-
使用SwinUnet训练自己的数据集
参考博文: https://blog.csdn.net/qq_37652891/article/details/123932772
数据集准备
遥感图像多类别语义分割,总共分为7类(包括背景)

image:

label_rgb
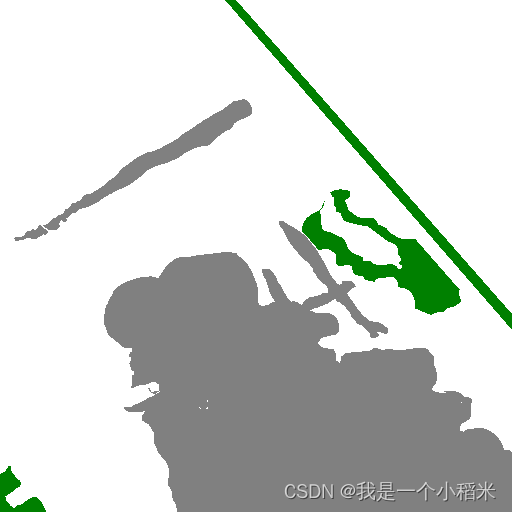
label(这里并不是全黑,其中的类别取值为0,1,2,3,4,5,6),此后的训练使用的也是这样的数据

数据地址
百度云:https://pan.baidu.com/s/1zZHnZfBgVWxs6TJW4yjeeQ
提取码:2022SwinUNet代码地址
数据集处理
数据集的
image和label,这个数据集应该提供了rgb格式标签和包含0,1,2,3,4,5,6值的标签,SwinUNet使用的是包含0,1,2,3,4,5,6的标签图像;1. 数据集
数据集存放在
SwinUNet根目录下,image中是原图像,label中是标签图像(共7类,其标签取值为0,1,2,3,4,5,6,7);
如果使用其他数据集,要注意标签的取值。比如如果是二分类。即标签0或255,需要换成0或1—SwinUNet
---------configs
---------img_datas
---------------train
--------------------image
--------------------label
---------------test
--------------------image
--------------------label2. 在
SwinUnet根目录下创建npz.py文件,运行npz.py文件import glob import cv2 import numpy as np import os def npz(im, la, s): images_path = im labels_path = la path2 = s images = os.listdir(images_path) for s in images: image_path = os.path.join(images_path, s) label_path = os.path.join(labels_path, s) image = cv2.imread(image_path) image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) # 标签由三通道转换为单通道 label = cv2.imread(label_path, flags=0) # 保存npz文件 np.savez(path2+s[:-4]+".npz",image=image,label=label) npz('./img_datas/train/image/', './img_datas/train/label/', './data/Synapse/train_npz') npz('./img_datas/test/image/', './img_datas/test/label/', './data/Synapse/test_vol_h5')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3. 在
SwinUnet根目录下创建txt.py文件,运行txt.py文件目的是生成
./list/list_Synapse/train.txt和./list/list_Synapse/test_vol.txt文件import os def write_name(np, tx): #npz文件路径 files = os.listdir(np) #txt文件路径 f = open(tx, 'w') for i in files: #name = i.split('\\')[-1] name = i[:-4]+'\n' f.write(name) write_name('./data/Synapse/train_npz', './lists/lists_Synapse/train.txt') write_name('./data/Synapse/test_vol_h5', './lists/lists_Synapse/test_vol.txt')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4. 下载预训练权重,放在
SwinUnet目录下的pretrained_ckpt文件夹下链接:https://pan.baidu.com/s/1-hYwJRlr95Fv08e9AEARww
提取码:2022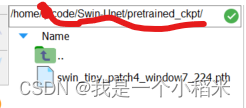
修改网络
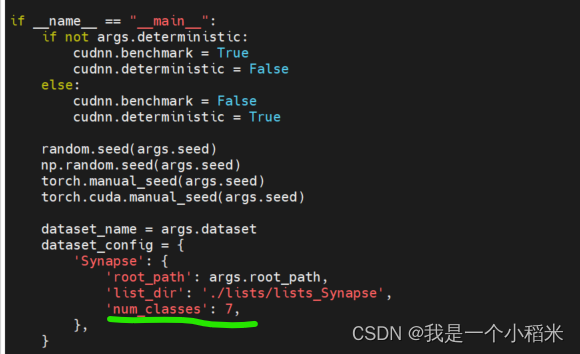
1. 修改
train.py文件
比较重要的是类别数量,其他视情况而定
2. 修改
./datasets/dataset_synapse.py文件
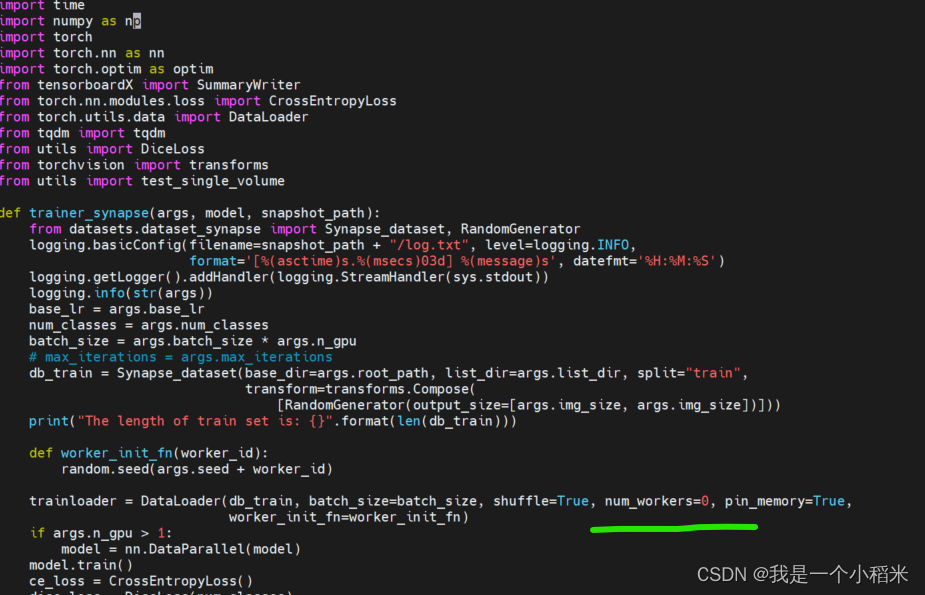
3. 修改
trainer.py文件此处不知道为什么
4. 运行代码
这些信息可以作为超参传入,如果不能,那么可以使用
default=的方式写入默认值
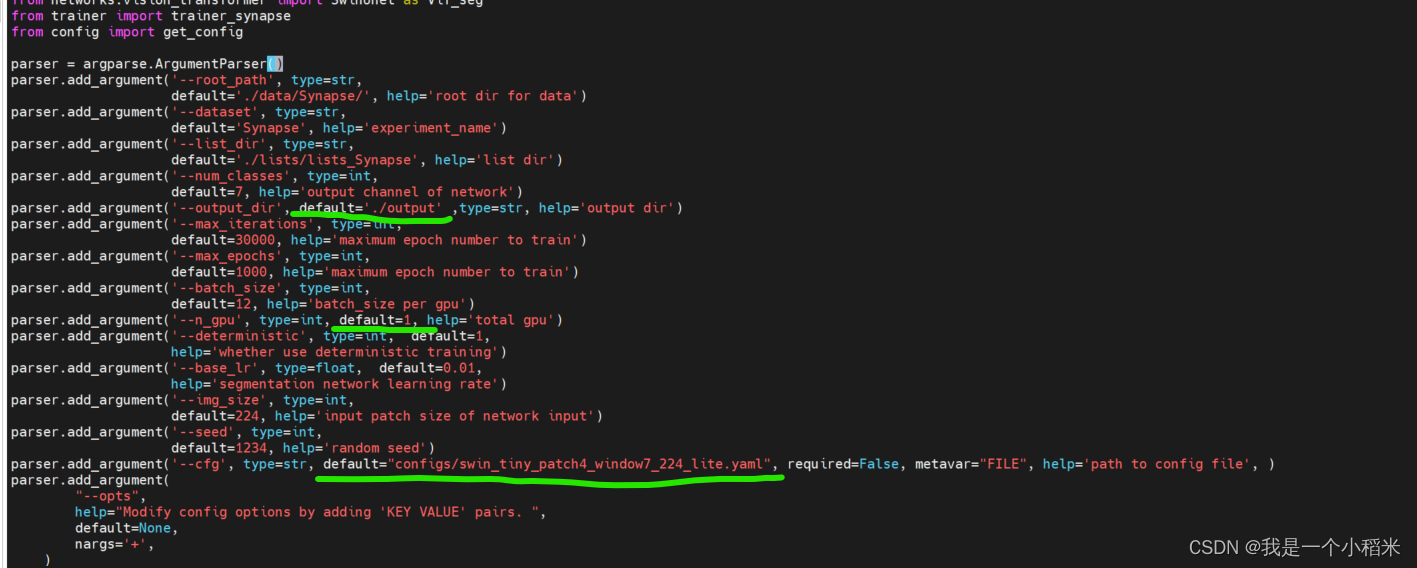
如果设置好啦默认值,那么运行python train.py就可以啦
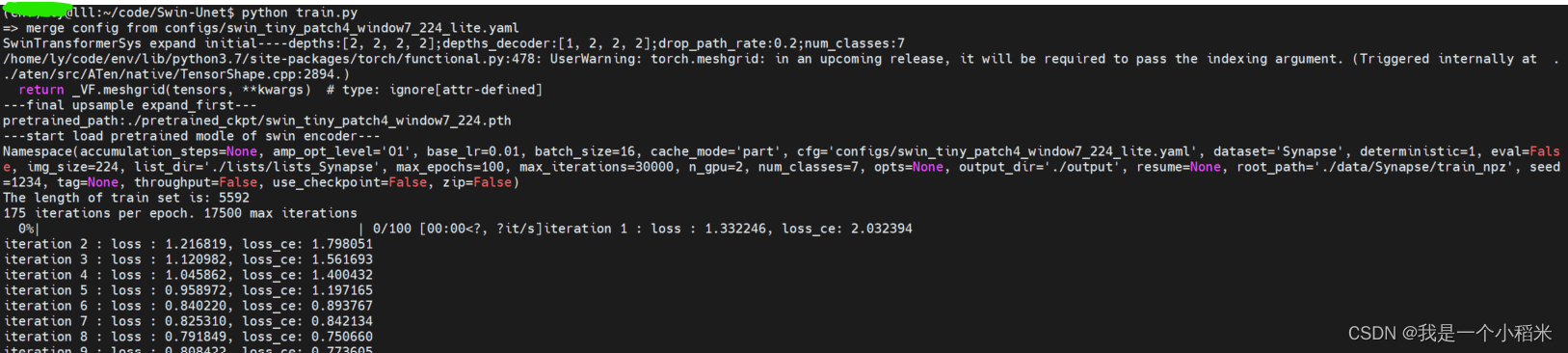
-
相关阅读:
基于微信小程序奶茶店在线点单管理系统ssm框架-计算机毕业设计
手搭手Ajax经典基础案例省市联动
23.Ubuntu磁盘挂载常用命令
Mac PHP7.4安装
万字详谈加密合规:Tornado Cash制裁后时代
windows10 :VMware安装Centos7图文
·工业 4.0 和第四次工业革命详细介绍
个人千元奖励!华秋PCB多层板设计挑战赛等您参与
评论列表案例,通过Ajax向服务器发送请求
运动耳机买什么样的好?各类运动蓝牙耳机推荐
- 原文地址:https://blog.csdn.net/weixin_44669966/article/details/125623961