-
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
🚀 优质资源分享 🚀
学习路线指引(点击解锁) 知识定位 人群定位 🧡 Python实战微信订餐小程序 🧡 进阶级 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 💛Python量化交易实战💛 入门级 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 什么是Scrapy
- 基于Twisted的异步处理框架
- 纯python实现的爬虫框架
- 基本结构:5+2框架,5个组件,2个中间件

5个组件:
- **Scrapy Engine:**引擎,负责其他部件通信 进行信号和数据传递;负责Scheduler、Downloader、Spiders、Item Pipeline中间的通讯信号和数据的传递,此组件相当于爬虫的“大脑”,是整个爬虫的调度中心
- **Scheduler:**调度器,将request请求排列入队,当引擎需要交还给引擎,通过引擎将请求传递给Downloader;简单地说就是一个队列,负责接收引擎发送过来的 request请求,然后将请求排队,当引擎需要请求数据的时候,就将请求队列中的数据交给引擎。初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取,同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
- **Downloader:**下载器,将引擎engine发送的request进行接收,并将response结果交还给引擎engine,再由引擎传递给Spiders处理
- **Spiders:**解析器,它负责处理所有responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器);同时也是入口URL的地方
- **Item Pipeline:**数据管道,就是我们封装去重类、存储类的地方,负责处理 Spiders中获取到的数据并且进行后期的处理,过滤或者存储等等。当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库
2个中间件:
- **Downloader Middlewares:**下载中间件,可以当做是一个可自定义扩展下载功能的组件,是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
- **Spider Middlewares:**爬虫中间件,Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。自定义扩展、引擎和Spider之间通信功能的组件,通过插入自定义代码来扩展Scrapy功能。
Scrapy操作文档(中文的):https://www.osgeo.cn/scrapy/topics/spider-middleware.html
Scrapy框架的安装
cmd窗口,pip进行安装
pip install scrapy- 1

Scrapy框架安装时常见的问题
找不到win32api模块----windows系统中常见
pip install pypiwin32- 1
创建Scrapy爬虫项目
新建项目
scrapy startproject xxx项目名称- 1
实例:
scrapy startproject tubatu\_scrapy\_project- 1

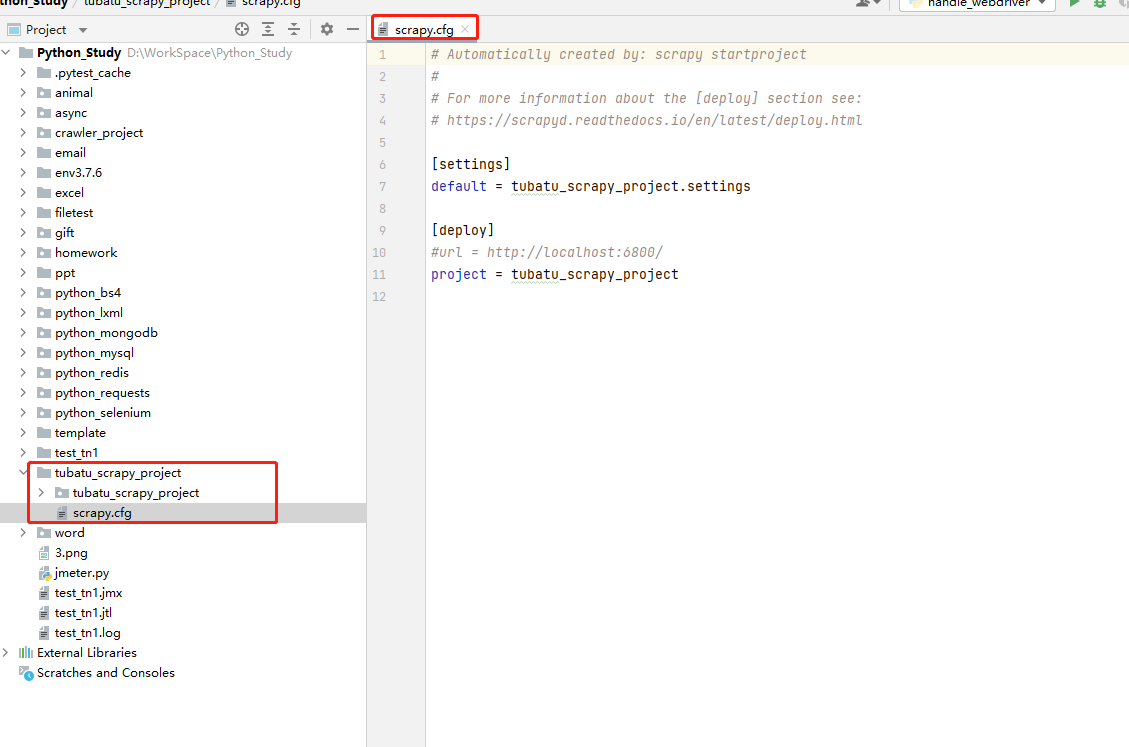
项目目录

scrapy.cfg:项目的配置文件,定义了项目配置文件的路径等配置信息
- 【settings】:定义了项目的配置文件的路径,即./tubatu_scrapy_project/settings文件
- 【deploy】:部署信息

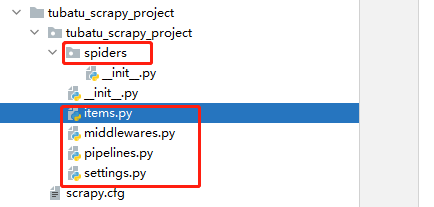
- **items.py:**就是我们定义item数据结构的地方;也就是说我们想要抓取哪些字段,所有的item定义都可以放到这个文件中
- **pipelines.py:**项目的管道文件,就是我们说的数据处理管道文件;用于编写数据存储,清洗等逻辑,比如将数据存储到json文件,就可以在这边编写逻辑
- **settings.py:**项目的设置文件,可以定义项目的全局设置,比如设置爬虫的 USER_AGENT ,就可以在这里设置;常用配置项如下:
- ROBOTSTXT_OBEY :是否遵循ROBTS协议,一般设置为False
- CONCURRENT_REQUESTS :并发量,默认是32个并发
- COOKIES_ENABLED :是否启用cookies,默认是False
- DOWNLOAD_DELAY :下载延迟
- DEFAULT_REQUEST_HEADERS :默认请求头
- SPIDER_MIDDLEWARES :是否启用spider中间件
- DOWNLOADER_MIDDLEWARES :是否启用downloader中间件
- 其他详见链接
- **spiders目录:**包含每个爬虫的实现,我们的解析规则写在这个目录下,即爬虫的解析器写在这个目录下
- **middlewares.py:**定义了 SpiderMiddleware和DownloaderMiddleware 中间件的规则;自定义请求、自定义其他数据处理方式、代理访问等
自动生成spiders模板文件
cd到spiders目录下,输出如下命令,生成爬虫文件:
scrapy genspider 文件名 爬取的地址- 1


运行爬虫
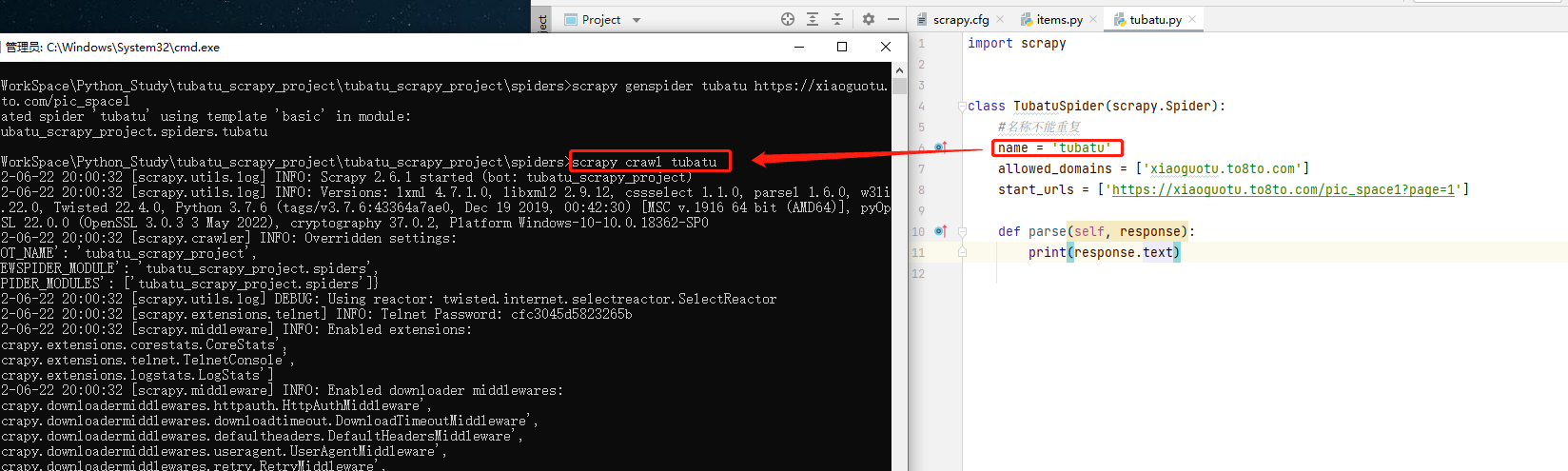
方式一:cmd启动
cd到spiders目录下,执行如下命令,启动爬虫:
scrapy crawl 爬虫名- 1

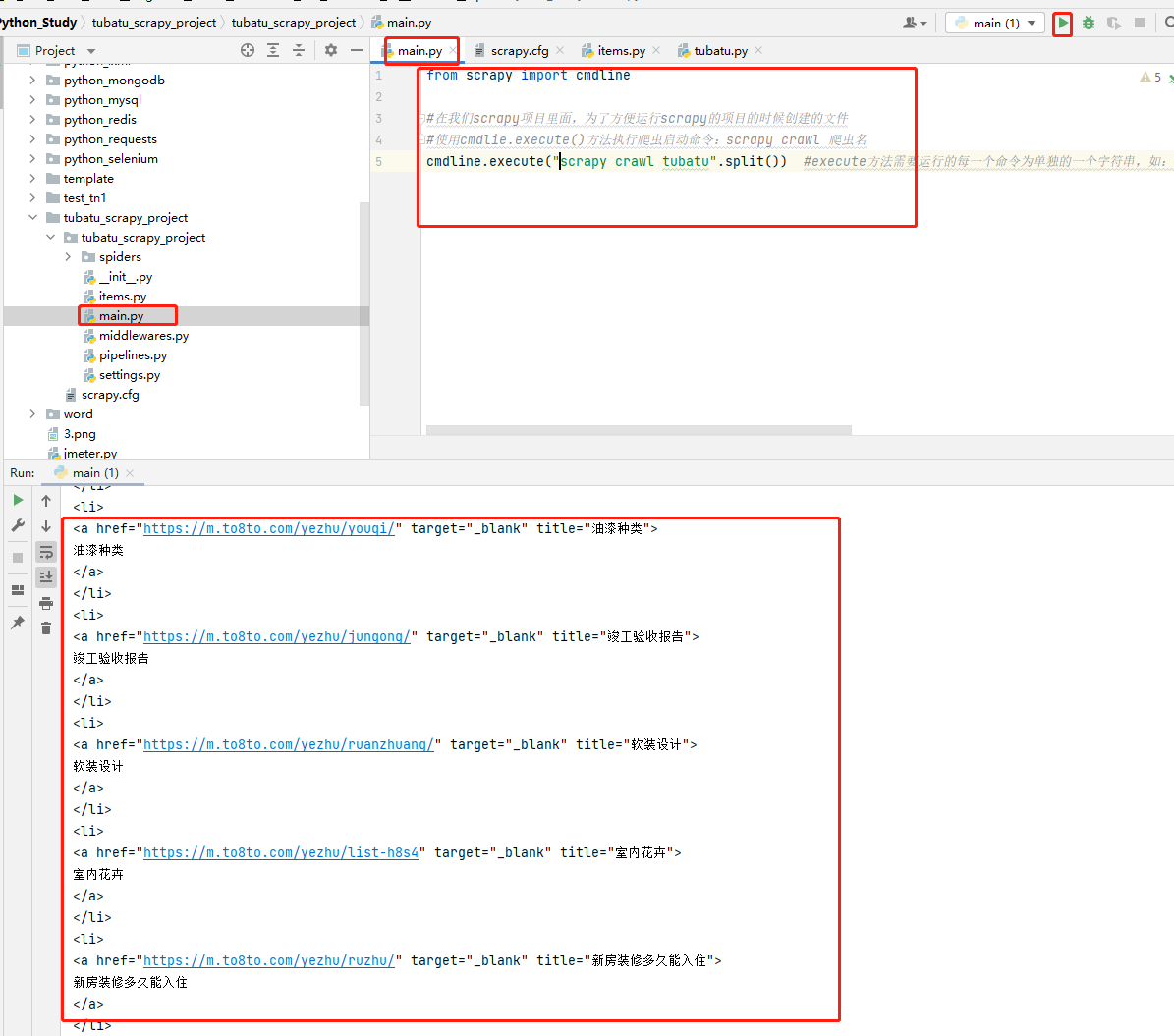
方式二:py文件启动
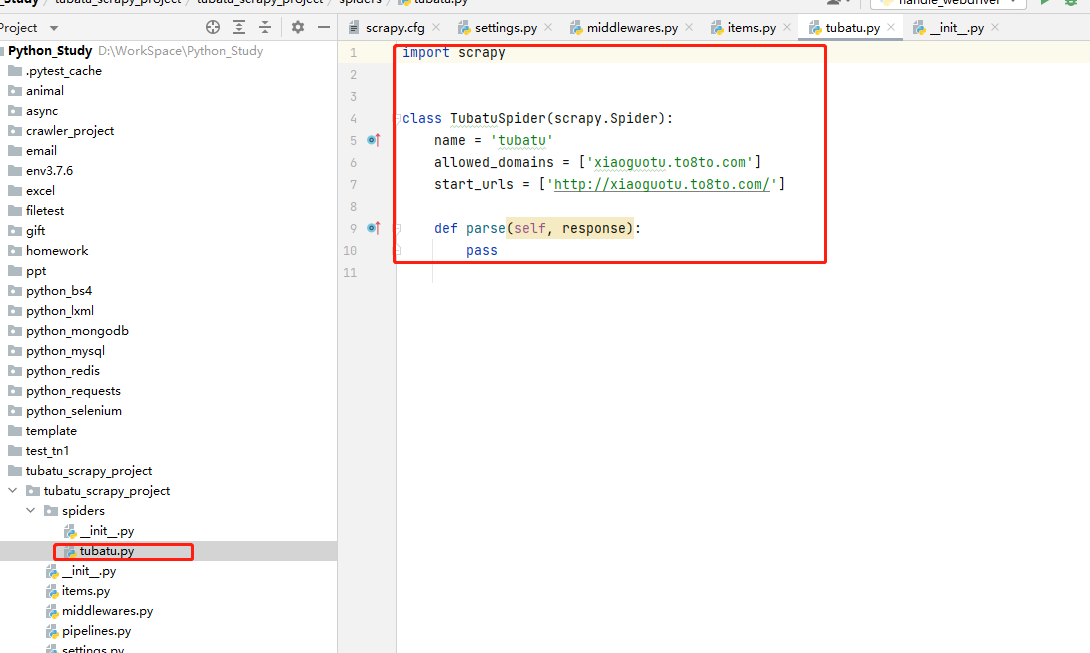
在项目下创建main.py文件,创建启动脚本,执行main.py启动文件,代码示例如下:
code-爬虫文件👇
import scrapy class TubatuSpider(scrapy.Spider): #名称不能重复 name = 'tubatu' #允许爬虫去抓取的域名 allowed\_domains = ['xiaoguotu.to8to.com'] #项目启动之后要启动的爬虫文件 start\_urls = ['https://xiaoguotu.to8to.com/pic\_space1?page=1'] #默认的解析方法 def parse(self, response): print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
code-启动文件👇
from scrapy import cmdline #在我们scrapy项目里面,为了方便运行scrapy的项目的时候创建的文件 #使用cmdlie.execute()方法执行爬虫启动命令:scrapy crawl 爬虫名 cmdline.execute("scrapy crawl tubatu".split()) #execute方法需要运行的每一个命令为单独的一个字符串,如:cmdline.execute(['scrapy', 'crawl', 'tubatu']),所以如果命令为一整个字符串时,需要split( )进行分割;#- 1
- 2
- 3
- 4
- 5
code-运行结果👇

示例项目
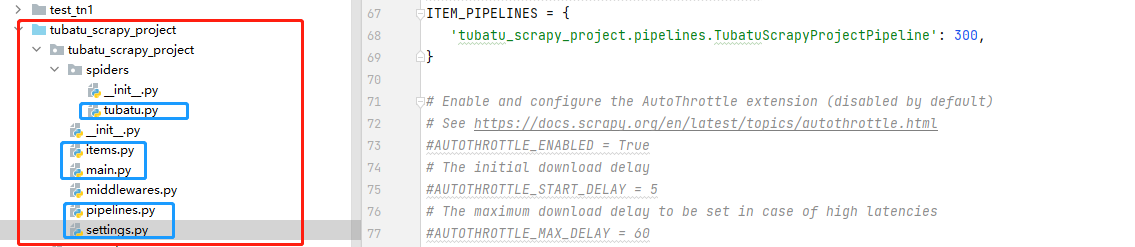
爬取土巴兔装修网站信息。将爬取到的数据存入到本地MongoDB数据库中;
下图👇为项目机构,标蓝的文件就是此次code的代码

tubatu.py
1 import scrapy 2 from tubatu\_scrapy\_project.items import TubatuScrapyProjectItem 3 import re 4 5 class TubatuSpider(scrapy.Spider): 6 7 **#名称不能重复** 8 name = 'tubatu' 9 **#允许爬虫去抓取的域名,超过这个目录就不允许抓取** 10 allowed\_domains = ['xiaoguotu.to8to.com','wx.to8to.com','sz.to8to.com'] 11 #项目启动之后要启动的爬虫文件 12 start\_urls = ['https://xiaoguotu.to8to.com/pic\_space1?page=1'] 13 14 15 #默认的解析方法 16 def parse(self, response): 17 **# response后面可以直接使用xpath方法** 18 **# response就是一个Html对象** 19 pic\_item\_list = response.xpath("//div[@class='item']") 20 for item in pic\_item\_list[1:]: 21 info = {} 22 **# 这里有一个点不要丢了,是说明在当前Item下面再次使用xpath** 23 # 返回的不仅仅是xpath定位中的text()内容,需要再过滤;返回如:[] 24 # content\_name = item.xpath('.//div/a/text()') 25 26 **#使用extract()方法获取item返回的data信息,返回的是列表** 27 # content\_name = item.xpath('.//div/a/text()').extract() 28 29 **#使用extract\_first()方法获取名称,数据;返回的是str类型** 30 #获取项目的名称,项目的数据 31 info['content\_name'] = item.xpath(".//a[@target='\_blank']/@data-content\_title").extract\_first() 32 33 #获取项目的URL 34 info['content\_url'] = "https:"+ item.xpath(".//a[@target='\_blank']/@href").extract\_first() 35 36 #项目id 37 content\_id\_search = re.compile(r"(\d+)\.html") 38 info['content\_id'] = str(content\_id\_search.search(info['content\_url']).group(1)) 39 40 **#使用yield来发送异步请求,使用的是scrapy.Request()方法进行发送,这个方法可以传cookie等,可以进到这个方法里面查看** 41 **#回调函数callback,只写方法名称,不要调用方法** 42 yield scrapy.Request(url=info['content\_url'],callback=self.handle\_pic\_parse,meta=info) 43 44 if response.xpath("//a[@id='nextpageid']"): 45 now\_page = int(response.xpath("//div[@class='pages']/strong/text()").extract\_first()) 46 next\_page\_url="https://xiaoguotu.to8to.com/pic\_space1?page=%d" %(now\_page+1) 47 yield scrapy.Request(url=next\_page\_url,callback=self.parse) 48 49 50 def handle\_pic\_parse(self,response): 51 tu\_batu\_info = TubatuScrapyProjectItem() 52 #图片的地址 53 tu\_batu\_info["pic\_url"]=response.xpath("//div[@class='img\_div\_tag']/img/@src").extract\_first() 54 #昵称 55 tu\_batu\_info["nick\_name"]=response.xpath("//p/i[@id='nick']/text()").extract\_first() 56 #图片的名称 57 tu\_batu\_info["pic\_name"]=response.xpath("//div[@class='pic\_author']/h1/text()").extract\_first() 58 #项目的名称 59 tu\_batu\_info["content\_name"]=response.request.meta['content\_name'] 60 # 项目id 61 tu\_batu\_info["content\_id"]=response.request.meta['content\_id'] 62 #项目的URL 63 tu\_batu\_info["content\_url"]=response.request.meta['content\_url'] 64 **#yield到piplines,我们通过settings.py里面启用,如果不启用,将无法使用** 65 yield tu\_batu\_info- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
items.py
1 # Define here the models for your scraped items 2 # 3 # See documentation in: 4 # https://docs.scrapy.org/en/latest/topics/items.html 5 6 import scrapy 7 8 9 class TubatuScrapyProjectItem(scrapy.Item): 10 # define the fields for your item here like: 11 # name = scrapy.Field() 12 13 #装修名称 14 content\_name=scrapy.Field() 15 #装修id 16 content\_id = scrapy.Field() 17 #请求url 18 content\_url=scrapy.Field() 19 #昵称 20 nick\_name=scrapy.Field() 21 #图片的url 22 pic\_url=scrapy.Field() 23 #图片的名称 24 pic\_name=scrapy.Field()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
piplines.py
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM\_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 from itemadapter import ItemAdapter 9 10 from pymongo import MongoClient 11 12 class TubatuScrapyProjectPipeline: 13 14 def \_\_init\_\_(self): 15 client = MongoClient(host="localhost", 16 port=27017, 17 username="admin", 18 password="123456") 19 mydb=client['db\_tubatu'] 20 self.mycollection = mydb['collection\_tubatu'] 21 22 def process\_item(self, item, spider): 23 data = dict(item) 24 self.mycollection.insert\_one(data) 25 return item- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
settings.py

main.py
1 from scrapy import cmdline 2 3 #在我们scrapy项目里面,为了方便运行scrapy的项目的时候创建的文件 4 #使用cmdlie.execute()方法执行爬虫启动命令:scrapy crawl 爬虫名 5 cmdline.execute("scrapy crawl tubatu".split()) **#execute方法需要运行的每一个命令为单独的一个字符串,如:cmdline.execute(['scrapy', 'crawl', 'tubatu']),所以如果命令为一整个字符串时,需要split( )进行分割;#**- 1
- 2
- 3
- 4
- 5
-
__EOF__
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9YcYyG99-1656996601626)(https://blog.csdn.net/gltou)]葛老头 - 本文链接: https://blog.csdn.net/gltou/p/16400449.html
-
相关阅读:
注册字符设备驱动
Scratch3之AI集成 - flappy bird AI版本
部分gcc预定义宏和函数栈帧的内存分布
【Terminal】Mac给Terminal添加快捷键(Ctrl-Alt-T) & 通过几行js节省平常重复性的工作
在线AI聊天对话机器人,答你所问!
Pytorch中 permute、transpose 和 view 、resize函数
GeoServer安装以及部署
告警收敛杂谈
通过对抽象模型和概念模型的整合,细化项目整体流程
10.10作业
- 原文地址:https://blog.csdn.net/pythonxxoo/article/details/125617449