-
Hbase容灾与备份
一、前言
本文主要介绍 Hbase 常用的三种简单的容灾备份方案,即CopyTable、Export/Import、Snapshot。分别介绍如下:
二、CopyTable
2.1 简介
CopyTable可以将现有表的数据复制到新表中,具有以下特点:
- 支持时间区间 、row 区间 、改变表名称 、改变列族名称 、以及是否 Copy 已被删除的数据等功能;
- 执行命令前,需先创建与原表结构相同的新表;
CopyTable的操作是基于 HBase Client API 进行的,即采用scan进行查询, 采用put进行写入。
2.2 命令格式
Usage: CopyTable [general options] [--starttime=X] [--endtime=Y] [--new.name=NEW] [--peer.adr=ADR] <tablename>- 1
2.3 常用命令
- 同集群下 CopyTable
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=tableCopy tableOrig- 1
- 不同集群下 CopyTable
# 两表名称相同的情况 hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --peer.adr=dstClusterZK:2181:/hbase tableOrig # 也可以指新的表名 hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --peer.adr=dstClusterZK:2181:/hbase \ --new.name=tableCopy tableOrig- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 下面是一个官方给的比较完整的例子,指定开始和结束时间,集群地址,以及只复制指定的列族:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable \ --starttime=1265875194289 \ --endtime=1265878794289 \ --peer.adr=server1,server2,server3:2181:/hbase \ --families=myOldCf:myNewCf,cf2,cf3 TestTable- 1
- 2
- 3
- 4
- 5
2.4 更多参数
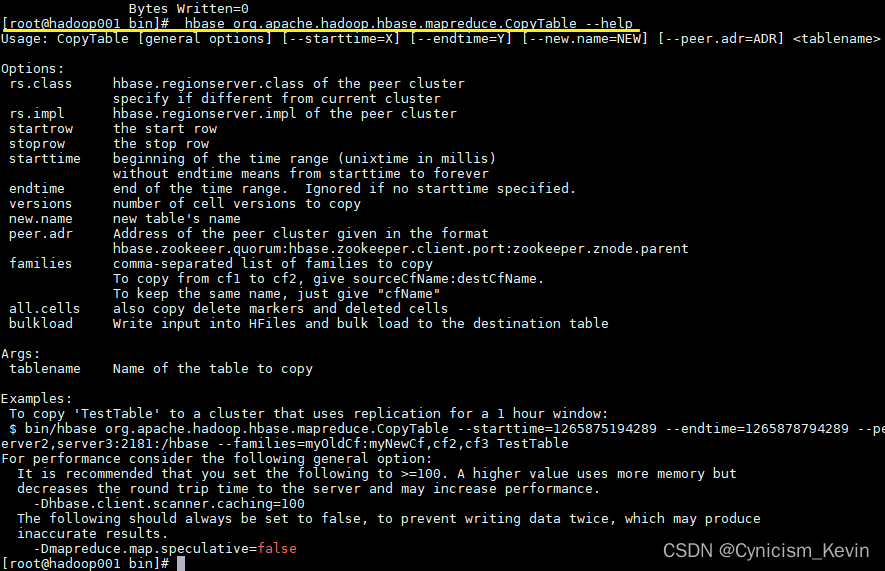
可以通过
--help查看更多支持的参数# hbase org.apache.hadoop.hbase.mapreduce.CopyTable --help- 1
三、Export/Import
3.1 简介
Export支持导出数据到 HDFS,Import支持从 HDFS 导入数据。Export还支持指定导出数据的开始时间和结束时间,因此可以用于增量备份。Export导出与CopyTable一样,依赖 HBase 的scan操作
3.2 命令格式
# Export hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]] # Inport hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>- 1
- 2
- 3
- 4
- 5
- 导出的
outputdir目录可以不用预先创建,程序会自动创建。导出完成后,导出文件的所有权将由执行导出命令的用户所拥有。 - 默认情况下,仅导出给定
Cell的最新版本,而不管历史版本。要导出多个版本,需要将<versions>参数替换为所需的版本数。
3.3 常用命令
- 导出命令
hbase org.apache.hadoop.hbase.mapreduce.Export tableName hdfs 路径/tableName.db- 1
- 导入命令
hbase org.apache.hadoop.hbase.mapreduce.Import tableName hdfs 路径/tableName.db- 1
四、Snapshot
4.1 简介
HBase 的快照 (Snapshot) 功能允许您获取表的副本 (包括内容和元数据),并且性能开销很小。因为快照存储的仅仅是表的元数据和 HFiles 的信息。快照的
clone操作会从该快照创建新表,快照的restore操作会将表的内容还原到快照节点。clone和restore操作不需要复制任何数据,因为底层 HFiles(包含 HBase 表数据的文件) 不会被修改,修改的只是表的元数据信息。4.2 配置
HBase 快照功能默认没有开启,如果要开启快照,需要在
hbase-site.xml文件中添加如下配置项:<property> <name>hbase.snapshot.enabled</name> <value>true</value> </property>- 1
- 2
- 3
- 4
4.3 常用命令
快照的所有命令都需要在 Hbase Shell 交互式命令行中执行。
1. Take a Snapshot
# 拍摄快照 hbase> snapshot '表名', '快照名'- 1
- 2
默认情况下拍摄快照之前会在内存中执行数据刷新。以保证内存中的数据包含在快照中。但是如果你不希望包含内存中的数据,则可以使用
SKIP_FLUSH选项禁止刷新。# 禁止内存刷新 hbase> snapshot '表名', '快照名', {SKIP_FLUSH => true}- 1
- 2
2. Listing Snapshots
# 获取快照列表 hbase> list_snapshots- 1
- 2
3. Deleting Snapshots
# 删除快照 hbase> delete_snapshot '快照名'- 1
- 2
4. Clone a table from snapshot
# 从现有的快照创建一张新表 hbase> clone_snapshot '快照名', '新表名'- 1
- 2
5. Restore a snapshot
将表恢复到快照节点,恢复操作需要先禁用表
hbase> disable '表名' hbase> restore_snapshot '快照名'- 1
- 2
这里需要注意的是:是如果 HBase 配置了基于 Replication 的主从复制,由于 Replication 在日志级别工作,而快照在文件系统级别工作,因此在还原之后,会出现副本与主服务器处于不同的状态的情况。这时候可以先停止同步,所有服务器还原到一致的数据点后再重新建立同步。
-
相关阅读:
阿里云优惠券如何领取(阿里云在哪领取优惠券)
微信小程序登录Test(仅供参考)
go 服务接入短信验证码功能(对接阿里云平台)
力扣 2. 两数相加
MySQL之窗口函数
SVG文件动态绘制echarts图表
内网穿透代理服务器nps使用初探(一)
React18 基础入门API、JSX语法糖
数学建模国赛 2020B-穿越沙漠 第一关 Lingo 和 C语言 动态规划求解
Android面试题--HashMap原理分析
- 原文地址:https://blog.csdn.net/mxk4869/article/details/125613589