-
Flink入门
这里写目录标题
一、流处理和批处理的区别
1、流处理
数据大小未知
简单操作
及时响应
2、批处理
数据大小固定
复杂操作
需要一段时间
3、有界流和无界流
任何类型的数据都是作为事件流产生的。信用卡交易传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成
无界流:有一个开始但是没有定义的结束。他们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理时间。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理误解数据通常要求以特定顺序(例如事件发生的顺序)摄入事件,以便能够推断架构完整性。
有界流:具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存失败,源站可能有防盗链机制,建议将图片保存下来直接上传上传(imxbYnDlP7La-1656939517255)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613212016195.png)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613212016195.png)]](https://1000bd.com/contentImg/2022/07/05/100449606.png)
4、流处理的流程
数据采集———>MQ—————>计算—————>DB
5、批处理流程
数据采集————>MQ————>DB—————>计算
6、流处理特点
实时计算
数据实时到达
数据到达次序独立
数据规模达无法预知容量
再次提取数据代价大
7、批处理特点
离线计算
数据量大 周期长
复杂操作
数据固定
方便查询计算结果
8、实时计算面临的挑战
1、数据处理唯一性(如何保证数据只处理一次?至少一次?最多一次?)
2、处理数据的及时性(采集的实时数据量太大的话可能导致短时间内处理不过来,如何保证数据能够及时的处理,不出现数据堆积?)
3、数据处理层和存储层的可扩展性(如何根据采集的实时数据量的大小提供动态阔缩容?)
4、数据处理层和存储层的容错性(如何保证数据处理层和存储层高可用,出现故障时数据处理层和存储层服务依旧可用?)
二、什么是flink?
1、简介
Apache Flink是一个框架和分布式引擎,用于对有界和无界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R1NTzG51-1656939517257)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613213407117.png)]](https://1000bd.com/contentImg/2022/07/05/100450101.png)
2、feature
1、支持高吞吐、低延迟、高性能的流处理
2、支持带有事件的窗口(Window)操作
3、支持有状态计算的Exactly-once语义
4、支持高度灵活的窗口(Window)操作,支持基于time、count、session以及data-driven的窗口操作
5、支持具有反压功能的持续流模型
6、支持基于轻量级分布式快照(Snapshot)实现的容错
7、一个运行时同时支持Batch on Streaming处理和Straming处理
8、Flink在JVM内部实现了自己的内存管理,避免了出现oom
9、支持的迭代计算
10、支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
3、Blink
Blink是阿里云基于Flink开发的一个分支
在Flink1.9中已将大部分Blink功能合并到Flink
Blink在TPC-DS上和Spark相比有着非常明显的性能优势,而且这种性能优势随着数据量的增加而变得越来越大。在实际的场景这种优势已经超过spark三倍,在流计算性能上我们也取得了类似的提升。我们线上的很多典型作业,性能是原来的3-5倍。在有数据倾斜的场景,以及若干比较有挑战的TPC-H query,流计算性能甚至得到了数十倍的提升。
4、Flink技术栈
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ntd8aCvW-1656939517258)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613214811692.png)]](https://1000bd.com/contentImg/2022/07/05/100450618.png)
5、Flink APIs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H9FjnsXy-1656939517259)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613214837533.png)]](https://1000bd.com/contentImg/2022/07/05/100450919.png)
6、数据流编程模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L3tMTcah-1656939517259)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613214926600.png)]](https://1000bd.com/contentImg/2022/07/05/100451367.png)
7、Program & Dataflows
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZaXNgt39-1656939517260)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613215005147.png)]](https://1000bd.com/contentImg/2022/07/05/100451712.png)
三、Source数据源
1、Flink 在流处理和批处理的source大概有4类:
1、基于本地集合的source
2、基于文件的source
3、基于网络套接字的source
4、自定义的source。自定义的source常见的有Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi等,当然你也可以定义自己的source。
2、Transformation算子
Transformation:数据转换的各种操作
有Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll /Union / Window join / Split / Select / Project 等
操作很多,可以将数据转换计算成你想要的数据
四、Sink接收器
Flink 将转换计算后的数据发送的地点
Flink 常见的Sink 大概有如下几类:
1、写入文件
2、打印出来
3、写入socket
4、自定义的sink。自定义的sink常见的有Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem等,同理你也可以定义自己的sink
五、运行
Flink旨在以任何规模运行有状态流应用程序。应用程序可以并行化为数千个在集群中分布和同时执行的任务。因此应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且Flink可以轻松维护非常的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
用户报告了其生产环境中的运行的Flink应用程序的可扩展性数字令人印象深刻,例如:
1、应用程序每天处理数万一亿个事件
2、应用程序维护多个TB的状态
3、应用程序在数千个内核运行
六、分布式运行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OENA1A86-1656939517261)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613221100828.png)]](https://1000bd.com/contentImg/2022/07/05/100451981.png)
七、Flink架构
1、Client
Flink 作业在哪台机器上面提交,那么当前机器称之为Client。用户开发的Program代码,他会构建出DataFlow graph,然后通过Client提交给JobManager
2、JobManager
是主节点(master),相当于Spark的Driver,相当于yarn里面的ResourceManager,生产环境中需要做高可用。JobManager会将任务进行拆分,发送到TaskManager上面执行。
3、TaskManager
是从节点(slave),相当于Spark的Executor,执行task
4、执行流程
Client提交给JobManager的是一个Job,然后JobManager将Job拆分成task,提交给TashManager(worker)。JobManager与TaskManager也是基于Akka进行通信,JobManager发送指令,比如Deploy / Stop / Cancel Tasks 或者触发Checkpoint,反过来Task Manager也会跟JobManager通信返回Task Status,Heartbeat(心跳),Statistics(统计)等。另外TaskManager之间的数据通过网络进行传输,比如Data Stream做一些算子的操作,数据往往需要在TaskManager之间做数据传输。
当Flink系统启动时,首先启动JobManager和一至多个TaskManager
JobManager负责协调Flink系统,TaskManager则是执行并行程序的worker。当系统以本地形式启动时,一个JobManager和一个Taskmanager会启动在同一个JVM中。当一个程序被提交后,系统会创建一个Client来进行预处理,将程序转变成一个并行数据流的形式,交给JobManager 和TaskManager执行。
八、Programs & Dataflows
九、Parallel Dataflows
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EOYqjyQB-1656939517262)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613223117784.png)]](https://1000bd.com/contentImg/2022/07/05/100452809.png)
十、Task Slots & Resource
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ptnx6257-1656939517263)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613223158649.png)]](https://1000bd.com/contentImg/2022/07/05/100453231.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hrefvthC-1656939517264)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613223210545.png)]](https://1000bd.com/contentImg/2022/07/05/100453621.png)
十一、Flink基石
1、Checkpoint
基于Chandy-Larnport算法,实现了分布式的一致性快照,提供了一致性语义
Checkpointing
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tOPfhzIN-1656939517264)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225251715.png)]](https://1000bd.com/contentImg/2022/07/05/100453919.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z3DA7Mwd-1656939517265)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225457674.png)]](https://1000bd.com/contentImg/2022/07/05/100454371.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0snhcDzh-1656939517266)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225504963.png)]](https://1000bd.com/contentImg/2022/07/05/100454746.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TqHP9Z0K-1656939517266)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225510942.png)]](https://1000bd.com/contentImg/2022/07/05/100455043.png)
2、State
丰富State API。ValueState、ListState、MapState、BroadCaseState
Stateful Operations
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bKjt6hnT-1656939517267)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225412107.png)]](https://1000bd.com/contentImg/2022/07/05/100455309.png)
3、Time
实现了Watermark机制。乱序数据处理,迟到数据容忍
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GtGHe1mG-1656939517267)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225058927.png)]](https://1000bd.com/contentImg/2022/07/05/100455654.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cKo7VQV5-1656939517268)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225157845.png)]](https://1000bd.com/contentImg/2022/07/05/100455981.png)
4、Window
开箱即用的滚动,滑动,会话窗口,以及灵活的自定义窗口
Time Window
Session Window:如果一段时间没有数据生成一个窗口
Count Window
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cYmQI5Re-1656939517269)(C:%5CUsers%5Cstu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20220613225214340.png)]](https://1000bd.com/contentImg/2022/07/05/100456372.png)
十二、Exactly Once
1、数据生产端
kafka 0.11之后,Producer的send操作现在是幂等的,在任何导致producer重试的情况下,相同的消息如果被producer发送多次,也只会被kafka写入一次。
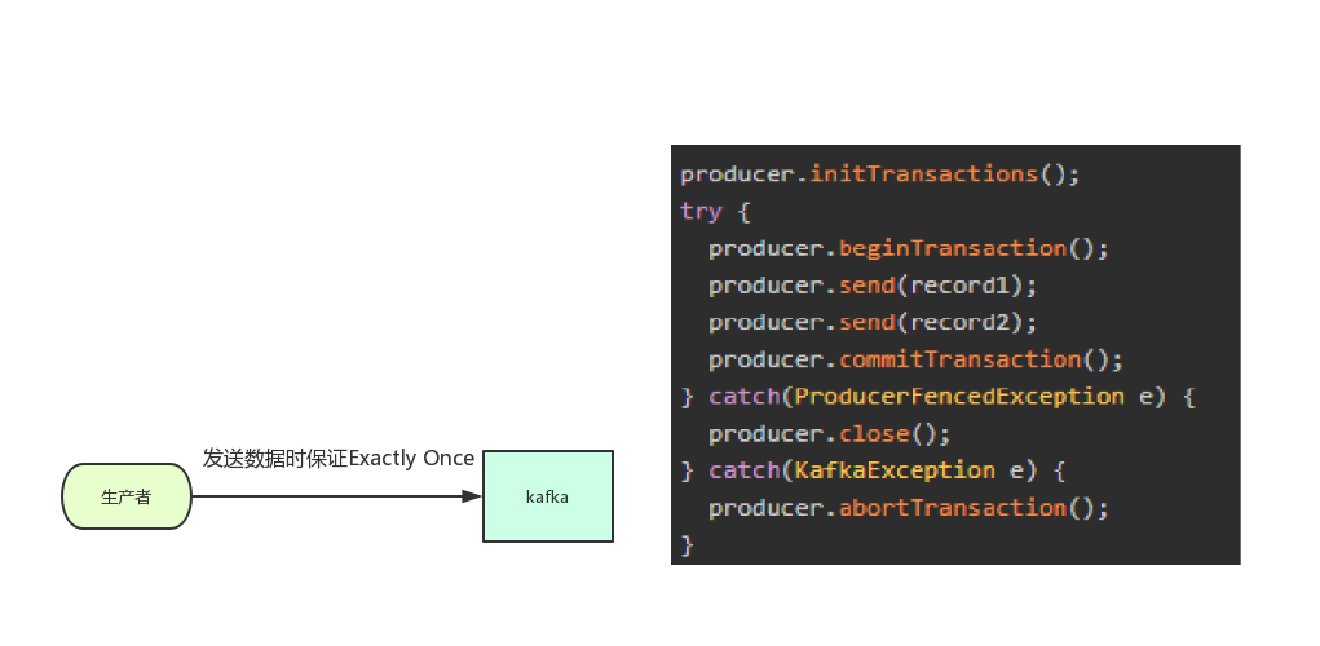
2、数据消费端
Flink分布式快照保存数据计算的状态和消费的偏移量,保证程序重启后不会丢失状态和消费偏移量- 1
![[外链图片转存中...(img-cKo7VQV5-1656939517268)]](https://1000bd.com/contentImg/2022/07/05/100457309.png)
3、Sink端
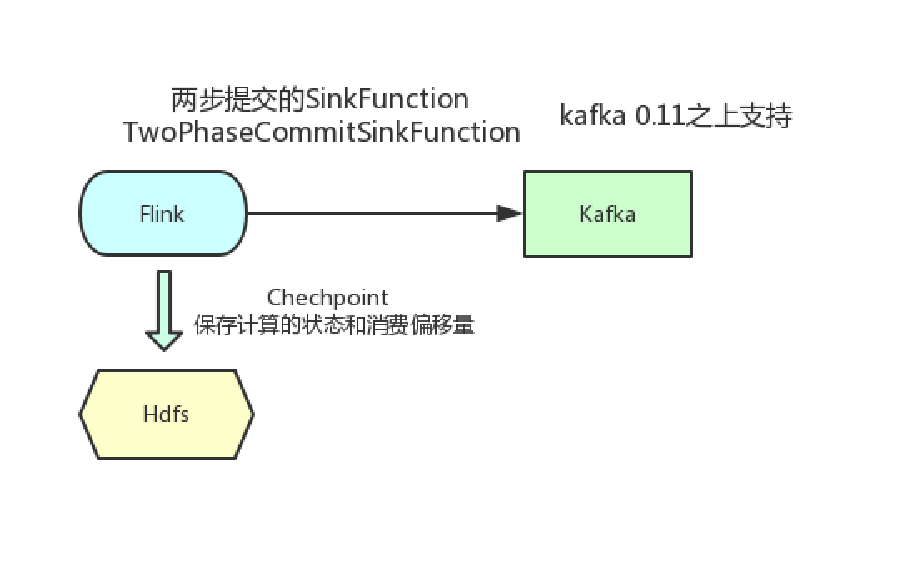
十三、Two-Phase Commit
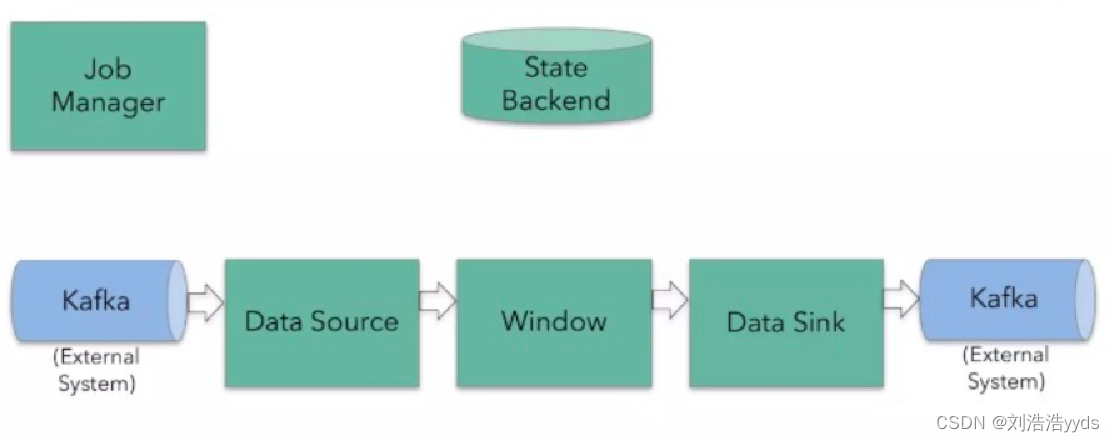
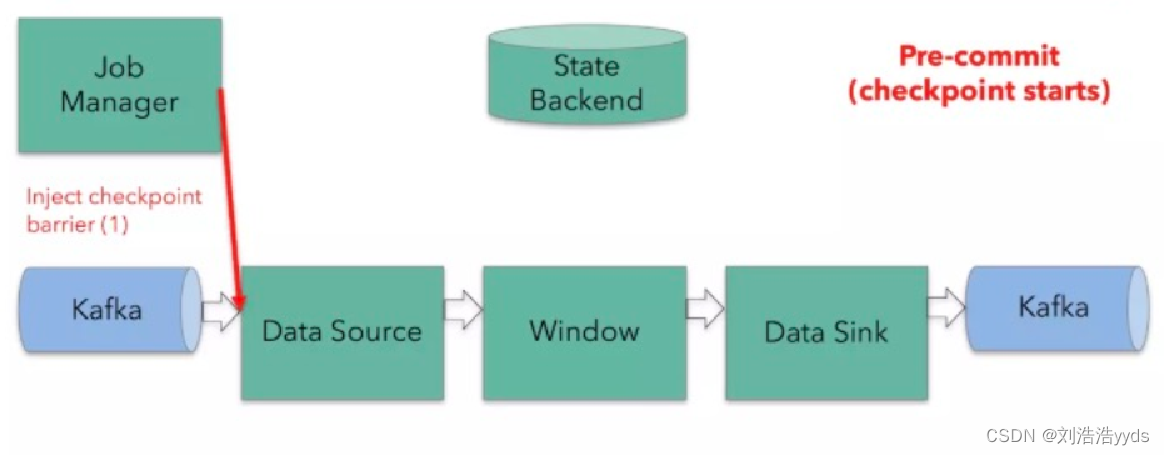
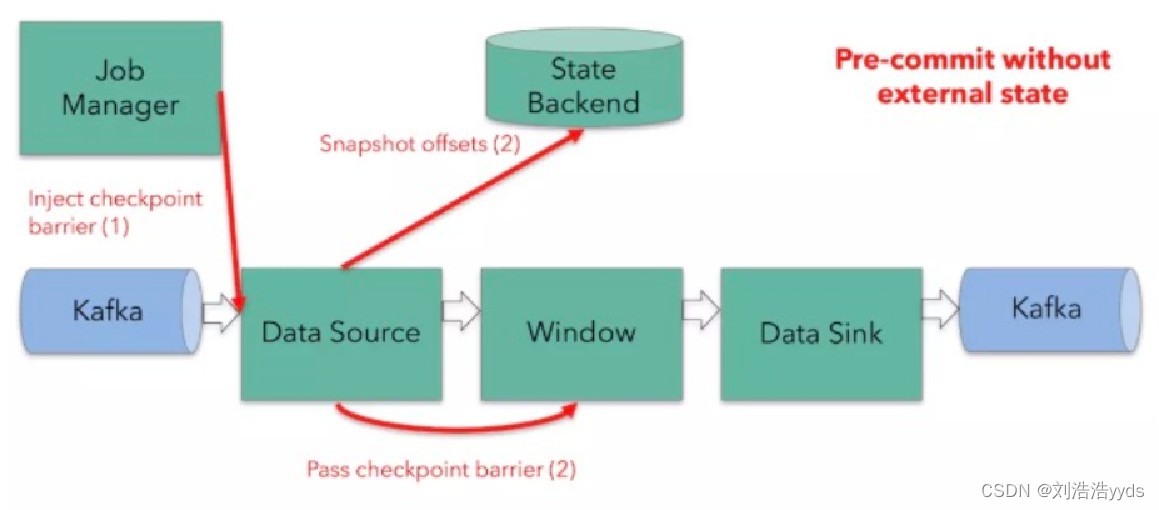
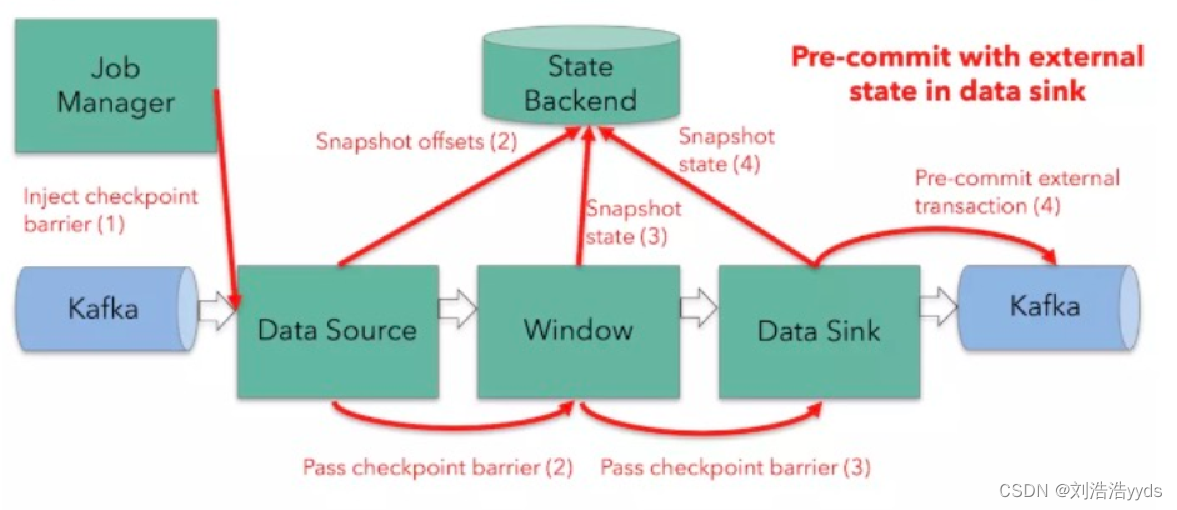
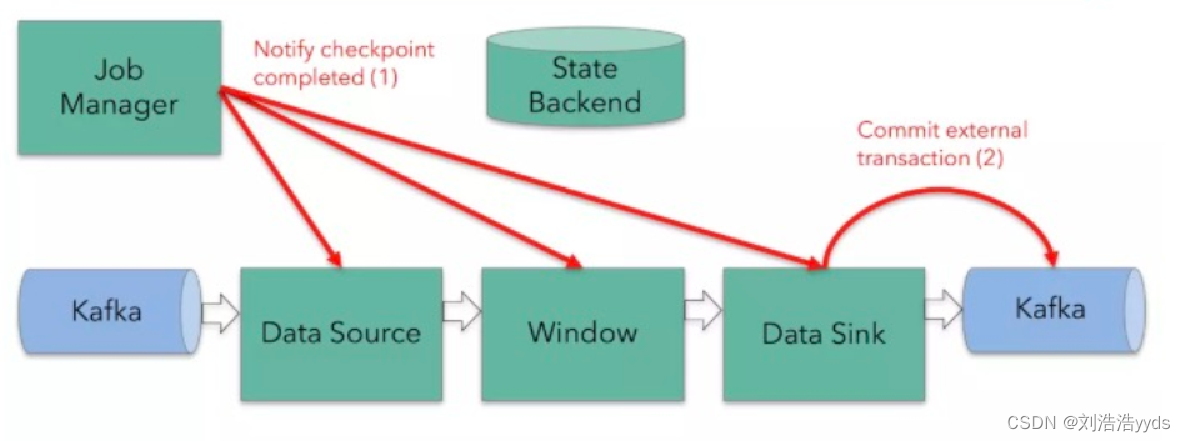
十四、Flink环境的搭建
1、Local 本地测试
1、准备工作
配置JAVA_HOME
配置免密钥
2、上传解压
tar -xvf flink-1.8.1-bin-scala_2.11.tgz
配置环境变量3、修改配置文件
vim conf/flink-conf.yaml
jobmanager.rpc.address: node1 主节点ip地址vim conf/slaves 增加从节点 node2 node3 vim conf/masters 改成主节点ip 同步到所有节点- 1
- 2
- 3
- 4
- 5
- 6
- 7
4、启动集群 在node1中执行
bin/start-cluster.shhttp://node1:8081 访问web界面
2、Standallone Cluster 独立集群
提交任务
1、在web页面提交任务2、同flink命令提交任务 ./flink run -c com.shujia.flink.StreamWordCOunt -p 2 flink-1.0.jar 3、rpc方式提交任务- 1
- 2
- 3
- 4
分布式运行
3、Flink on Yarn 推荐
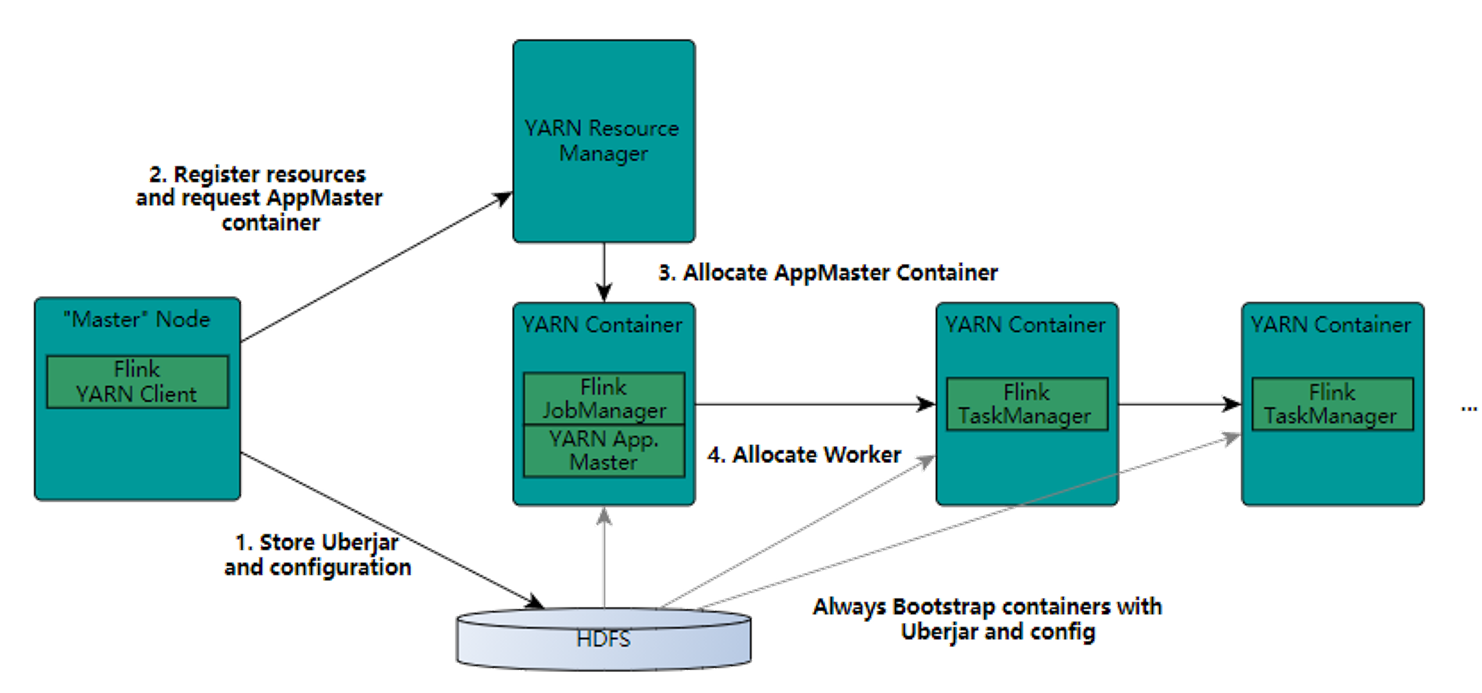
1、配置HADOOP_CONF_DIR
vim /etc/profile
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.6.0/etc/hadoop/ (hadoop conf 目录)2、将hadoop依赖jar上传到flink lib目录
flink-shaded-hadoop2-uber-2.6.5-1.8.0.jarflink和spark一样都是粗粒度资源申请
启动方式
1、yarn-session 在yarn里面启动一个flink集群 jobManager
先启动hadoop
yarn-session.sh -jm 1024m -tm 1096m提交任务 1、在web页面提交任务 2、同flink命令提交任务 flink run -c com.shujia.flink.StreamWordCOunt -p 2 flink-1.0.jar 3、rpc方式提交任务- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、直接提交任务到yarn
flink run -m yarn-cluster -p 2 -yjm 1024m -ytm 1096m -c StreamWordCOunt flink-1.0.jar -
相关阅读:
一、网络基础知识
TypeError: Cannot read properties of null (reading ‘insertBefore‘) vue项目报错
小红书携手HMS Core,畅玩高清视界,种草美好生活
学生信息管理系统(JAVA+MYSQL)
Python正则表达式(一看就懂)
软件机器人助力企业产地证自动化申报,提高竞争力,降低成本
Java学习笔记(六)——面向对象编程(基础)
VB.NET 三层登录系统实战:从设计到部署全流程详解
今天的消费情况
HTML5:七天学会基础动画网页7
- 原文地址:https://blog.csdn.net/weixin_65996579/article/details/125608581