-
C和指针 第14章 预处理器 14.9 问题
1. 预处理器定义了5个符号,给出了进行编译的文件名、文件的当前行号、当前日期和时间以及编译器是否为ANSI C编译器。为每一种符号举出一种可能的用途。
解析:
在打印错误信息时,文件名和行号可能是很有用的,尤其是在调试的早期阶段。事实上,assert宏使用它们来实现自己的功能。__DATA__和__TIME__可以把版本信息编译到程序中。最后,__STDC__可以用在条件编译中,用于在必须由两种类型的编译器进行编译的源代码中选择ANSI和前ANSI结构。2. 说出使用#define定义的名字替代字面值常量的两个优点。
解析:
优点1:定义的名字一般全部大写,能清晰告知程序员这个字是字面值常量。
优点2:只需要修改#define定义的名字一处,就可以修改所有使用该名字的地方。
3. 编写一个用于调试的宏,打印出任意的表达式。它被调用时应该接受两个参数。第1个是printf格式码,第2个是需要打印的表达式。
#include <stdio.h>
#include <stdlib.h>#define DEBUG( FORMAT, EXPRESSION ) printf( FORMAT, EXPRESSION )
int main( void ){
const char *format = "%s\n";
int x;
const char *pc = "hello";
float y;
x = 1;
y = 1.0;
DEBUG( format, pc );
DEBUG( "%s\n", "hello" );
DEBUG( "%d\n", x );
DEBUG( "%f\n", y );
return EXIT_SUCCESS;
}
/* 输出: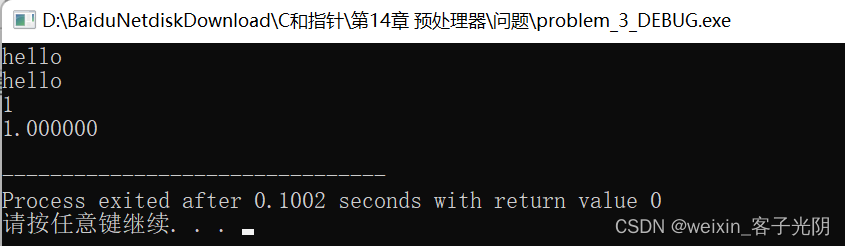
*/
4. 下面的程序员将打印出什么?在展开#define内容时必须非常小心!
#define MAX( a, b ) (a) > (b) ? (a) : (b)
#define SQUARE( x ) x * x
#define DOUBLE( x ) x + x
main()
{
int x, y, z;
y = 2; z = 3;
x = MAX( y, z );
/* a */printf( "%d %d %d\n", x, y, z );
y = 2; z = 3;
x = MAX( ++y, ++z );
/* b */printf( "%d %d %d\n", x, y, z );
x = 2;
y = SQUARE( x );
z = SQUARE( x + 6 );
/* c */printf( "%d %d %d\n", x, y, z );
x = 2;
y = 3;
z = MAX( 5 * DOUBLE( x ), ++ y );
/* d */printf( "%d %d %d\n", x, y, z );
}#include <stdio.h>
#include <stdlib.h>#define MAX( a, b ) (a) > (b) ? (a) : (b)
#define SQUARE( x ) x * x
#define DOUBLE( x ) x + x
int main( void )
{
int x, y, z;
y = 2; z = 3;
x = MAX( y, z );
/* a */printf( "%d %d %d\n", x, y, z );
y = 2; z = 3;
x = MAX( ++y, ++z );
/* b */printf( "%d %d %d\n", x, y, z );
x = 2;
y = SQUARE( x );
z = SQUARE( x + 6 );
/* c */printf( "%d %d %d\n", x, y, z );
x = 2;
y = 3;
z = MAX( 5 * DOUBLE( x ), ++ y );
/* d */printf( "%d %d %d\n", x, y, z );
return EXIT_SUCCESS;
}/* 输出:
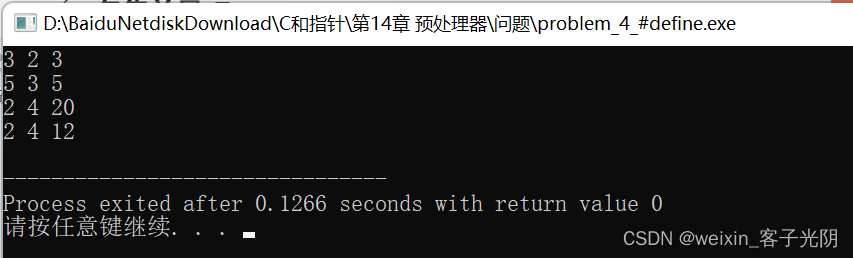
*/
/* 按照宏定义一步步展开,有括号的加上括号,没有括号不要加上括号。一句话,你让我这么做我就怎么做。谁还记得红果果和绿泡泡呢! */5. putchar函数定义于stdio.h中,尽管它的内容比较长,但它是作为一个宏实现的。你认为它为什么以这种方式定义呢?
解析:
因为会经常使用它,而它作为宏实现执行速度比作为函数实现快。6. 下列代码是否有错?如果有,错在何处?
/*
** Process all the values in the array.
*/
result = 0;
i = 0;
while( i < result ){
result += process( value[i++] );
}
解析:
我们无法通过给出的源代码进行判断。如果process以宏的方式实现,并且对它的参数求值超过一次,增加下标值的副作用可能会导致不正确的结果。
7. 下列代码是否有错?如果有,错在何处?
#define SUM( value ) ((value) + (value))
int array[SIZE];
...
/*
** Sum all the values in the array.
*/
sum = 0;
i = 0;
while( i < SIZE )
sum += SUM( array[i++] );
解析:
这个代码有几个地方存在错误,其中几处比较微妙。它的主要问题是这个宏依赖于具有副作用(增加下标值)的参数。这种依赖性是非常危险的,由于宏的名字并没有提示它实际执行的任务(这是第二个问题),这种危险进一步加大了。假定循环后来改写为:
for( i = 0; i < SIZE; i += 1 ){
sum += SUM( array[i] );
}
尽管看上去相同,但程序此时将会失败。最后一个问题是:由于宏始终访问数组中的两个元素,因此如果size是个计数值,程序就会失败。#include <stdio.h>
#include <stdlib.h>#define SUM( value ) ((value) + (value))
#define SIZE 4int main( void ){
int array[SIZE] = { 1, 2, 3, 4 };
int sum, i;
/*...*/
/*
** Sum all the values in the array.
*/
sum = 0;
i = 0;
while( i < SIZE )
sum += SUM( array[i++] );
printf( "i = %d, SIZE = %d, sum = %d\n", i, SIZE, sum );
sum = 0;
for( i = 0; i < SIZE; i += 1 ){
sum += SUM( array[i] );
}
printf( "i = %d, SIZE = %d, sum = %d\n", i, SIZE, sum );
return EXIT_SUCCESS;
}/* 输出:

*/
8. 下列代码是否有错?如果有,错在何处?
在文件header1.h中:
#ifndef _HEADER1_H
#define _HEADER1_H
#include "header2.h"
其他声明
#endif
在文件header2.h中:
#ifndef _HEADER2_H
#define _HEADER2_H
#include "header1.h"
其他声明
#endif
解析:
有错误。因为两个头文件互相包含,所以只要使用其中一个头文件那么两个头文件就会一直相互包含下去,直到程序崩溃为止。/*
** header1.h
*/
#ifndef _HEADER1_H
#define _HEADER1_H
#include "header2.h"
/*其他声明*/
#endif/*
** header2.h
*/
#ifndef _HEADER2_H
#define _HEADER2_H
#include "header1.h"
/*其他声明*/
#endif/*
** problem_8_header_file_include.cpp
*/
#include <stdio.h>
#include <stdlib.h>
#include "header1.h"int main( void ){
return EXIT_SUCCESS;
}/* 输出:

*/
/* 但是我的编译器(DEV-C++)没有检查到错误。*/9. 在一次提高程序可读性的尝试中,一位程序员编写了下面的声明。
#if sizeof( int ) == 2
typedef long int32;
#else
typedef int int32;
#endif
这段代码是否有错?如果有,错在何处?
解析:
有错误。首先long拥有的比特数比int拥有的比特数多,其次,int拥有的比特数并没有硬性规定为32位。这里我们假设1字节占用8个比特的内存。修改如下:
#if sizeof(int) == 2
typedef int int16;
#elif sizeof(int) == 4
typedef int int32;
#else
printf( "I don't know the int owned number of bit.\n" );
-
相关阅读:
uniPush实战操作详细教程步骤
AtCoder ABC132
Tutorial: Sending an Email using Python
《剑指 Offer 》—03+11+05+21(offer消失术做题)
用友U8与MES系统API接口对接案例分析
Linux——gdb|准备工作查看代码|r命令|断点相关命令|逐语句|逐过程|调用堆栈|冯诺依曼结构
画家-qt-surce
hive的join优化
lombok注解介绍
双目视觉实战--单视图测量方法
- 原文地址:https://blog.csdn.net/weixin_40186813/article/details/125612654