-
(39、40)分布式
分布式
为什么要用分布式
之前: gui编写测试脚本、 CLI执行性能测试
又说 分布式:
原因: 在我们做性能测试过程中, 会遇到 并发用户数 比较大情况
比较大 是什么概念: 一台电脑,一般情况下http协议 jmeter只能产生 1000-2000之间的并发用
户数,超过2k一般就会产生不了。如果 你的被测系统 性能很好, 用
jmeter发起性能测试的电脑,能产生的并发用户数就会越
少。 如果你的被测系统性能很差, 你电脑可能能产生并发用户数越高。因为,我们每一台电脑,端口数量是有限的 最大65535个。我们每发启一次请求,会使用1个端
口, 过一段时间,这个端口会释放,又可以重复利用端口。但是,被测项目,可能超过2k左右并发用户数, 假设是4w并发用户
我们就需要用 多个机器一起来创建 并发用户数,一起向服务器发起情况
我们用一台 主控电脑master,控制n多台电脑slave,一起向服务器发起请求- 性能测试中, 分布式 master-slave
- slave助攻机器(3个点)
- jmeter.properties
- server_port 默认是1099 可以自己修改,也可以不改(自己定义端口) 端口一般是大于1024~65535之间的数值(端口约263行,记住随便自己定义:
server_port=56789) - server.rmi.port 改成 server_port相同的端口(如:
263行的server_port=56789,那么297行的server.rmi.port=56789也把端口开成一样的。)- rmi: 认证
server.rmi.ssl.disable=false 第335行,这个一定要改:server.rmi.ssl.disable=true------ 我们不使用加密认证传输方式。(因为默认是false,false是使用;true是不使用)

- slave助攻机器(3个点)
- 启动slave机器
- jmeter可以跨平台: 所以,我们的助攻机器 可以是 Windows、linux、mac系统
- 但是,我们不建议混用
- jmeter要在 jre 环境运行,而且使用jdk1.8,所以,我们的助攻机器,也要求有jdk1.8
- jmeter的版本和插件 要一致,我们有多台 助攻机器,如果版本插件不一致,-----他们的代码是有差异, 我们要助攻机器一起来执行某个请求时,可能有差异。----使用,我们要求,所有的助攻机器 jmeter版本和插件要一致。
- 打包一个机器上jmeter,传给所有机器
- 启动脚本:
jmeter-server -Djava.rmi.server.hostname=助攻机器ip
- jmeter可以跨平台: 所以,我们的助攻机器 可以是 Windows、linux、mac系统
- 操作:
- 在windows中改了jmeter.properties配置文件
- 本地jmeter打包
- 打开了一个linux电脑, jdk1.8
- 把jmeter的zip包上传到 linux电脑
- 解压 unzip xxxx.zip
- 因为我是Windows的jmeter,传到了linux助攻电脑
- 所以,我们jmeter的bin文件夹中,文件的权限是不正确
- 我也不知道,jmeter的bin文件夹中,会用到哪些文件,所以,我给所有的文件赋予
- 执行权限
- chmod +x *
- 执行启动命令
- 因为我们没有配置 JMETER_HOME环境变量
- 所以,我们在jmeter的bin文件夹中执行
./jmeter-server -Djava.rmi.server.hostname=192.168.x.x./jmeter-server -Djava.rmi.server.hostname=192.168.23.135
- 主控电脑,可以测试一下与助攻电脑的网络
- telnet 助攻机器ip 端口
主控电脑参数配置
-
jmeter.properties
-
remote_hosts 填写你的助攻电脑的ip:端口, 多个之间用逗号分割
- 这个其实是可改可不改 一般建议修改(第259行修改)
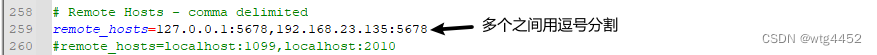
- 这个其实是可改可不改 一般建议修改(第259行修改)
-
server.rmi.ssl.disable=true -------
336行这个必须要改:server.rmi.ssl.disable=true------ 我们不使用加密认证传输方式。(因为默认是false,false是使用;true是不使用)
-
mode=Standard -----开启标准模式, ----可改可不改(第758行)
- 如果开启了,那么在jmeter的
gui图形界面中可以看到分布式机器运行的结果 - 如果没有开启,那么就看不到。

- 如果开启了,那么在jmeter的
-
-
因为是修改了属性配置文件,所以 一定要重启jmeter才生效
-
启动jmeter图像界面
- 运行下面有
- 远程启动 ------远程调用的意思
- 远程启动所有
- 运行下面有
-
注意点:
- 助攻机器,只是用于产生并发用户数,并使用这些并发用户数,来执行脚本,脚本不是由助攻机器控制。
-
助攻电脑上是否有要执行jmx脚本,都没关系
-
但是, 如果主控脚本中有 csv数据文件设置 读取一个文件,那么,助攻电脑上,就必须要有这个文件
- 解决办法:
- 在助攻机器启动 助攻服务命令启动的路径下,要有你读取的文件
- 或者 是你的 jmx脚本相同地方 要有这个路径
- 解决办法:
-
如果有多个助攻机器,所有的助攻机器,都完整复制主控的脚本场景来运行
-
- 助攻机器,只是用于产生并发用户数,并使用这些并发用户数,来执行脚本,脚本不是由助攻机器控制。
- 性能测试中, 分布式 master-slave
-
相关阅读:
LLMs可以遵循简单的规则吗?
多线程与多进程区别
Blazor OIDC 单点登录授权实例7 - Blazor hybird app 端授权
应遵循哪些 GitLab 备份最佳实践
华泰证券:达达集团(DADA)3Q23业绩前瞻:短期业绩承压
Axure原型设计工具怎么样?有替代软件吗?
手机通过WiFi连接调试UR机器人
topK问题---使用优先级队列解决
前端js八股文大全
重新认识WorkPlus,不止IM即时通讯,是企业移动应用管理专家
- 原文地址:https://blog.csdn.net/weixin_46356321/article/details/125592243