-
大数据之排序
前言
#博学谷IT学习技术支持#
本周接触到跟排序相关的知识点有二分查找、冒泡排序和快速排序,你可能会很奇怪,二分查找怎么会跟排序有关系,从下文就能了解到其中的原有。一、冒泡排序
(一)简介
冒泡排序是一种比较直观简单的排序方法,遍历数组,比较数组中的元素,若元素符合条件,则调换两个元素的位置,需要注意的是,冒泡排序比较的是两个相邻的元素,若前一个元素值大于后一个元素值,则调整这两个元素的位置。
以下引用网上的冒泡排序动图,从动态可以很清楚的看到,每次循环都是相邻两个元素做比较,这是冒泡排序的核心。
(二)代码演示
冒泡排序使用两层嵌套的for循环,第一个for循环代表循环的次数,而第二层循环则代表每次循环的范围,由于冒泡循环每次遍历都可以找出一个最值,所以下一次循环比较的元素可以少一个;
于是乎,每次循环的都可以范围都从索引为0的位置开始,到【数组的长度-1-i】结束。
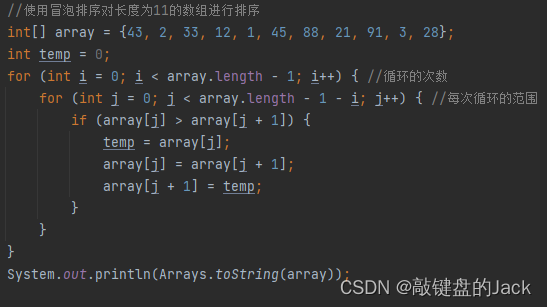
执行结果为:

二、二分查找
二分查找每次都可以减少一半的搜索范围,同时使用二分查找的条件是数组必须是有序的,所以每次使用二分查找前需要保证数组的元素是有序的,可以结合刚刚讲到的冒泡排序分享该知识点;
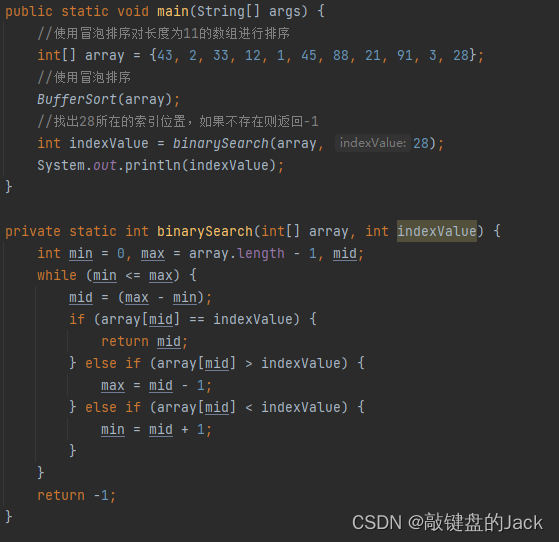
假设遇到一个需求,从刚刚的数组中找出28所在的位置,如果没有找到则结果为-1,数组为:

排序后的结果为:

解题思路为:
(1)将数组进行排序
(2)定义min和max两个int型变量,分别代表array数组的最小值和最大值
(3)定义mid中位值
(4)当min值小于或等于max时,该值为(max-min)/2
(5)如果mid所在索引的元素值等于目标值28,则之间返回mid值
(6)如果mid所在索引的元素值大于目标值28,max值为mid-1
(7)如果mid所在索引的元素值小于目标值28,min值为mid+1
(8)当min大于max时还未找出目标值,则直接返回-1
按照解题思路就可以写出对应的代码,所以直接上图,结果为5.
三、快速排序
(一)递归
快速排序涉及到的知识点是递归,递归最简单粗暴的理解就是一直调用自己本身,需要注意的是递归中一定要有出口,否则将一直调用,根本停不下来。
这里通过一个求5的阶乘案例了解递归:
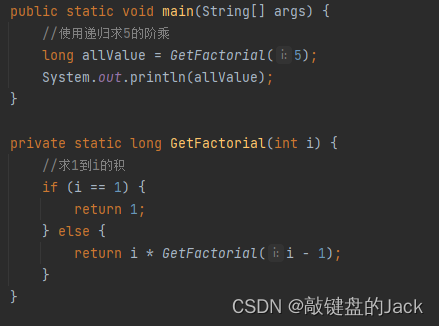
结果显而易见是120。

(二)快排简介
快速排序称为快排,排序的数据量大的话效率非常高,从数组中找出一个基准数(一般做法取的都是数组的0号索引的元素值作为基准数),分别从数组最小索引和最大索引值向数组中间靠拢;
这里咱们称最小索引值向中间靠拢的方向为左边,那么另一边就是右边,左边负责找出比基准数大的元素值,而右边负责找出比基准数小的元素值,两边分别找到后,调用两侧的元素值,直到中间位置为止,到达中间位置的索引值时,则调换基准数和中间索引值的元素值位置,调整基准数位置后,就能找到基准数在数组中应在的位置,这就是快排的核心,结合递归就能进行快速排序。
引用网上的快排动图会更好理解,该动图仅作为理解,与上述方式有些出入:
直接上代码:
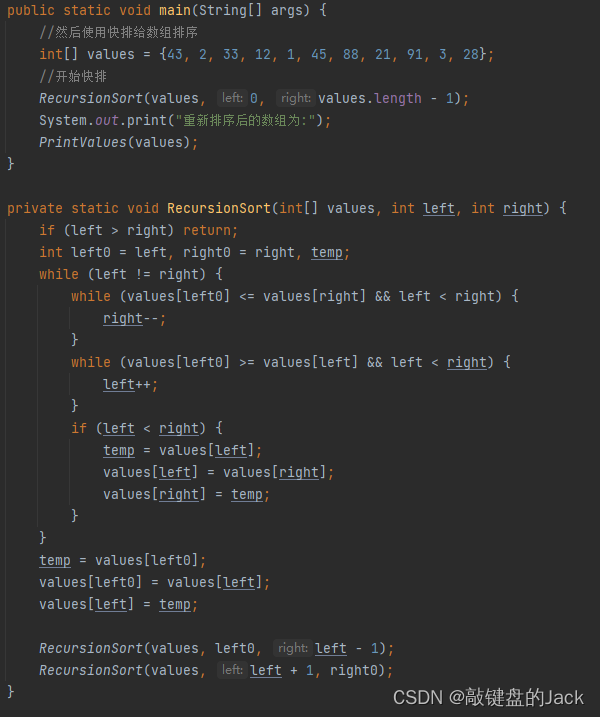
快排的结果与冒泡排序的结果一致,但是快排的效率在这种情况下比冒泡排序高。
总结
二分法执行一次可以去掉一半的比较对象;冒泡排序是相邻两个元素间的比较,加上一定逻辑的遍历;快速排序每次都可以找到基准数应在的位置,所以每次也可以减少比较的对象。
-
相关阅读:
redis学习笔记(二)--redis实现原理相关
运营商大数据怎样对目标客户群体进行精准定位?
执行事务合伙人和法人区别是什么
Matlab:Matlab 软件学习之GUI图像用户界面简介(工具栏/菜单栏/对话框)、GUI界面设计案例应用(设计二级菜单栏)之详细攻略
学生作业管理系统的设计与实现-计算机毕业设计源码20912
数据库系列MySQL:优化配置文件
机器人导航必备的栅格地图数学模型及使用
舞伴问题代码
计算机毕业设计Java游泳馆管理平台(系统+程序+mysql数据库+Lw文档)
“免费项目管理软件”20款大盘点!你认识哪几款?
- 原文地址:https://blog.csdn.net/weixin_43339889/article/details/125590843