-
三种经典的缓存使用模式
一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性 : 这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么, 用户体验好,但实现起来往往对系统的性能影响大;
- 弱一致性 : 这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但 会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态;
- 最终一致性 :最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。 这里之所以将最终一致性单独提出来,是因为它是 弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型;
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据 不一致性 的问题。一般我们是如何使用缓存呢? 有三种经典的缓存使用模式:
- Cache-Aside Pattern
- Read-Through/Write-through
- Write-behind
一、Cache-Aside读流程
Cache-Aside Pattern 的读请求流程如下:
- 读的时候,先读缓存,缓存命中的话,直接返回数据
- 缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。

Cache-Aside Pattern 的写请求流程如下:
更新的时候,先 更新数据库,然后再删除缓存 。

二、Read-Through/Write-Through(读写穿透)
Read/Write-Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过 抽象缓存层 完成的。
Read-Through
- 从缓存读取数据,读到直接返回
- 如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
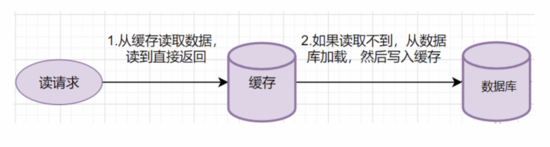
这个简要流程是不是跟 Cache-Aside 很像呢?其实 Read-Through 就是多了一层 Cache-Provider 而已,流程如下:

Write-Through
Write-Through模式下,当发生写请求时,也是由 缓存抽象层 完成数据源和缓存数据的更新,流程如下:

三、Write-behind (异步缓存写入)
Write-behind跟Read-Through/Write-Through有相似的地方,都是由 Cache Provider 来负责缓存和数据库的读写。它们又有个很大的不同: Read/Write-Through 是同步更新缓存和数据的, Write-Behind 则是只更新缓存,不直接更新数据库,通过 批量异步 的方式来更新数据库。

缓存和数据库的一致性不强, 对一致性要求高的系统要谨慎使用 。但是它适合频繁写的场景,MySQL的 InnoDB Buffer Pool机制 就使用到这种模式。
-
相关阅读:
[CSP-S 2022] 策略游戏
C#,图颜色问题(MCP,M-coloring problem)的回溯(Backtracking)算法与源代码
[MAUI]深入了解.NET MAUI Blazor与Vue的混合开发
STL—— unordered_set、unordered_map的介绍及使用
多目标优化算法:基于非支配排序的高尔夫优化算法(NSGOA)MATLAB
java基于springboot的学生公寓管理系统
湖北大学2024年成人高考函授报名高起专大数据与会计专业介绍
从To C到To B、To G,多多云科技如何实现转型
apt和dpkg的源码下载链接
Sentinel vs Hystrix 限流到底怎么选?(荣耀典藏版)
- 原文地址:https://blog.csdn.net/java_beautiful/article/details/125572302