-
Effectively Learning Spatial Indices(VLDB)
机器学习,尤其是深度学习,被越来越多地用于更好地解决数据管理任务,这些任务以前是通过其他方法解决的,包括数据库索引。最近的一项研究表明,神经网络不仅可以学习预测与一维搜索键相关的数据值的磁盘地址,而且还可以超过基于b树的索引,从而有望加快大量依赖b树进行高效数据访问的数据库查询。研究二维空间数据索引的学习问题。神经网络的直接应用是没有吸引力的,因为空间点数据没有明显的顺序。相反,我们引入了一种基于秩空间的排序技术来建立点数据的排序,并将点分组为块进行索引学习。为了实现可伸缩性,我们提出了一种递归策略,该策略对一个大的点集进行分区,并学习每个分区的索引。在超过1亿个点的真实数据集和合成数据集上的实验表明,我们的学习指标是非常有效和高效的。使用我们的索引进行查询处理比使用r -树或最近提出的学习索引要快一个数量级。
读者总结:1)文中使用学习索引方式进行查询,从实验结果看学习索引,除了创建索引的时间较长以外,查询响应时间,回召率,索引大小等都明显好过传统的索引效果。
2)其次,在空间数据查询中,主要是要考虑使用z-order排序方法,对数据点或者空间位置进行排序,这是很有必要进行处理的过程。主要是为了产生有序的序列。这点在时间序列上是值得学习的
背景:1)为了处理空间查询,使用了R-trees[16]、kd-trees[5]和quadtrees[12]等索引。
2)学习index。数据库索引被表述为函数f,它将搜索键映射到存储相应数据对象的存储地址。给定一个学习过的函数,可以通过函数调用来定位对象。
3)考虑到学习一维数据索引的性能优势,我们学习了空间数据索引,重点关注点数据。
4)To order spatial points in order to learn an index, an existing solution, the Z-order model [46], uses a space-filling curve (SFC), i.e., the Z-curve [35].

方案:
将数据点映射到一个秩空间,使用SFC将它们在秩空间中排序,并将每个B有序点打包到一个磁盘块(B表示块大小),形成一个r -树。这使得在数据点的曲线值之间产生更均匀的间隙,从而简化了要学习的函数f。我们递归地划分数据集(在原始数据空间中),直到每个划分允许一个简单的前馈神经网络(FFN)学习一个准确的函数f。
框架:
LEARNING A SPATIAL INDEX
给定n个点的集合P = {p1, p2,…, pn}在d维欧氏空间中,我们的目标是在结构M中索引P,以便高效地进行查询处理。我们考虑点、窗口(范围)和k个最近邻(kNN)查询
3.1 Index Structure

1)Ordering points.

创建一个有序的点
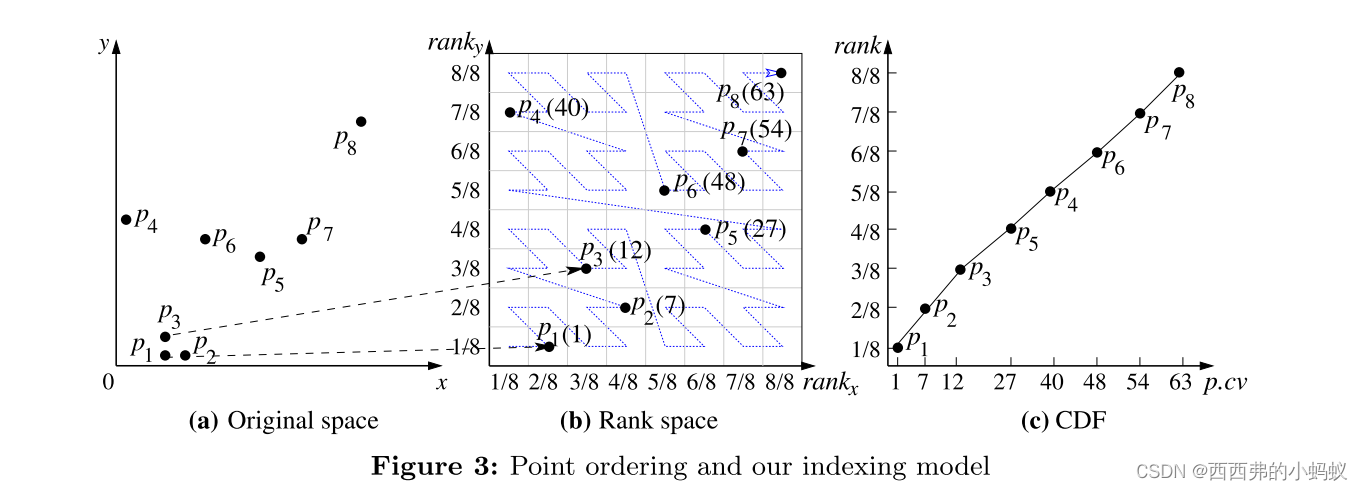
2)Model learning.



QUERY PROCESSING
1)Point Queries
点查询是通过递归调用RSMI中的子模型来完成的,使用查询点q的坐标作为输入
 这个过程一直持续到到达叶模型为止
这个过程一直持续到到达叶模型为止相当于 不断的递归调用下层模型RMI
2)Window Queries

中间的实心矩形表示一个窗口查询q, q中的网格被SFC的几个红色段覆盖,处理查询q意味着找到q中曲线段对应的点,对于每个曲线段,如果我们能定位到该曲线段的最小值和最大值所对应的点的存储位置,那么曲线段上的其他点就必须被存储
K Nearest Neighbor Queries
我们可以使用r -树kNN算法(例如,最佳优先算法[40]),或者使用带有mbr的RSMI精确计算kNN。
我们的近似kNN算法遵循经典的搜索区域扩展范式。它从查询点q周围的一个小搜索区域开始,一直扩展,直到找到k个点。
6. EXPERIMENTS




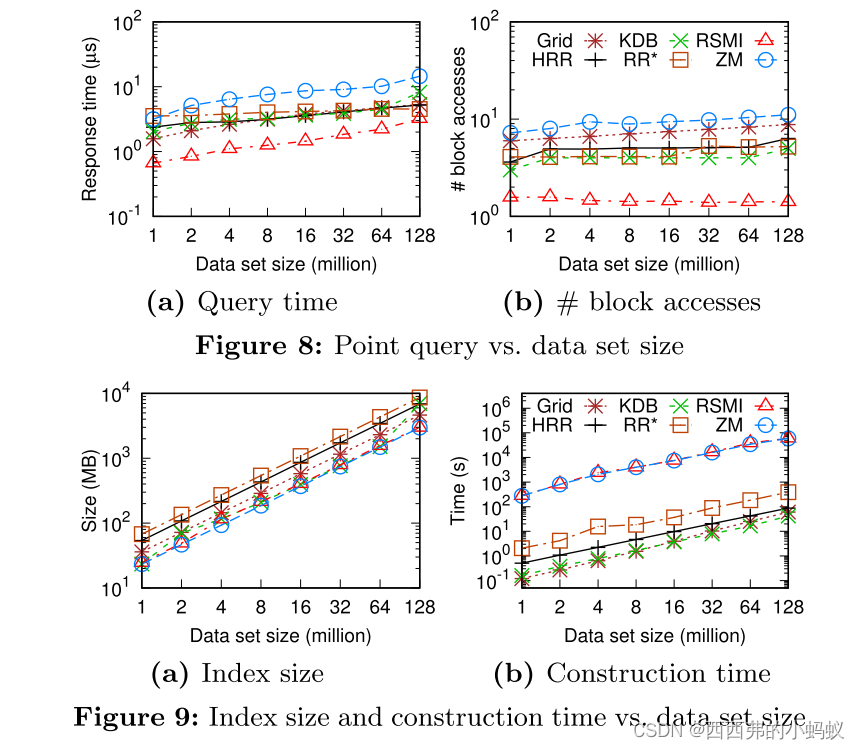
看的出来,索引构造时间一般比较长,但是磁盘页面访问时间比较短。索引大小也很小。RSMI可以学习更多层次的结构,其中叶子模型更紧凑,产生更准确的预测和更少的块访问。

-
相关阅读:
【算法日志】单调栈: 单调栈简介及其应用
每日提醒按时完成各项任务的手机app有什么?
seata处理分布式事务
demo_xml.cpp
CAD安装与经典模式设置
【多线程 (二)】线程安全问题、同步代码块、同步方法、Lock锁、死锁
优化理论20---插值法: Newton插值、差商、差分
SpringCloudAlibaba Gateway(一)简单集成
26 主成分分析
Fiddler抓包工具安装使用
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/125595451