-
【从0-1成为架构师】网站架构演化
序言
我认为作为一个架构师来说,不能是为了上一些新技术新工具而去上,而是应该明白背后的道理和意义,那么了解网站架构的演化就很有必要了,没有上来就是大型网站的应用,系统架构的演进也不是一下子就变得这么庞大的,我们要知其然而知其所以然,这样当我们去设计架构时才会游刃有余。
大型网站软件系统的特点
- 高并发,大流量:需要面对高并发
- 高可用:系统7*24小时不间断服务,如果服务不可用都会造成很大的损失
- 海量数据:需要存储,管理海量数据,使用大量的服务器,FaceBook每周上传照片数目抄10亿,百度收录的网页数据有数百亿。
- 用户分布广泛,网络情况复杂:为全球客户提供服务,用户分布广,各地网络天差地别。
- 安全环境恶劣:由于互联网的开发性,使得互联网更容易收到攻击。
- 需求快速变更,发布频繁:和传统行业的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,产品的发布频率是极高的。
- 渐进式发展:与传统行业一开始就规划好全部功能和非功能需求不同,几户所有的大型网站都是从一个小网站开始的,渐渐发展起来的。
大型网站架构演化发展历程
初始阶段:单一服务器
最开始网站没有多少人访问,只需要一台服务器就够了,应用程序,数据库,文件都在一起,通常服务器用linux,应用程序用java编写,然后部署到tomcat上,数据库用mysql,汇集各种免费开源软件就可以开始运行网站了

扩展阶段:应用服务和数据服务分离
随着业务的发展,越来越多的用户请求导致网站响应速度变慢,越来越多的数据存储导致存储空间不足,这是就需要将应用与存储分开,变成三台服务器,应用服务器,文件服务器和数据服务器。我们可以通过不同服务器的需求不同来配置不同的资源,应用服务器需要处理大量的逻辑,所以需要更好的cpu,数据库需要大量的存储和快速的磁盘检索,所以需要更大的内存和硬盘。数据与应用分离,不同性质的服务器承担不同的服务角色,可以提高网站的使用,但是随着用户逐渐增多,数据库压力过大导致访问延迟,进而影响网站的性能,用户体验受影响。

使用缓存改善网站性能
网站的访问特点与现实中的财富分布一样遵守28原则,80%的业务访问集中在20%的数据上,以淘宝举例,买家浏览的商品集中在销售量高评价好的少数中,百度搜索的关键词集中在少数的热门词汇上,既然大部分的业务访问集中在小部分数据中,那么如果把这一小部分数据缓存到内存中,是不是就可以减少数据库的压力。提高性能了呢。使用缓存有两种使用模式,一种是缓存到本地应用服务器上的本地缓存和缓存到专门的分布式缓存服务器的上的远程缓存,本地缓存更快一下,但是会受到服务器性能的影响,缓存的数据量有限,远程缓存可以采用集群的方式,理论上来说,远程缓存能一直加服务器,那容量就是无限的。

使用应用服务器集群改善网站的并发能力
使用集群是常见的解决高并发,海量数据的手段,对网站架构而言只要通过增加一台服务器的方式改善负载压力,就可以通过同样的方式持续增加服务器的能力,应用服务器实现集群是网站可伸缩架构中较为简单成熟的一种。通过负载均衡服务器可以把用户的请求分发到不同的应用服务器上,如果有更多的用户就在集群里增加更多的服务器,这样应用服务器就不会变成瓶颈了。
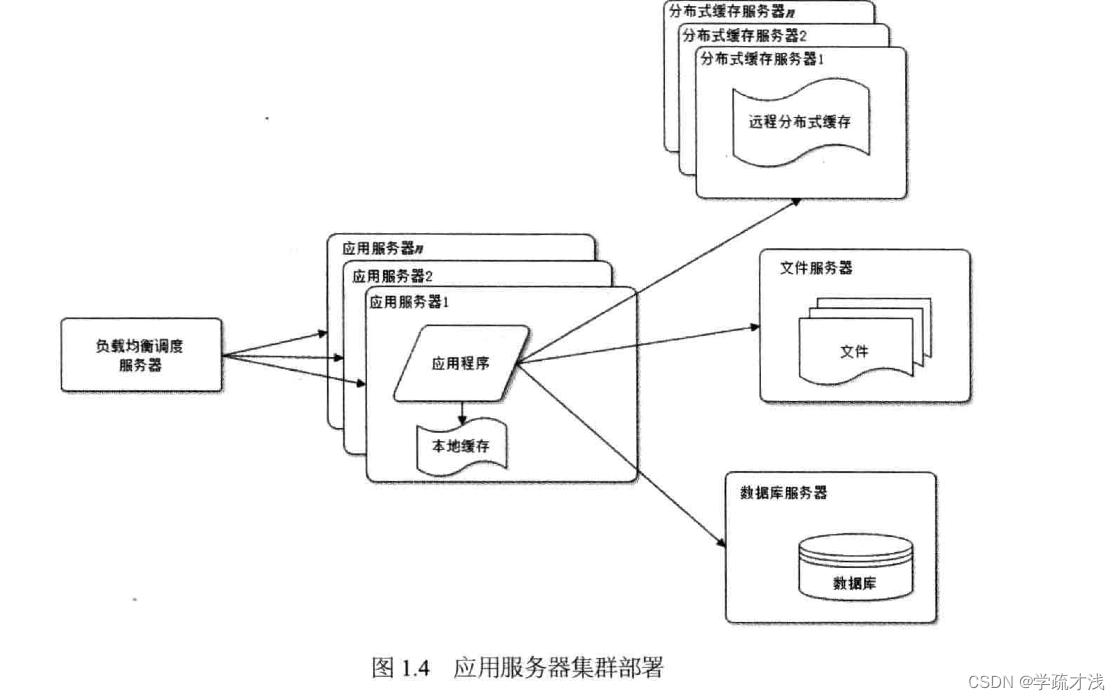
数据库读写分离
虽然通过缓存已经缓解的大部分的数据库压力,但是还有一些读请求和所有的写请求会直接访问到数据库,在网站的规模到达一定规模之后,数据库还是会成为访问的瓶颈。
目前大部分的主流数据库都支持主从同步,这个特性为解决数据库的压力提供了可能,我们可以把数据库的读和写分离出来,然后通过主从同步来保持数据的一致性。我们在应用服务器上写数据的时候,将数据存入到写库中然后同步到读库,当应用服务器读数据的时候可以通过读库来读取数据,为了使读写分离便于使用,一般会在应用服务器中使用专门的数据库模板来帮助减轻负担。
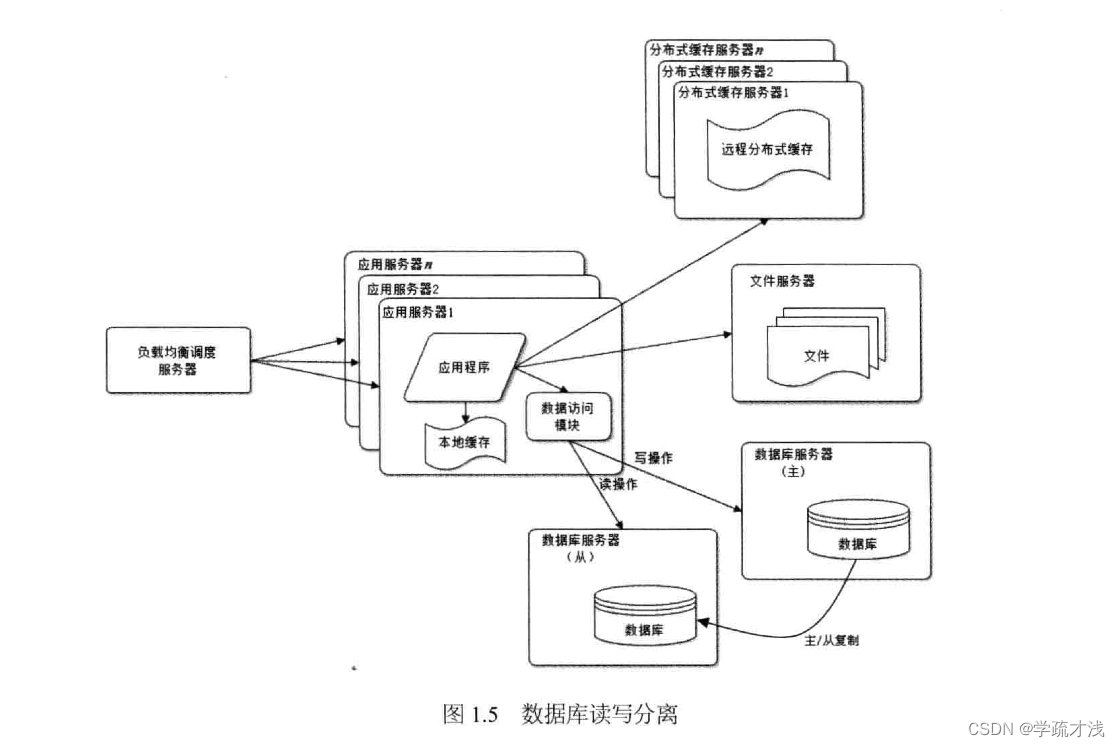
使用反向代理和cdn加速网站响应
随着业务的发展,中国网络环境的复杂,不同地区的用户访问网站的速度也是天差地别,有研究表名,网站延迟速率与用户流失率正相关,为了留住客户,网站需要进行加速网站访问速度。
cdn和反向代理都是基于缓存,不同的是cdn部署在网络提供方的机房,使用户在访问网站是可以从最近的网络提供放获取数据。而反向代理是部署在网络的中心机房。当用户请求是首先访问反向代理服务器,如果有缓存数据则直接提供给用户。
cdn和反向代理都是希望能尽快的将数据提供给用户。一方面加快访问。一方面减少压力
使用分布式文件系统和分布式数据库
任何一台强大的服务器都无法满足大型网站持续增长的业务需求,数据库经过读写分离过后已经从一台服务器变成了两台服务器,但是随着业务的发展还是满足不了需求,这个时候就需要使用分布式数据库,文件服务器也一样。
目前分布式数据库是网站数据库拆分的最后手段,只有在单表文件数巨大的时候才会使用到。常规情况下还是更喜欢业务分库,将不同业务的数据部署到不同服务器上

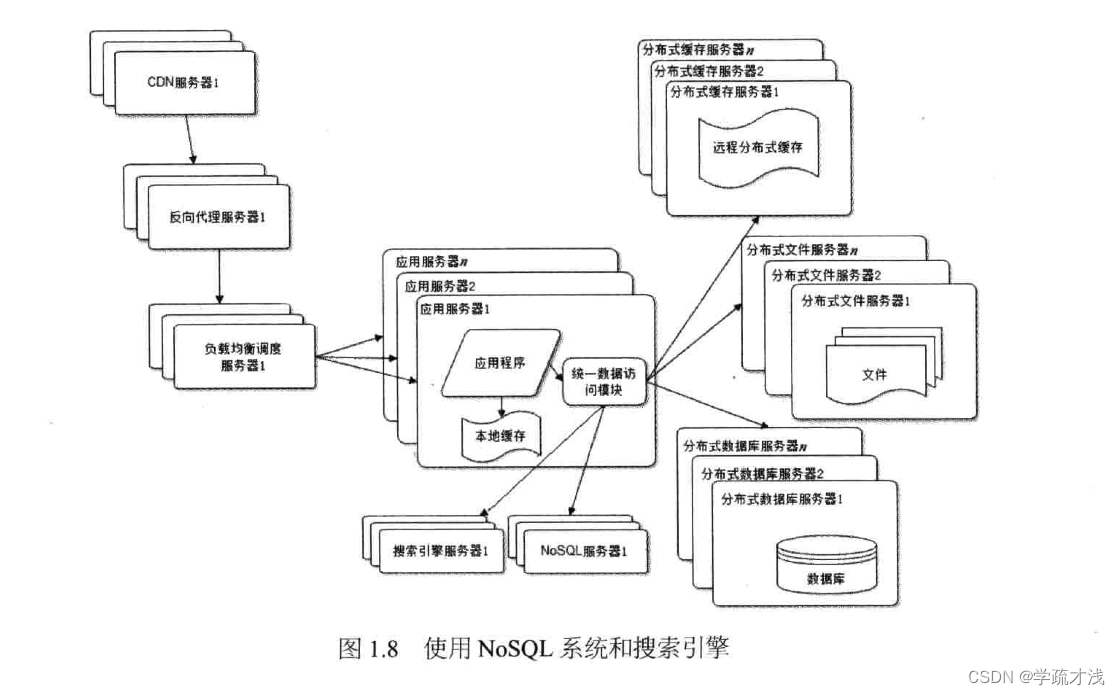
使用nosql和搜索引擎
随着业务越来越复杂,对数据存储和检索的要求也越来越高,那么就有必要使用一些非关系型数据库比如nosql和搜索引擎了,在应用系统中使用一套统一的数据访问系统来访问数据,减轻管理的麻烦
业务拆分
随着业务发展的越来的复杂,维护人员越来越多,采用分而治之的思想,将整个大业务拆分成多个小系统,由不同的项目组去管理。

分布式服务
随着业务拆分的越来越小,存储系统越来越大,应用系统的复杂程度成指数级上升,维护越来越困难,并且所有的服务都要与数据库进行连接,存储系统根本承受不住这样的需求量,存储系统就会奔溃,既然每个业务都要去和数据库进行连接,并且有些请求的重复的,每个服务都会触发,那么就把这个重复的请求抽出来,独立部署,由这些可复用的业务连接数据库,提供共有的服务,而应用系统只 用来管理界面,通过分布式服务调用业务服务完成操作

- 参考资料:【大型网站技术架构核心原理与案例分析 】作者:李智慧
-
相关阅读:
动态设置原生swiper的配置项
侯捷课程笔记(一)(传统c++语法,类内容)
移植SQLite3、OpenCV到RV1126开发板上开发人脸识别项目
【torch】如何把给定mask按比例选取再次划分mask?
nodeJs--AJAX技术
计算机网络:网络层
分数限制下,选好专业还是选好学校?过来人跟你说
【Myatis】mybatis的缓存机制
读书记:认知觉醒(一)大脑、焦虑、耐心
Python使用pymysql和xlrd2将Excel数据导入MySQL数据库
- 原文地址:https://blog.csdn.net/qq_38446413/article/details/125624472