGroupId() + "'," + " 'scan.startup.mode' = 'earliest-offset'," + " 'format' = 'json'," + " 'json.fail-on-missing-field' = 'false'," + " 'json.ignore-parse-errors' = 'true'" + " )"; System.out.println("=================sourcesql打印开始========================"); tableEnv.executeSql(sourceDrop); tableEnv.executeSql(sourceTable); System.out.println(sourceTable); System.out.println("=================sourcesql打印结束========================"); // 构造 hive catalog(这个可以任意编写) String name = "mycatalog"; String defaultDatabase = instance.getDatabase(); String hiveConfDir = instance.getHiveConf(); HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir); tableEnv.registerCatalog(name, hive); tableEnv.useCatalog(name); // hive sink tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE); tableEnv.useDatabase(defaultDatabase); String sinkDrop = "drop table if exists hive_exception"; String sinkTable = "CREATE TABLE hive_exception (" + " service_id STRING," + " server_name STRING," + " server_ip STRING," + " title STRING," + " operation_path STRING," + " url STRING," + " stack STRING," + " exception_name STRING," + " exception_info STRING," + " operation_user STRING," + " operation_ip STRING," + " org_id BIGINT," + " method_class STRING," + " file_name STRING," + " method_name STRING," + " operation_data STRING," + " occurrence_time String" + " ) PARTITIONED BY (dt STRING) STORED AS parquet TBLPROPERTIES (" + " 'partition.time-extractor.timestamp-pattern'='$dt 00:00:00'," + " 'sink.partition-commit.trigger'='process-time'," + " 'sink.partition-commit.delay'='0 s'," + " 'sink.partition-commit.policy.kind'='metastore,success-file'" + ")"; System.out.println("=================sinksql打印开始========================"); tableEnv.executeSql(sinkDrop); tableEnv.executeSql(sinkTable); System.out.println(sinkTable); System.out.println("=================sinksql打印结束========================"); String sql = "INSERT INTO TABLE hive_exception" + " SELECT serviceId, serverName, serverIp, title, operationPath, url, stack, exceptionName, exceptionInfo, operationUser, operationIp," + " orgId, methodClass, fileName, methodName, operationData, from_unixtime(cast(occurrenceTime/1000 as bigint),'yyyy-MM-dd HH:mm:ss'), from_unixtime(cast(occurrenceTime/1000 as bigint),'yyyy-MM-dd')" + " FROM kafka_exception"; tableEnv.executeSql(sql); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
1.30.1.2.7.执行命令
第一种:standalone模式
$FLINK_HOME/bin/flink run \ -c com.xxxxx.log.flink.handler.ExceptionLogHandlerBySql \ /root/cf_temp/flink-log-handler.jar- 1
- 2
- 3
第二种:cluster-yarn
$FLINK_HOME/bin/flink run -d -m yarn-cluster \ -yqu real_time_processing_queue \ -p 1 -yjm 1024m -ytm 1024m -ynm ExceptionLogHandler \ -c com.xxxxx.log.flink.handler.ExceptionLogHandlerBySql \ /root/cf_temp/flink-log-handler.jar- 1
- 2
- 3
- 4
- 5
第三种:yarn-session(这个需要先提交到yarn获取对应的application_id,所以这个没测试)
$FLINK_HOME/bin/yarn-session.sh -d -nm yarnsession01 -n 2 -s 3 -jm 1024m -tm 2048m- 1
$FLINK_HOME/bin/flink run -d -yid application_1603447441975_0034 \ -c com.xxxxx.log.flink.handler.ExceptionLogHandlerBySql \ /root/cf_temp/flink-log-handler.jar ExceptionLogSession \- 1
- 2
- 3
Json格式:
{"serviceId":"test000","serverName":"xxx","serverIp":"xxx.xxx.xxx.xxx","title":"xxxx","operationPath":"/usr/currunt","url":"http://baidu.com","stack":"xxx","exceptionName":"xxxx","exceptionInfo":"xxxx","operationUser":"chenfeng","operationIp":"xxx.xxx.xxx.xxx","orgId":777777,"methodClass":"com.xxxxx.Test","fileName":"test.txt","methodName":"findname","operationData":"name=kk","occurrenceTime":"2021-05-12 09:23:20"}- 1
-
相关阅读:
浏览器插件实现国税网自动登录,以及解决浏览器记住密码会自动填充表单无法修改的问题
Oracle设置日志参数-ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
数学建模学习(93):方差分析、T检验、卡方分析(检验)
【kali-密码攻击】(5.1.1)密码在线破解:Hydra(图形界面)
亲戚小孩月薪17k,而我只有4k+,好慌......
在 CentOS 7 上安装中文字体
3个g的文件怎么发送给别人?三种方法自由选择!
9/15(实习)一面
“因此在此系统上禁止运行脚本” 解决方案
二、EFCore 数据库表的创建和迁移
- 原文地址:https://blog.csdn.net/toto1297488504/article/details/125626651