-
【JVM调优实战100例】04——方法区调优实战(上)
前 言
🍉 作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:实战案例驱动介绍JVM知识,教你用JVM排除故障、评估代码、优化性能
🌰 文章简介:介绍方法区概念、帮助你深入理解常量池、String table调优等7.方法区
7.1 定义
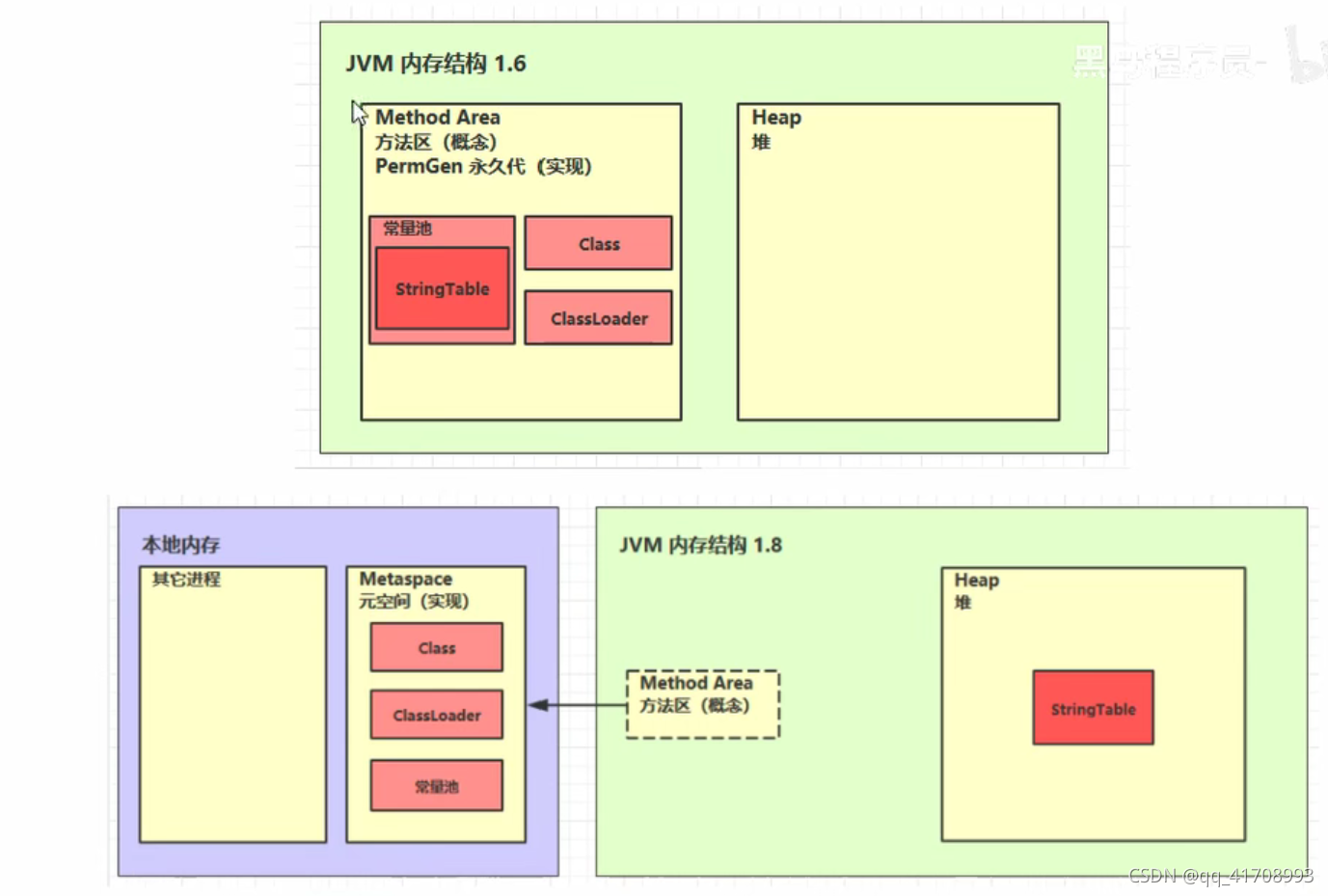
方法区是java虚拟机中所有线程共享的共享区域,主要存放类的结构相关信息(成员变量,方法、构造器的代码),运行时常量池,类加载器。方法区在虚拟机启动时被创建,在逻辑上属于堆的组成部分(具体产商实现时不一定遵守逻辑上的划分标准)。
在jdk1.8以前,方法区位于jvm的永久代,字符串存放在常量池。在jdk1.8以后,方法区则位于本地内存的元空间,不再占用JVM的内存空间,而字符串存在于堆。具体参考下图。
💡Tip:
方法区其实是逻辑上的概念,因为您可以发现,在jdk1.8以后,他甚至在物理存储空间上是拆分开的。7.2 方法区内存溢出
通过下面代码可以演示方法区内存溢出。
public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码 public static void main(String[] args) { int j = 0; try { Demo1_8 test = new Demo1_8(); for (int i = 0; i < 10000; i++, j++) { // ClassWriter 作用是生成类的二进制字节码 ClassWriter cw = new ClassWriter(0); // 参数含义:版本号, 访问级别为public, 类名, 包名, 父类, 接口 cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); // 返回 byte[] byte[] code = cw.toByteArray(); // 执行了类的加载 test.defineClass("Class" + i, code, 0, code.length); // Class 对象 } } finally { System.out.println(j); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在jdk1.8以前的版本,将永久代设置为8m:
-XX:MaxPermSize=10m,在jdk1.8以后,将元空间设置为8m:-XX:MaxMetaspaceSize=8m,将会报出OutOfMemoryError.在实际的工作场景中,spring、mybatis等框架都使用了cglib来动态生成class,因此框架使用不当是可能导致方法区内存溢出的。不过在jdk1.8以后方法区移到了元空间,空间充裕了很多,也由元空间进行垃圾回收,内存溢出的可能降低了。
7.3 常量池
下面是一个helloworld的代码。
// 二进制字节码(类基本信息,常量池,类方法定义,包含了虚拟机指令) public class HelloWorld { public static void main(String[] args) { System.out.println("hello world"); } }- 1
- 2
- 3
- 4
- 5
- 6
计算机最终会把这段代码转换为二进制代码后执行,这段二进制代码包含类基本信息、类方法定义(包含指令)、常量池。我们切换到out路径下对应的class文件所在目录,使用反编译命令
javap -v xxx.class将二进制代码的内容转为可读的代码一探究竟。Classfile /F:/资料 解密JVM/代码/jvm/out/production/jvm/cn/itcast/jvm/t5/helloworld.class Last modified 2021年9月9日; size 567 bytes SHA-256 checksum 37204bf6e654f64ae56660a1e8becfaa98b3ae7592b81b4b6e331de92a460b96 Compiled from "HelloWorld.java" public class cn.itcast.jvm.t5.HelloWorld minor version: 0 major version: 52 flags: (0x0021) ACC_PUBLIC, ACC_SUPER this_class: #5 // cn/itcast/jvm/t5/HelloWorld super_class: #6 // java/lang/Object interfaces: 0, fields: 0, methods: 2, attributes: 1 Constant pool: #1 = Methodref #6.#20 // java/lang/Object."<init>":()V #2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream; #3 = String #23 // hello world #4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V #5 = Class #26 // cn/itcast/jvm/t5/HelloWorld #6 = Class #27 // java/lang/Object #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 Lcn/itcast/jvm/t5/HelloWorld; #14 = Utf8 main #15 = Utf8 ([Ljava/lang/String;)V #16 = Utf8 args #17 = Utf8 [Ljava/lang/String; #18 = Utf8 SourceFile #19 = Utf8 HelloWorld.java #20 = NameAndType #7:#8 // "<init>":()V #21 = Class #28 // java/lang/System #22 = NameAndType #29:#30 // out:Ljava/io/PrintStream; #23 = Utf8 hello world #24 = Class #31 // java/io/PrintStream #25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V #26 = Utf8 cn/itcast/jvm/t5/HelloWorld #27 = Utf8 java/lang/Object #28 = Utf8 java/lang/System #29 = Utf8 out #30 = Utf8 Ljava/io/PrintStream; #31 = Utf8 java/io/PrintStream #32 = Utf8 println #33 = Utf8 (Ljava/lang/String;)V { public cn.itcast.jvm.t5.HelloWorld(); descriptor: ()V flags: (0x0001) ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 4: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Lcn/itcast/jvm/t5/HelloWorld; public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: (0x0009) ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=1, args_size=1 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 3: ldc #3 // String hello world 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 8: return LineNumberTable: line 6: 0 line 7: 8 LocalVariableTable: Start Length Slot Name Signature 0 9 0 args [Ljava/lang/String; } SourceFile: "HelloWorld.java"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
如上,常量池原来就是一张常量表。注意到其中方法定义部分如
#2等内容,这其实就对应着常量池(表)Constant pool的常量。常量池是.class文件中的,当类被加载时,常量池的内容就会被放入运行时常量池,并且其中的符号地址将会变为真实地址。
7.4 String table
下面看一个面试题。
String s1 = "a"; String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2; String s5 = "a" + "b"; System.out.println(s3 == s4); System.out.println(s3 == s4);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
要回答这个问题,需要搞清楚string table,先从最简单的说起,反编译下列代码。
public class Demo1_22 { public static void main(String[] args) { String s1 = "a"; // 懒惰的 String s2 = "b"; String s3 = "ab"; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
截取部分。可以看到jvm从
#2取String a存放到了LocalVariableTable的Slot1,其他串与此类似。public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: (0x0009) ACC_PUBLIC, ACC_STATIC Code: stack=1, locals=4, args_size=1 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: return LineNumberTable: line 11: 0 line 12: 3 line 13: 6 line 21: 9 LocalVariableTable: Start Length Slot Name Signature 0 10 0 args [Ljava/lang/String; 3 7 1 s1 Ljava/lang/String; 6 4 2 s2 Ljava/lang/String; 9 1 3 s3 Ljava/lang/String;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在jvm启动时,常量池中的内容都会加载到运行时常量池中,但是此时a,b,ab都还只是一个符号,而不是字符串对象。只有当执行到具体的指令,如
0: ldc #2才会创建字符串对象"a"。于此同时,jvm还会去String table[]中去找是否有"a"这个字符串,如果没有则将其加入String table[]。注:String table[]其实是hashtable 结构,不能扩容。在java代码中新增s4,并反编译。
String s4 = s1 + s2;- 1
反编译结果如下。
9: new #5 // class java/lang/StringBuilder 12: dup 13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V 16: aload_1 17: invokevirtual #7 // Method java/lang/StringBuilder.append(Ljava/lang/String;)Ljava/lang/StringBuilder; 20: aload_2 21: invokevirtual #7 // Method java/lang/StringBuilder.append(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
以上操作等同于。
new StringBuilder().append("a").append("b").toString()- 1
其中
toString()的方法实现方式是:new String("ab")。所以s3 == s4的结果为fasle.System.out.println(s3 == s4); //false- 1
接着我们在代码中新增s5.
String s5 = "a" + "b";- 1
反编译结果如下。
29: ldc #4 // String ab 31: astore 5- 1
- 2
原来,javac编译时帮助我们进行了优化, 它认为“a”,“b”是常量,结果不可能会发生改变,于是结果直接在编译期确定为ab了。并且,由于"ab"在String table中已经存在,因此不会创建新的字符串对象了。
System.out.println(s3 == s4); //true- 1
intern()方法可以把堆中的字符串对象放入串中,参考以下代码。
public class Demo1_23 { // String table["ab", "a", "b"] public static void main(String[] args) { String x = "ab"; String s = new String("a") + new String("b"); // 堆 new String("a") new String("b") new String("ab") String s2 = s.intern();//将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回 System.out.println( s2 == x); //true,s2与x都是串池中的对象 System.out.println( s == x ); //false,s是堆中的对象,与串池中的对象是不同的对象 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面这种情况x2可以成功加入串池,因此结果为true。
String x2 = new String("c") + new String("d"); // new String("cd") x2.intern(); String x1 = "cd"; System.out.println(x1 == x2); //true- 1
- 2
- 3
- 4
不过jdk1.6中调用intern()方法,会将字符串尝试放入串池,如果有则不会放入,如果没有则会复制一份放入串池,因此,串池中的对象与堆中的对象并不是同一个对象。上面同样的代码再jdk1.6中
x1 == x2返回false。串池的特点总结如下。

7.5 String table的位置
在jdk1.6,string table置于常量池,而常量池位于永久代的方法区中。永久代只有full gc触发时才会进行回收,这就导致string table的回收效率低。jdk1.7将string table移到了堆中。
7.6 String table的垃圾回收
参考以下代码配置参数并运行。
/** * 演示 StringTable 垃圾回收 * -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc */ public class Demo1_7 { public static void main(String[] args) throws InterruptedException { int i = 0; try { for (int j = 0; j < 100000; j++) { // j=100, j=10000 String.valueOf(j).intern(); i++; } } catch (Throwable e) { e.printStackTrace(); } finally { System.out.println(i); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
打印信息如下
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->875K(9728K), 0.0028226 secs] [Times: user=0.02 sys=0.00, real=0.01 secs] [GC (Allocation Failure) [PSYoungGen: 2536K->512K(2560K)] 2923K->958K(9728K), 0.0039494 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC (Allocation Failure) [PSYoungGen: 2560K->512K(2560K)] 3006K->1006K(9728K), 0.0020900 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] ... StringTable statistics: Number of buckets : 60013 = 480104 bytes, avg 8.000 Number of entries : 26231 = 629544 bytes, avg 24.000 Number of literals : 26231 = 1548152 bytes, avg 59.020 Total footprint : = 2657800 bytes Average bucket size : 0.437 Variance of bucket size : 0.418 Std. dev. of bucket size: 0.646 Maximum bucket size : 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
string table底层是hashtable,是采用数组加链表的形式存储数据,可以看到存储字符串的桶的数量为60013个,字符串的数量为26231个。我们实际上创建的字符串个数是10 0000个,为什么打印出来的数量不符合呢?根据打印信息,原来是因为触发了GC操作。
7.7 String table调优
string table的本质是hashtable,而hashtable的性能和桶的个数密切相关,对于string table进行调优其实就是要对hashtable的桶的个数进行调节。
/** * 演示串池大小对性能的影响 * -XX:+PrintStringTableStatistics */ public class Demo1_24 { public static void main(String[] args) throws IOException { try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) { String line = null; long start = System.nanoTime(); while (true) { line = reader.readLine(); if (line == null) { break; } line.intern(); } System.out.println("cost:" + (System.nanoTime() - start) / 1000000); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
配置并运行上列代码,打印信息如下。
cost:439 SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 13697 = 328728 bytes, avg 24.000 Number of literals : 13697 = 609024 bytes, avg 44.464 Total footprint : = 1097840 bytes Average bucket size : 0.684 Variance of bucket size : 0.684 Std. dev. of bucket size: 0.827 Maximum bucket size : 6 StringTable statistics: Number of buckets : 60013 = 480104 bytes, avg 8.000 Number of entries : 481494 = 11555856 bytes, avg 24.000 Number of literals : 481494 = 29750344 bytes, avg 61.788 Total footprint : = 41786304 bytes Average bucket size : 8.023 Variance of bucket size : 8.084 Std. dev. of bucket size: 2.843 Maximum bucket size : 23- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
配置参数
-XX:StringTableSize=200000,打印信息如下。cost:393 SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 13697 = 328728 bytes, avg 24.000 Number of literals : 13697 = 609024 bytes, avg 44.464 Total footprint : = 1097840 bytes Average bucket size : 0.684 Variance of bucket size : 0.684 Std. dev. of bucket size: 0.827 Maximum bucket size : 6 StringTable statistics: Number of buckets : 200000 = 1600000 bytes, avg 8.000 Number of entries : 481494 = 11555856 bytes, avg 24.000 Number of literals : 481494 = 29750344 bytes, avg 61.788 Total footprint : = 42906200 bytes Average bucket size : 2.407 Variance of bucket size : 2.420 Std. dev. of bucket size: 1.556 Maximum bucket size : 12- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
配置参数
-XX:StringTableSize=1009,打印信息如下。cost:4870 SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 16327 = 391848 bytes, avg 24.000 Number of literals : 16327 = 698456 bytes, avg 42.779 Total footprint : = 1250392 bytes Average bucket size : 0.816 Variance of bucket size : 0.811 Std. dev. of bucket size: 0.901 Maximum bucket size : 6 StringTable statistics: Number of buckets : 1009 = 8072 bytes, avg 8.000 Number of entries : 482764 = 11586336 bytes, avg 24.000 Number of literals : 482764 = 29845512 bytes, avg 61.822 Total footprint : = 41439920 bytes Average bucket size : 478.458 Variance of bucket size : 432.042 Std. dev. of bucket size: 20.786 Maximum bucket size : 547- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
可以发现,当桶的数量更多时,哈希冲突的可能性会减少,这样入池的时间会更少。
为什么要使用string table来存储字符串呢?因为这样可以节省空间,避免重复创建字符串对象。网络上流传twitter中存储用户信息包含地址项,如果不使用string table存储,需要约30G内存,但是这些地址可能包含大量重复地址,可能很多个用户都是来自于北京市中关村,于是twitter将地址信息入池,由string table创建存储,将这个内存空间降低至数十M。
通过下面实例来感受这一过程。
/** * 演示 intern 减少内存占用 * -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics * -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000 */ public class Demo1_25 { public static void main(String[] args) throws IOException { List<String> address = new ArrayList<>(); System.in.read(); for (int i = 0; i < 10; i++) { try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) { String line = null; long start = System.nanoTime(); while (true) { line = reader.readLine(); if(line == null) { break; } address.add(line); } System.out.println("cost:" +(System.nanoTime()-start)/1000000); } } System.in.read(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
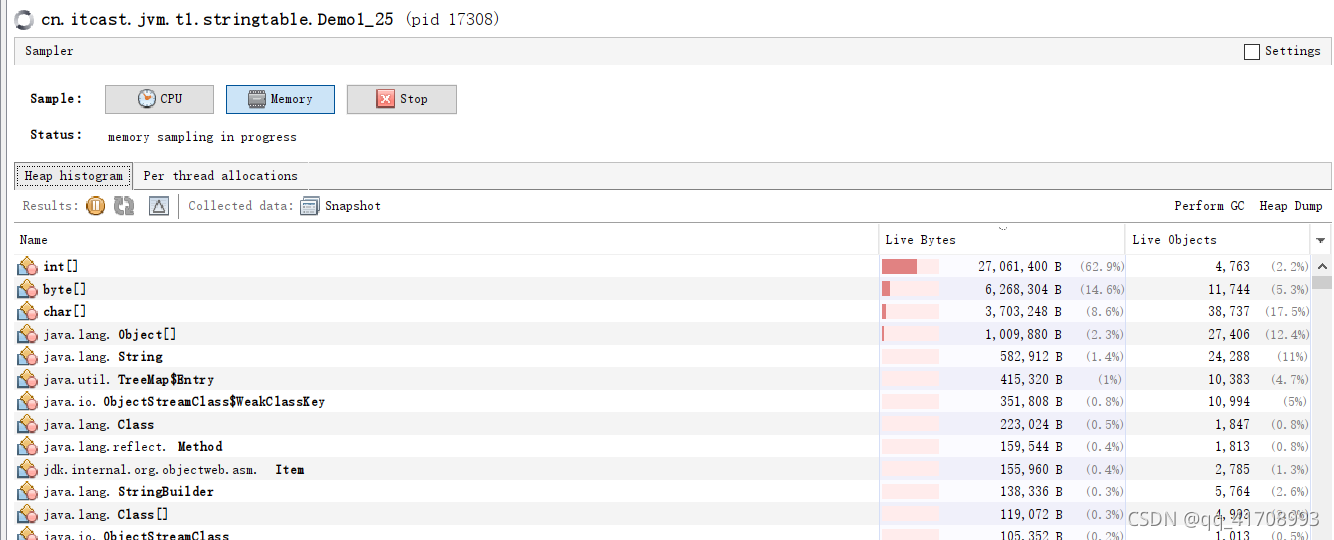
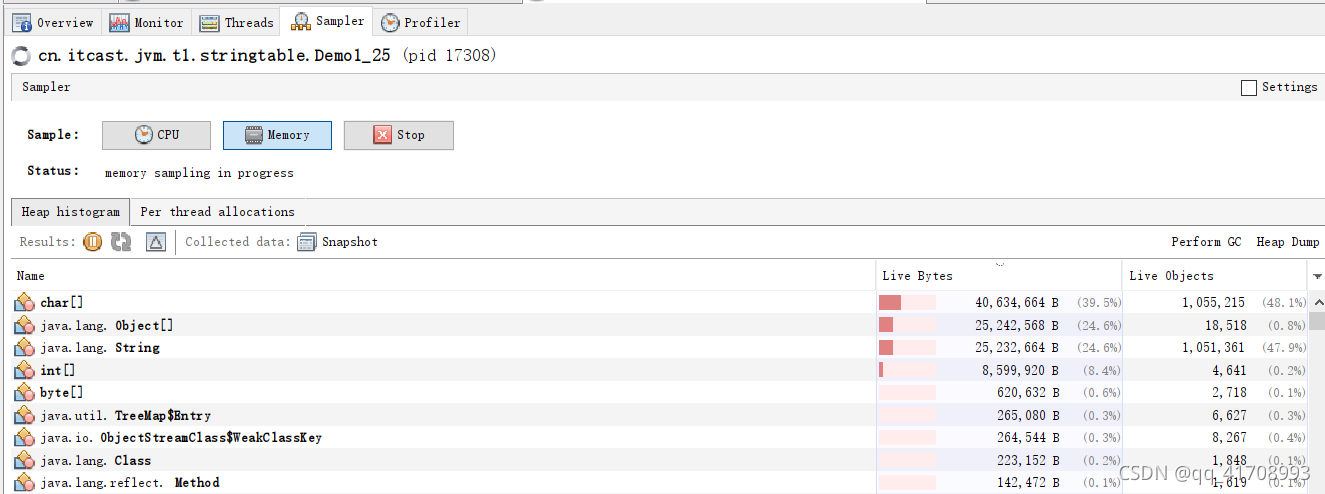
在键盘键入前,没有读进行数据读取操作,键入后则进行了数据读取并存入了address中。在这两个时间节点采用jvisualvm中sampler进行取样。结果如下。
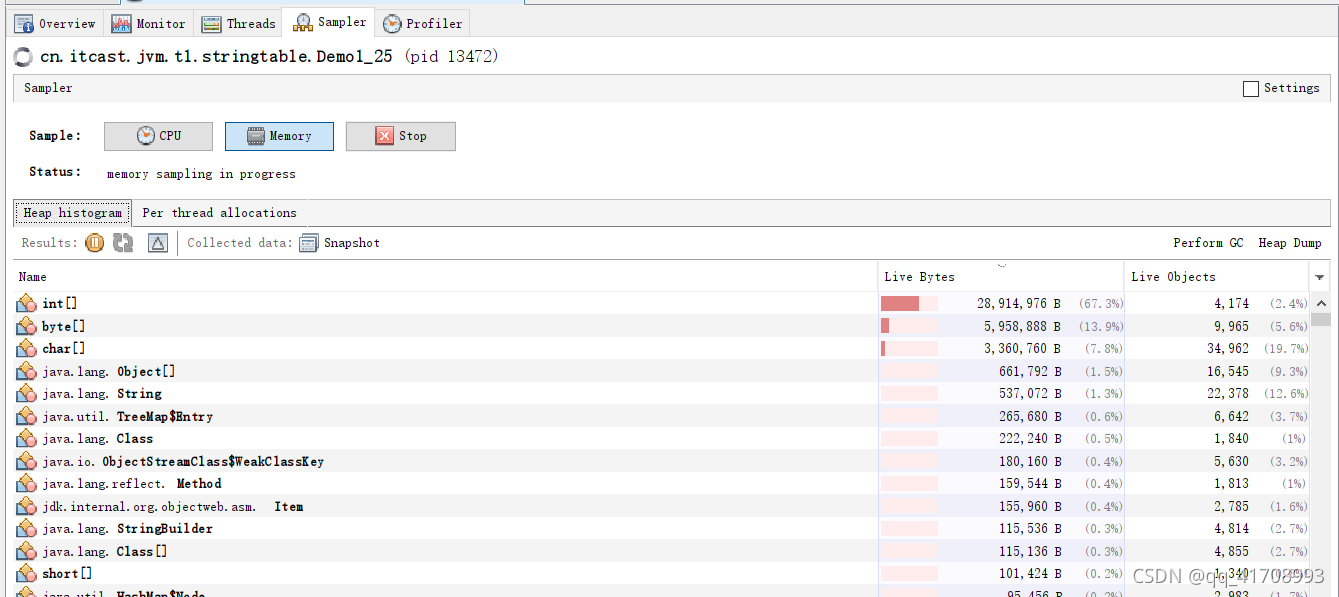

修改代码
address.add()address.add(line.intern());- 1
-
相关阅读:
【大模型的一些基本结论】
新品怎么才能高效率地上一些攻心评价
webpack中polyfill和runtime的区别,ES stage的含义,preset–env的作用
Vue.js核心技术解析与uni-app跨平台实战开发学习笔记 第4章 Vue.js动画 4.1 Vue单组动画
ChIP-Seq,MeRIP-seq峰(peak),eccDNA等染色体分布可视化
Ubuntu18.04虚拟机磁盘扩容-lvm
Python排序算法
JavaWeb之Listener监听器
加拿大AI医疗技术公司【FluidAI】完成1500万美元融资
String
- 原文地址:https://blog.csdn.net/qq_41708993/article/details/125565555