-
索引数据结构详解
目录
-
索引是帮助Mysql高效获取数据的排好序的数据结构
-
索引也是存储在磁盘上
-
如果没有建立索引会一条一条的查询,查询一条会跟磁盘做一次IO操作
-
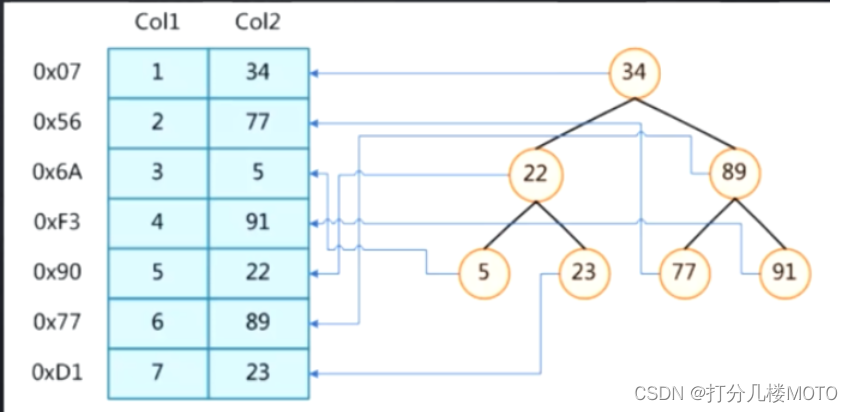
见下图,以Col2为索引建立二叉树,每一个节点包含一个key(值),value(索引行所在磁盘地址)
-
索引数据结构
-
二叉树
-
红黑树
-
Hash表
-
B-Tree
二叉树
-
Mysql底层并没有使用二叉树:因为如果数据比较极端的话,会形成一张链表,并没有降低查询
红黑树
-
Mysql底层并没有使用红黑树:如果数据很大500万行,树的高度变得很高,如果查询的索引处于最底层的叶子节点,查询效率依然不好
Hash
-
对索引的key进行一次hash计算就可以定位出数据存储的位置
-
很多时候Hash索引要比B+树索引更高效
-
仅能满足 "=", "IN",不支持范围查询

B-Tree
-
因为分叶子节点也会存储索引地址,树的高度比较与B+Tree大大变高
-
叶子节点具有相同的深度,叶结点的指针为空
-
所有索引元素不重复
-
节点中的数据索引从左到右递增排列

B+Tree
-
树的高度比红黑树低的多,几千万行的数据高度为3
-
非叶子节点不存储data(叶子节点有这张表的所用的索引),只存储索引(冗余),可以放更多的索引
-
叶子节点包含所有索引字段
-
叶子节点用指针连接,并且从左到右按照从小到大排列,可以使用二叉查找,提高区间访问的能力
-
每个节点最大是16KB

-
查找30的过程
-
将根节点即15所在行加载的内存中,根据二分查找30所在的区间即15后面的区间(保存的是15后面的数据页在磁盘的地址)
-
将15后面的数据页加载到内存,,根据二分查找30所在的区间即20后面的区间
-
在内存比对找到30,根据记录的内存地址找到索引所在行的数据
-
-
B+Tree如何支持范围查找(利用叶子结点的双向连表 >20)
-
从根节点快速定位20叶子节点所在的位置,利用链表,往后查询
-
存储引擎索引实现
MylSAM引擎(非聚集索引)
-
叶子节点仅仅包含地址,不包含数据
-
存储引擎是在表级别生效的
-
使用MylSAM引擎,一个表会对应三个文件(索引文件和数据文件是分离的)
-
xxx.frm:表结构
-
xxx.MYD:表数据
-
xxx.MYI:表索引
-
-
查找30的过程
-
通过30去xxx.MYI文件查找30对应的内存地址
-
根据查找到的地址去MYD文件中查找数据
-

InnoDB索引实现(聚集)
-
使用InnoDB引擎,一个表会对应两个文件
-
xxx.frm:表结构
-
xxx.idb:数据和索引
-
-
表数据文件本身就是按B+Tree组织的一个索引结构文件
-
聚集索引-叶节点包含了完整的数据记录
-
为什么建议InnoDB表必须建主键,并且推荐使用整形的自增主键???
-
xxx.idb文件必须要以某一个列为索引建立B+Tree,如果不主动建立主键,会默认为你选择一列(数据都不相等的)建立B+Tree树,如果mysql选不到符合条件的一列则会建立一个隐藏列维护一个隐藏的id,用这个隐藏列建立B+Tree
-
筛选区间的时候使用整形比较快(影响不大)
-
为什么推荐自增:为了维护B+Tree的特性,可能需要不断地进行转换,也会损耗一定的效率,如果是自增的id,则不会
-

-
为什么非主键索引结构叶子节点存储的是主键值(一致性和节省存储空间)???
-
InnoDB整张表只有一个聚集索引表,如果建了主键,会用主键建立B+Tree,如果没有建主键则是UUID;非主键索引建立B+Tree,叶子节点保存的不是完整的记录而是主键id
-
每加一个索引在xxx.idb文件里面会多一个B+Tree
-
一是为了节省存储空间
-
一致性:插入新的一行记录,如果主键索引和非主键索引都要维护整张表的数据的话,只有两个索引都插入成功才会插入成功;如果采用叶子节点保存的不是完整的记录而是主键id,可以让主键索引先插成功,再去建二级索引,把主键id放到叶子节点中就可以了
-
-
-
二级索引也是非聚集索引,先根据二级索引找到主键,再去主键索引里面找到完整的数据
-
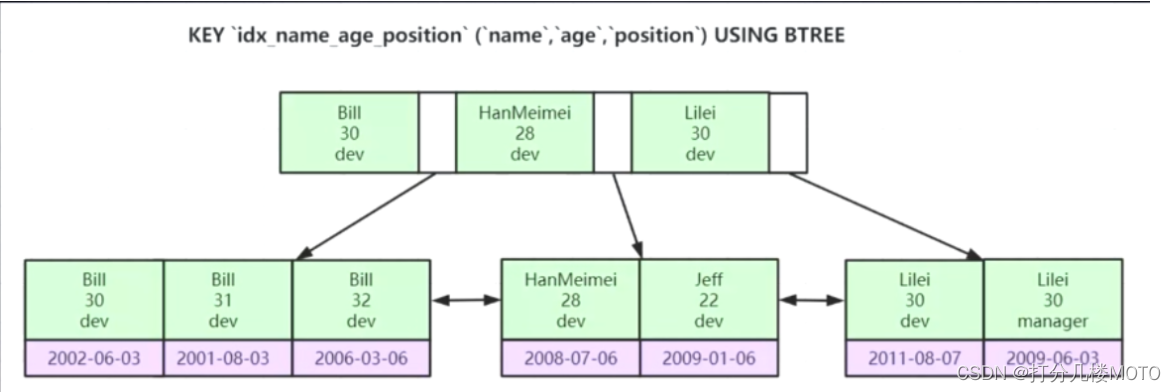
联合索引介绍
-
先比较name能判断大小不会再去比较后两个字段 ,name字段相等再比较age,name和age都相等最后比较position
索引最左前缀原理
-
A,B,C是一个联合索引 A(联合索引最左前缀)若A不匹配或者没有使用A,则B,B&C,C都不能使用表的索引,A匹配之后均可,虽然优化器会重排,但最好还是按照顺序(索引值顺序为为A->B->C)
-
因为建立B+Tree的时候就是按照A->B->C的顺序进行排序
-
-
-
相关阅读:
前端工程化精讲第四课 接口调试:Mock 工具如何快速进行接口调试?
MySQL单表数据量超1亿,根据 索引列 批量删除数据
免杀对抗-Python-混淆算法+反序列化-打包生成器-Pyinstall
codeforces 线段树题单
Java之语法糖
CSS盒子定位的扩张
Activiti 7 源码学习
Vue2.0源码理解(6) - 组件注册
算法-REPEAT 程序
无人机控制的研究现状及关键技术
- 原文地址:https://blog.csdn.net/qq_44447372/article/details/125616828