-
HashMap如何确定数组位置
1.HashMap 底层数据结构
HashMap 底层数据结构为数组+链表+红黑树,当map去put的时候,元素先定位到数组的位置,如果有多个元素定位到了数组的同一个位置,就会生成链表,当链表长度大于8并且数组长度大于64时,会转换为红黑树。
2.元素是如何定位到数组位置的
先看put方法
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }- 1
- 2
- 3
数组位置定位:
第一步:hash运算static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 1
- 2
- 3
- 4
第二步:用第一步的值与数组容量取余
i = (n - 1) & hash- 1
因为hashmap的容量大小是2的幂次方,所以可以通过&运算来优化%运算。例如:(16 % 5 )等价于 (16 & (5 - 1))

3.与(&) 、 异或(^)、或(|)
位与(&) : 0 & 0 = 0 0 & 1 = 0 1 & 0 = 0 1 & 1 =1 位异或(^): 0 ^ 0 = 0 0 ^ 1 = 1 1 ^ 0 = 1 1 ^ 1 = 0 按位或(|): 0 | 0 = 0 0 | 1 = 1 1 | 0 = 1 1 | 1 = 1- 1
- 2
- 3
- 4
- 5
4.位置计算
hash = (h = key.hashCode()) ^ (h >>> 16)
最终位置 = (n - 1) & hash在 Java 中,hashCode 是 int 类型,经过hash运算后得到的值也是int类型,即32 位,前16位为高位,后16位为低位。
(h = key.hashCode()) ^ (h >>> 16) 的含义就是将hashCode的高位与低位做异或运算。现在假设key.hashCode = 65536(2^16) ,数组大小为n=16 ,位置计算过程如下:
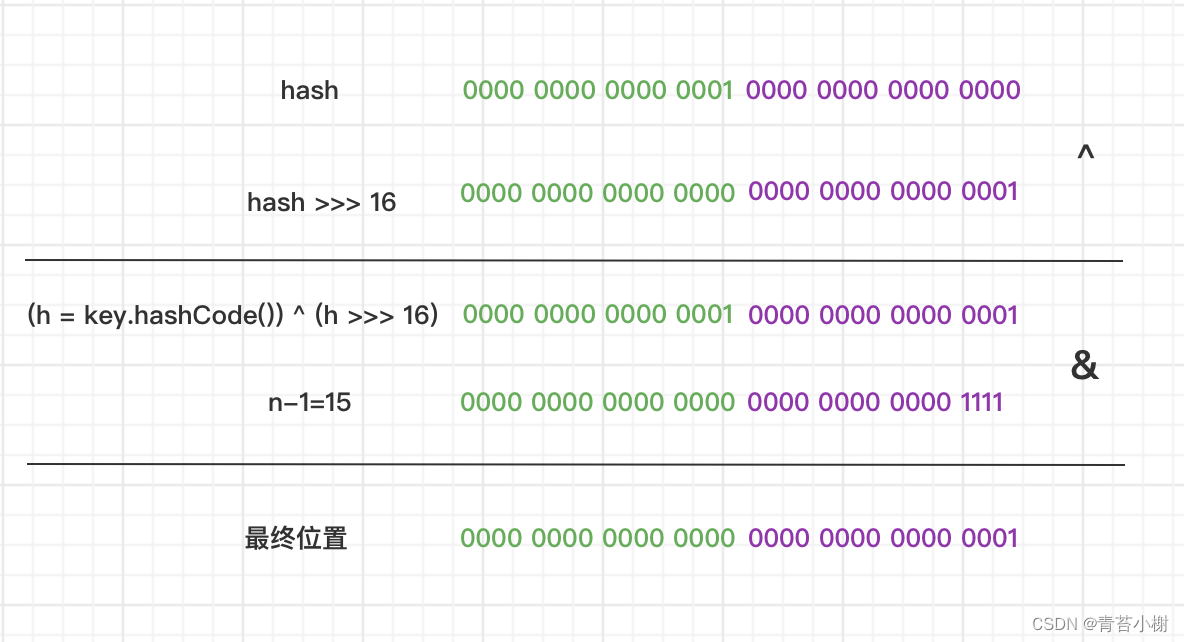
所以最终得到位置1 , 即hashCode = 65536 的key,放在数组1的位置。
5.这样做的好处是什么?
我们试想一下,如果key.hashCode >= 65536(2^16) ,而数组的大小只有16、32、64、128 等大小(分布在低16位),如果只做取余操作,那么高16位的值其实是无法参与到运算的,那key.hashCode >= 65536的所有key都是不是都会定位到同一位置?
让hashCode右移16位, 是让hashCode的高位也参与到取模运算中,这样就可以使得键值对分布的更加均匀。6.总结
好记性不如烂笔头,知道不如做到。

-
相关阅读:
Electron 进程间通信的四种方式
VScode运行C/C++
C语言之数组练习题
关于cvxpy库使用过程中的一个warning
RBAC模型 && 各表设计与梳理
OceanBase TableAPI实践案例(Java)
VBA处理数据与Python Pandas处理数据案例比较分析
Ubuntu 22.04 x86_64 OVF (sysin)
Python 3速查表
MySQL事务
- 原文地址:https://blog.csdn.net/zjy15203167987/article/details/125543956