-
喜提JDK的BUG一枚!多线程的情况下请谨慎使用这个类的stream遍历。

前段时间在 RocketMQ 的 ISSUE 里面冲浪的时候,看到一个 pr,虽说是在 RocketMQ 的地盘上发现的,但是这个玩意吧,其实和 RocketMQ 没有任何关系。
纯纯的就是 JDK 的一个 BUG。
我先问你一个问题:LinkedBlockingQueue 这个玩意是线程安全的吗?
这都是老八股文了,你要是不能脱口而出,应该是要挨板子的。

答案是:是线程安全的,因为有这两把锁的存在。

但是在 RocketMQ 的某个场景下,居然稳定复现了 LinkedBlockingQueue 线程不安全的情况。
先说结论:LinkedBlockingQueue 的 stream 遍历的方式,在多线程下是有一定问题的,可能会出现死循环。
老有意思了,这篇文章带大家盘一盘。
搞个Demo
Demo 其实都不用我搞了,前面提到的 pr 的链接是这个:
在这个链接里面,前面围绕着 RocketMQ 讨论了很多。
但是在中间部分,一个昵称叫做 areyouok 的大佬一针见血,指出了问题的所在。
直接给出了一个非常简单的复现代码。而且完全把 RocketMQ 的东西剥离了出去:

正所谓前人栽树后人乘凉,既然让我看到了 areyouok 这位大佬的代码,那我也就直接拿来当做演示的 Demo 了。
如果你不介意的话,为了表示我的尊敬,我斗胆说一声:感谢雷总的代码。

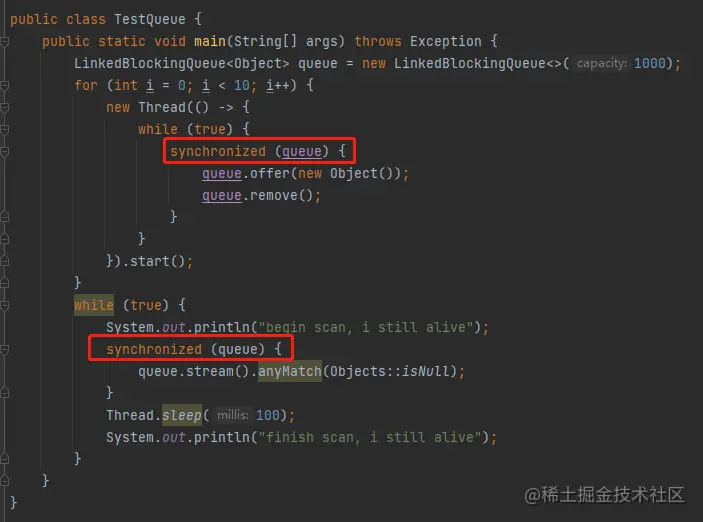
我先把雷总的代码粘出来,方便看文章的你也实际操作一把:
- public class TestQueue {
- public static void main(String[] args) throws Exception {
- LinkedBlockingQueue<Object> queue = new LinkedBlockingQueue<>(1000);
- for (int i = 0; i < 10; i++) {
- new Thread(() -> {
- while (true) {
- queue.offer(new Object());
- queue.remove();
- }
- }).start();
- }
- while (true) {
- System.out.println("begin scan, i still alive");
- queue.stream()
- .filter(o -> o == null)
- .findFirst()
- .isPresent();
- Thread.sleep(100);
- System.out.println("finish scan, i still alive");
- }
- }
- }
介绍一下上面的代码的核心逻辑。
首先是搞了 10 个线程,每个线程里面在不停的调用 offer 和 remove 方法。
需要注意的是这个 remove 方法是无参方法,意思是移除头节点。
再强调一次:LinkedBlockingQueue 里面有 ReentrantLock 锁,所以即使多个线程并发操作 offer 或者 remove 方法,也都要分别拿到锁才能操作,所以这一定是线程安全的。
然后主线程里面搞个死循环,对 queue 进行 stream 操作,看看能不能找到队列里面第一个不为空的元素。
这个 stream 操作是一个障眼法,真正的关键点在于 tryAdvance 方法:

先在这个方法这里插个眼,一会再细嗦它。

按理来说,这个方法运行起来之后,应该不停的输出这两句话才对:
- begin scan, i still alive
- finish scan, i still alive
但是,你把代码粘出去用 JDK 8 跑一把,你会发现控制台只有这个玩意:

或者只交替输出几次就没了。
但是当我们不动代码,只是替换一下 JDK 版本,比如我刚好有个 JDK 15,替换之后再次运行,交替的效果就出来了:

那么基于上面的表现,我是不是可以大胆的猜测,这是 JDK 8 版本的 BUG 呢?

现在我们有了能在 JDK 8 运行环境下稳定复现的 Demo,接下来就是定位 BUG 的原因了。
啥原因呀?
先说一下我拿到这个问题之后,排查的思路。
非常的简单,你想一想,主线程应该一直输出但是却没有输出,那么它到底是在干什么呢?
我初步怀疑是在等待锁。
怎么去验证呢?
朋友们,可爱的小相机又出现了:

通过它我可以 Dump 当前状态下各个线程都在干嘛。
但是当我看到主线程的状态是 RUNNABLE 的时候,我就有点懵逼了:

啥情况啊?
如果是在等待锁,不应该是 RUNNABLE 啊?
再来 Dump 一次,验证一下:

发现还是在 RUNNABLE,那么直接就可以排除锁等待的这个怀疑了。
我专门体现出两次 Dump 线程的这个操作,是有原因的。
因为很多朋友在 Dump 线程的时候拿着一个 Dump 文件在哪儿使劲分析,但是我觉得正确的操作应该是在不同时间点多次 Dump,对比分析不同 Dump 文件里面的相同线程分别是在干啥。
比如我两次不同时间点 Dump,发现主线程都是 RUNNABLE 状态,那么说明从程序的角度来说,主线程并没有阻塞。
但是从控制台输出的角度来说,它似乎又是阻塞住了。
经典啊,朋友们。你想想这是什么经典的画面啊?

这不就是,这个玩意吗,线程里面有个死循环:
- System.out.println("begin scan, i still alive");
- while (true) {}
- System.out.println("finish scan, i still alive");
来验证一波。
从 Dump 文件中我们可以观察到的是主线程正在执行这个方法:
at java.util.concurrent.LinkedBlockingQueue$LBQSpliterator.tryAdvance(LinkedBlockingQueue.java:950)
还记得我前面插的眼吗?
这里就是我前面说的 stream 只是障眼法,真正关键的点在于 tryAdvance 方法。
点过去看一眼 JDK 8 的 tryAdvance 方法,果不其然,里面有一个 while 循环:

从 while 条件上看是 current!=null 一直为ture,且 e!=null 一直为 false,所以跳不出这个循环。
但是从 while 循环体里面的逻辑来看,里面的 current 节点是会发生变化的:
current = current.next;
来,结合这目前有的这几个条件,我来细嗦一下。
- LinkedBlockingQueue 的数据结果是链表。
- 在 tryAdvance 方法里面出现了死循环,说明循环条件 current=null 一直是 true,e!=null 一直为 false。
- 但是循环体里面有获取下一节点的动作,current = current.next。
综上可得,当前这个链表中有一个节点是这样的:
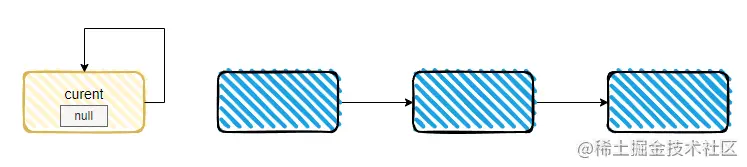
只有这样,才会同时满足这两个条件:
- current.item=null
- current.next=null
那么什么时候才会出现这样的节点呢?

这个情况就是把节点从链表上拿掉,所以肯定是调用移除节点相关的方法的时候。
纵观我们的 Demo 代码,里面和移除相关的代码就这一行:
queue.remove();
而前面说了,这个 remove 方法是移除头节点,效果和 poll 是一样一样的,它的源码里面也是直接调用了 poll 方法:

所以我们主要看一下 poll 方法的源码:
java.util.concurrent.LinkedBlockingQueue#poll()

两个标号为 ① 的地方分别是拿锁和释放锁,说明这个方法是线程安全的。
然后重点是标号为 ② 的地方,这个 dequeue 方法,这个方法就是移除头节点的方法:
java.util.concurrent.LinkedBlockingQueue#dequeue

它是怎么移除头节点的呢?
就是我框起来的部分,自己指向自己,做一个性格孤僻的节点,就完事了。
h.next=h
也就是我前面画的这个图:
那么 dequeue 方法的这个地方和 tryAdvance 方法里面的 while 循环会发生一个什么样神奇的事情呢?
这玩意还不好描述,你知道吧,所以,我决定下面给你画个图,理解起来容易一点。

画面演示
现在我已经掌握到这个 BUG 的原理了,所以为了方便我 Debug,我把实例代码也简化一下,核心逻辑不变,还是就这么几行代码,主要还是得触发 tryAdvance 方法:

首先根据代码,当 queue 队列添加完元素之后,队列是长这样的:

画个示意图是这样的:

然后,我们接着往下执行遍历的操作,也就是触发 tryAdvance 方法:

上面的图我专门多截了一个方法。
就是如果往上再看一步,触发 tryAdvance 方法的地方叫做 forEachWithCancel ,从源码上看其实也是一个循环,循环结束条件是 tryAdvance 方法返回为 false ,意思是遍历结束了。
然后我还特意把加锁和解锁的地方框起来了,意思是说明 try 方法是线程安全的,因为这个时候把 put 和 take 的锁都拿到了。
说人话就是,当某个线程在执行 tryAdvance 方法,且加锁成功之后,如果其他线程需要操作队列,那么是获取不到锁的,必须等这个线程操作完成并释放锁。
但是加锁的范围不是整个遍历期间,而是每次触发 tryAdvance 方法的时候。
而每次 tryAdvance 方法,只处理链表中的一个节点。
到这里铺垫的差不多了,接下来我就带你逐步的分析一下 tryAdvance 方法的核心源码,也就是这部分代码:

第一次触发的时候,current 对象是 null,所以会执行一个初始化的东西:
current = q.head.next;
那么这个时候 current 就是 节点 1:

。
接着执行 while 循环,这时 current!=null 条件满足,进入循环体。
在循环体里面,会执行两行代码。
第一行是这个,取出当前节点里面的值:
e = current.item;
在我的 Demo 里面,e=1。
第二行是这行代码,含义是维护 current 为下一节点,等着下次 tryAdvance 方法触发的时候直接拿来用:
current = current.next;

接着因为 e!=null,所以 break 结束循环:

第一次 tryAdvance 方法执行完成之后,current 指向的是这个位置的节点:

朋友们,接下来有意思的就来了。
假设第二次 tryAdvance 方法触发的时候,执行到下面框起来的部分的任意一行代码,也就是还没有获取锁或者获取不到锁的时候:

这时候有另外一个线程来了,它在执行 remove() 方法,不断的移除头结点。
执行三次 remove() 方法之后,链表就变成了这样:

接下来,当我把这两个图合并在一起的时候,就是见证奇迹的时候:

当第三次执行 remover 方法后,tryAdvance 方法再次成功抢到锁,开始执行,从我们的上帝视角,看到的是这样的场景:

这一点,我可以从 Debug 的视图里面进行验证:

可以看到,current 的 next 节点还是它自己,而且它们都是 LinkedBlockingQueue$Mode@701 这个对象,并不为 null。
所以这个地方的死循环就是这么来的。

分析完了之后,你再回想一下这个过程,其实这个问题是不是并没有想象的那么困难。
你要相信,只要给到你能稳定复现的代码,一切 BUG 都是能够调试出来的。
我在调试的过程中,还想到了另外一个问题:如果我调用的是这个 remove 方法呢,移除指定元素。

会不会出现一样的问题呢?
我也不知道,但是很简单,实验一把就知道了。
还是在 tryAdvance 方法里面打上断点,然后在第二次触发 tryAdvance 方法之后,通过 Alt+F8 调出 Evaluate 功能,分别执行 queue.remove 1,2,3:

然后观察 current 元素,并没有出现自己指向自己的情况:

为什么呢?
源码之下无秘密。

答案就写在 unlink 方法里面:

入参中的 p 是要移除的节点,而 trail 是要移除的节点的上一个节点。
在源码里面只看到了 trail.next=p.next,也就是通过指针,跳过要移除的节点。
但是并没有看到前面 dequeue 方法中出现的类似于 p.next=p 的源码,也就是把节点的下一个节点指向自己的动作。
为什么?

作者都在注释里面给你写清楚了:
p.next is not changed, to allow iterators that are traversing p to maintain their weak-consistency guarantee.
p.next 没有发生改变,因为在设计上是为了保持正在遍历 p 的迭代器的弱一致性。说人话就是:这玩意不能指向自己啊,指向自己了要是这个节点正在被迭代器执行,那不是完犊子了吗?
所以带参的 remove 方法是考虑到了迭代器的情况,但是无参的 remove 方法,确实考虑不周。
怎么修复的?
我在 JDK 的 BUG 库里面搜了一下,其实这个问题 2016 年就出现在了 JDK 的 BUG 列表里面:

在 JDK9 的版本里面完成了修复。
我本地有一份 JDK15 的源码,所以给你对比着 JDK8 的源码看一下:

主要的变化是在 try 的代码块里面。
JDK15 的源码里面调用了一个 succ 方法,从方法上的注释也可以看出来就是专门修复这个 BUG 的:

比如回到这个场景下:

我们来细嗦一下当前这个情况下, succ 方法是怎么处理的:
- Node<E> succ(Node<E> p) {
- if (p == (p = p.next))
- p = head.next;
- return p;
- }
p 是上图中的 current 对应的元素。
首先 p = p.next 还是 p,因为它自己指向自己了,这个没毛病吧?
那么 p == (p = p.next),带入条件,就是 p==p,条件为 true,这个没毛病吧?
所以执行 p = head.next,从上图中来看,head.next 就是元素为 4 的这个节点,没毛病吧?
最后取到了元素 4,也就是最后一个元素,接着结束循环:

没有死循环,完美。
延伸一下
回到我这篇文章开篇的一个问题:LinkedBlockingQueue 这个玩意是线程安全的吗?
下次你面试的时候遇到这个问题,你就微微一笑,答到:由于内部有读写锁的存在,这个玩意一般情况下是线程安全的。但是,在 JDK8 的场景下,当它遇到 stream 操作的时候,又有其他线程在调用无参的 remove 方法,会有一定几率出现死循环的情况。
说的时候自信一点,一般情况下,可以唬一下面试官。
前面我给的解决方案是升级 JDK 版本,但是你知道的,这是一个大动作,一般来说,能跑就不要轻举妄动,
所以另外我还能想到两个方案。
第一个你就别用 stream 了呗,老老实实的使用迭代器循环,它不香吗?
第二个方案是这样的:
效果杠杠的,绝对没问题。
你内部的 ReentrantLock 算啥,我直接给你来个锁提升,外部用 synchronized 给你包裹起来。
来,你有本事再给我表演一个线程不安全。

现在,我换一个问题问你:ConcurrentHashMap 是线程安全的吗?
我之前写过,这玩意在 JDK8 下也是有死循环的《震惊!ConcurrentHashMap里面也有死循环,作者留下的“彩蛋”了解一下?》
在文章的最后我也问了一样的问题。
当时的回答再次搬运一下:
是的,ConcurrentHashMap 本身一定是线程安全的。但是,如果你使用不当还是有可能会出现线程不安全的情况。
给大家看一点 Spring 中的源码吧:
org.springframework.core.SimpleAliasRegistry
在这个类中,aliasMap 是 ConcurrentHashMap 类型的:


在 registerAlias 和 getAliases 方法中,都有对 aliasMap 进行操作的代码,但是在操作之前都是用 synchronized 把 aliasMap 锁住了。
为什么我们操作 ConcurrentHashMap 的时候还要加锁呢?

这个是根据场景而定的,这个别名管理器,在这里加锁应该是为了避免多个线程操作 ConcurrentHashMap 。
虽然 ConcurrentHashMap 是线程安全的,但是假设如果一个线程 put,一个线程 get,在这个代码的场景里面是不允许的。
具体情况,需要具体分析。
如果觉得不太好理解的话我举一个 Redis 的例子。
Redis 的 get、set 方法都是线程安全的吧。但是你如果先 get 再 set,那么在多线程的情况下还是会有问题的。
因为这两个操作不是原子性的。所以 incr 就应运而生了。
我举这个例子的是想说线程安全与否不是绝对的,要看场景。给你一个线程安全的容器,你使用不当还是会有线程安全的问题。
再比如,HashMap 一定是线程不安全的吗?
说不能说的这么死吧。它是一个线程不安全的容器。但是如果我的使用场景是只读呢?
在这个只读的场景下,它就是线程安全的。
总之,看场景,不要脱离场景讨论问题。
道理,就是这么一个道理。

最后,再说一次结论:LinkedBlockingQueue 的 stream 遍历的方式,在多线程下是有一定问题的,可能会出现死循环。

-
相关阅读:
Mac M2/M3 芯片环境配置以及常用软件安装-前端
【Java 进阶篇】JDBC Statement:执行 SQL 语句的重要接口
用户画像知识点补充——多数据源
自知则知之做做做做做做做做做做做做做
servlet01初级
Linux操作系统的基础指令
用Python实现广度优先搜索
原型对象、实例、原型链的联系
PyQT5 普通按钮互斥选中
三步建立自己的电影网站 1 (安装MacCMS10)
- 原文地址:https://blog.csdn.net/m0_71777195/article/details/125600536
