-
DBNet:具有可微分二值化的实时场景文本检测
摘要
最近,基于分割的方法在场景文本检测中非常流行,因为分割结果可以更准确地描述曲线文本等各种形状的场景文本。然而,二值化的后处理对于基于分割的检测至关重要,它将分割方法产生的概率图转换为文本的边界框/区域。在本文中,我们提出了一个名为Differential Binarization (DB) 的模块,它可以在分割网络中执行二值化过程。与 DB 模块一起优化后,分割网络可以自适应地设置二值化阈值,这不仅简化了后处理,但也提高了文本检测的性能。基于一个简单的分割网络,我们在五个基准数据集上验证了 DB 的性能改进,在检测精度和速度方面始终达到最先进的结果。特别是,对于轻量级主干,DB 的性能改进是显着的,因此我们可以在检测精度之间寻找理想的权衡和效率。具体来说,借助 ResNet-18 的主干,我们的检测器在 MSRA-TD500 数据集上实现了 82.8 的 F-measure,以 62 FPS 的速度运行。代码位于:https://github.com/MhLiao/DB。
一、介绍
近年来,场景图像中的文本阅读因其在图像/视频理解、视觉搜索、自动驾驶、盲人辅助等方面的广泛实际应用而成为一个活跃的研究领域。
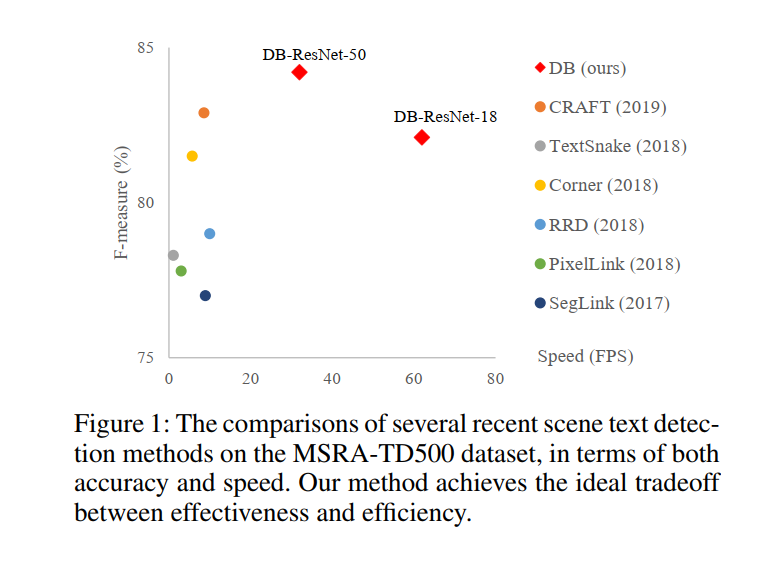
作为场景文本阅读的关键组成部分,旨在定位每个文本实例的边界框或区域的场景文本检测仍然是一项具有挑战性的任务,因为场景文本通常具有各种比例和形状,包括水平、多向和弯曲文本。基于分割的场景文本检测最近引起了很多关注,因为它可以描述各种形状的文本,这得益于其在像素级的预测结果。然而,大多数基于分割的方法需要复杂的后处理来将像素级预测结果分组到检测到的文本实例中,从而导致推理过程中的大量时间成本。以最近两种最先进的场景文本检测方法为例:PSENet (Wang et al. 2019a) 提出了渐进式尺度扩展的后处理,以提高检测精度; Pixel embedding in (Tian et al. 2019) 用于根据分割结果对像素进行聚类,需要计算像素之间的特征距离。

现有的大多数检测方法都使用类似的后处理流程,如图 2 所示(沿蓝色箭头方向):首先,它们设置一个固定阈值,用于将分割网络产生的概率图转换为二值图像; 然后,一些启发式技术(如像素聚类)用于将像素分组到文本实例中。 或者,我们的管道(按照图 2 中的红色箭头)旨在将二值化操作插入分割网络以进行联合优化。 通过这种方式,可以自适应地预测图像每个位置的阈值,从而可以将像素与前景和背景充分区分开来。 然而,标准的二值化函数是不可微的,我们提出了一个近似的二值化函数,称为可微二值化 (DB),它在与分割网络一起训练时是完全可微的。
本文的主要贡献是提出的可微分 DB 模块,这使得二值化过程在 CNN 中端到端可训练。通过将用于语义分割的简单网络和所提出的 DB 模块相结合,我们提出了一种鲁棒且快速的场景文本检测器。从使用 DB 模块的性能评估中观察,我们发现我们的检测器与以前最先进的基于分割的方法相比具有几个突出的优势。- 我们的方法在五个场景文本基准数据集上取得了始终如一的更好性能,包括水平文本、多向文本和弯曲文本。
- 我们的方法比以前的领先方法执行得更快,因为 DB 可以提供高度鲁棒的二值化图,显着简化后处理。
- DB 在使用轻量级主干时效果很好,这显着提高了 ResNet-18 主干的检测性能。
- 由于可以在推理阶段删除数据库而不牺牲性能,因此没有额外的内存/时间成本进行测试。
相关工作
最近的场景文本检测方法大致可以分为两类:基于回归的方法和基于分割的方法。
基于回归的方法是一系列直接回归文本实例的边界框的模型。 TextBoxes (Liao et al. 2017) 基于 SSD (Liu et al.2016) 修改了锚点和卷积核的尺度,用于文本检测。 TextBoxes++ (Liao, Shi, and Bai 2018) 和 DMPNet (Liu and Jin 2017) 应用四边形回归来检测多向文本。 SSTD (He et al.2017a) 提出了一种注意力机制来粗略地识别文本区域。 RRD (Liao et al. 2018) 通过使用旋转不变特征进行分类和使用旋转敏感特征进行回归将分类和回归解耦,以更好地处理多向和长文本实例。 EAST (Zhou et al. 2017) 和 DeepReg (He et al.2017b) 是无锚方法,它们将像素级回归应用于多向文本实例。 SegLink (Shi,Bai, and Belongie 2017) 对分段边界框进行回归并预测它们的链接,以处理长文本实例。 DeRPN (Xie et al. 2019b) 提出了一种维度分解区域提议网络来处理场景文本检测中的尺度问题。基于回归的方法通常享有简单的后处理算法(例如非极大值抑制)。但是,它们中的大多数仅限于表示不规则形状(例如弯曲形状)的准确边界框。
基于分割的方法通常结合像素级预测和后处理算法来获得边界框。 (Zhang et al. 2016) 通过语义分割和基于 MSER 的算法检测多向文本。在 (Xue, Lu, and Zhan 2018) 中使用文本边界来分割文本实例,Mask TextSpotter (Lyu et al. 2018a; Liao et al. 2019) 以基于 Mask R-CNN.PSENet (Wang et al. 2019a) 的实例分割方式检测任意形状的文本实例,通过使用不同尺度内核分割文本实例提出渐进式尺度扩展。 (Tian et al.2019) 中提出了像素嵌入来对分割结果中的像素进行聚类。PSENet (Wang et al. 2019a) 和 SAE (Tian et al. 2019) 提出了新的分割结果后处理算法,结果在较低的推理速度。相反,我们的方法专注于通过将二值化过程包含在训练期间来改善分割结果,而不会损失推理速度。
快速场景文本检测方法注重准确性和推理速度。 TextBoxes (Liao et al. 2017)、TextBoxes++ (Liao, Shi, and Bai 2018)、SegLink (Shi, Bai, and Belongie 2017) 和 RRD (Liao et al. 2018) 遵循以下检测架构实现了快速文本检测 SSD(刘等人,2016 年)。 EAST (Zhou et al. 2017) 提出应用 PVANet (Kim et al. 2016) 来提高其速度。 它们中的大多数不能处理不规则形状的文本实例,例如弯曲形状。 与之前的快速场景文本检测器相比,我们的方法不仅运行速度更快,而且可以检测任意形状的文本实例。
方法
我们提出的方法的架构如图 3 所示。首先,输入图像被输入到特征金字塔主干中。 其次,金字塔特征被上采样到相同的尺度并级联产生特征F。然后,特征F用于预测概率图(P)和阈值图(T)。 之后,由P和F计算出近似二值图 ( B ^ ) (\hat{B}) (B^)。在训练期间,对概率图、阈值图和近似二值图进行监督,其中概率图和近似二值图 地图共享相同的监督。 在推理期间,边界框可以很容易地从近似二值图或概率图中通过框公式模块获得。
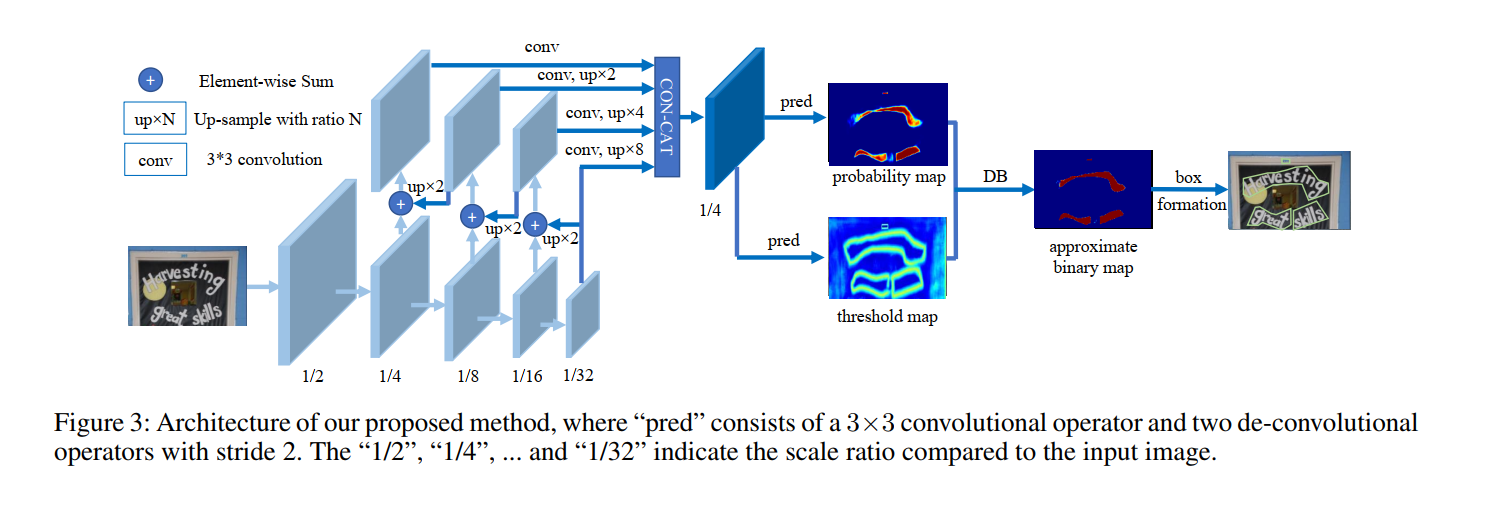
二值化
标准二值化 给定由分割网络生成的概率图 P ∈ R H × W P \in R^{ H \times W} P∈RH×W ,其中 H 和 W 表示图的高度和宽度,必须将其转换为二进制图 P ∈ R H × W P \in R^{ H \times W} P∈RH×W ,其中值为 1 的像素为 视为有效的文本区域。 通常,这个二值化过程可以描述如下:
B i , j = { 1 if P i , j > = t 0 otherwise (1) B_{i, j}=
\tag{1} Bi,j={10 if Pi,j>=t otherwise (1){10 if Pi,j>=t otherwise
其中 t 是预定义的阈值, (i; j) 表示地图中的坐标点。可微二值化 Eq.1 中描述的标准二值化是不可微的。 因此,它不能在训练期间与分割网络一起优化。 为了解决这个问题,我们建议使用近似阶跃函数执行二值化:
B ^ i , j = 1 1 + e − k ( P i , j − T i , j ) (2) \hat{B}_{i, j}=\frac{1}{1+e^{-k\left(P_{i, j}-T_{i, j}\right)}} \tag{2} B^i,j=1+e−k(Pi,j−Ti,j)1(2)
其中 ( B ^ ) (\hat{B}) (B^) 是近似二值映射; T 是从网络中学习到的自适应阈值图; k 表示放大因子。 k 根据经验设置为 50。 这种近似二值化函数的行为类似于标准二值化函数(见图 4),但可微分,因此可以在训练期间与分割网络一起优化。 具有自适应阈值的可微二值化不仅可以帮助区分文本区域与背景,还可以分离紧密连接的文本实例。 一些示例如图 7 所示。
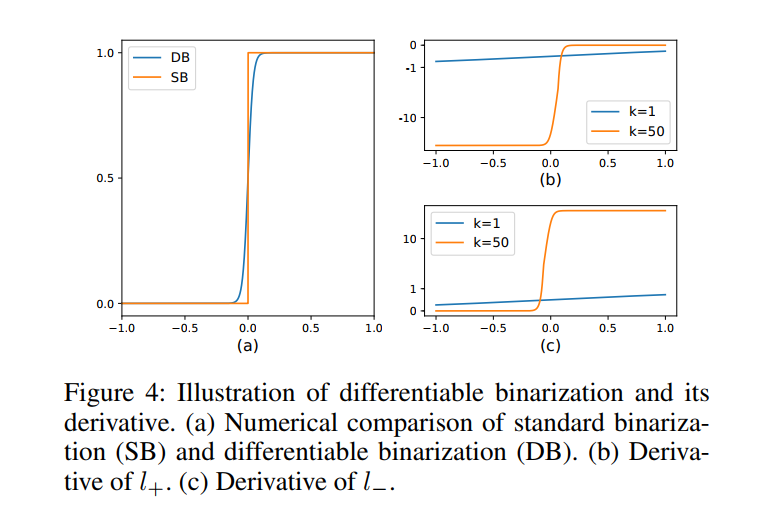
DB提高性能的原因可以通过梯度的反向传播来解释。 让我们以二元交叉熵损失为例。 定义 f ( x ) = 1 1 + e − k x f(x)=\frac{1}{1+e^{-k x}} f(x)=1+e−kx1作为我们的 DB 函数,其中 x = P i , j − T i , j x=P_{i,j}-T_{i,j} x=Pi,j−Ti,j 。 那么正标签的损失 l+ 和负标签的损失 l- 是:
l + = − log 1 1 + e − k x l − = − log ( 1 − 1 1 + e − k x ) (3)\tag{3} l+=−log1+e−kx1l−=−log(1−1+e−kx1)(3)l+=−log11+e−kxl−=−log(1−11+e−kx)
我们可以使用链式法则轻松计算损失的微分:
∂ l + ∂ x = − k f ( x ) e − k x ∂ l − ∂ x = k f ( x ) (4)\tag{4} ∂x∂l+∂x∂l−=−kf(x)e−kx=kf(x)(4)∂l+∂x∂l−∂x=−kf(x)e−kx=kf(x)
l + l_{+} l+ 和 l − l_{-} l− 的导数也如图4 所示。 我们可以从微分中看出 (1) 梯度被放大因子 k 放大; (2) 梯度的放大对于大多数错误预测的区域是显着的(对于 L + L_{+} L+,x < 0;对于 L − L_{-} L−,x > 0),从而促进优化并有助于产生更独特的预测。 此外,当 x = Pi;j - Ti;j 时,P 的梯度在前景和背景之间受到 T 的影响和重新缩放。自适应阈值
图 1 中的阈值图从外观上类似于(Xue, Lu, and Zhan 2018)中的文本边界图。 但是,阈值图的动机和用法与文本边界图不同。 有/无监督的阈值图在图 6 中可视化。即使没有对阈值图的监督,阈值图也会突出显示文本边界区域。 这表明边界状阈值图有利于最终结果。 因此,我们在阈值图上应用边界监督以获得更好的指导。 实验部分讨论了关于监督的消融研究。 对于用法,(Xue, Lu, and Zhan 2018)中的文本边界图用于分割文本实例,而我们的阈值图用作二值化的阈值。
可变形卷积
可变形卷积(Dai et al. 2017; Zhu et al. 2019)可以为模型提供一个灵活的感受野,这对于极端纵横比的文本实例尤其有利。 在 (Zhu et al. 2019) 之后,调制可变形卷积应用于 ResNet-18 或 ResNet-50 骨干网中的 conv3、conv4 和 conv5 阶段的所有 3 × 3 卷积层 (He et al. 2016a)。
标签生成
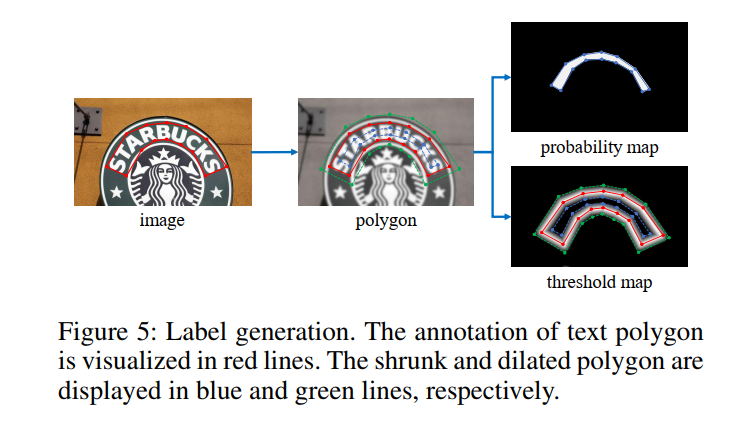
概率图的标签生成受到 PSENet 的启发(Wang et al. 2019a)。 给定一个文本图像,其文本区域的每个多边形都由一组段描述:
G = { S k } k = 1 n (5) G=\left\{S_{k}\right\}_{k=1}^{n} \tag{5} G={Sk}k=1n(5)
n 是顶点的数量,在不同的数据集中可能不同,例如 ICDAR 2015 数据集 (Karatzas et al. 2015) 为 4 个,CTW1500 数据集 (Liu et al. 2019a) 为 16 个。然后生成正区域 通过使用 Vatti 裁剪算法(Vati 1992)将多边形 G 缩小到 Gs。 收缩的偏移量 D 由原始多边形的周长 L 和面积 A 计算得出:
D = A ( 1 − r 2 ) L (6) D=\frac{A \left(1-r^{2} \right)}{L} \tag{6} D=LA(1−r2)(6)
其中 r 是收缩率,根据经验设置为 0.4。通过类似的过程,我们可以为阈值图生成标签。 首先,文本多边形 G 以与 G d G_{d} Gd 相同的偏移量 D 膨胀。 我们将 G s G_{s} Gs 和 G d G_{d} Gd 之间的间隙视为文本区域的边界,其中阈值图的标签可以通过计算到 G 中最近段的距离来生成。
优化
损失函数 L 可以表示为概率图 L s L_{s} Ls 的损失、二值图 L b L_{b} Lb 的损失和阈值图 L t L_{t} Lt 的损失的加权和:
L = L s + α × L b + β × L t (7) L=L_{s}+\alpha \times L_{b}+\beta \times L_{t}\tag{7} L=Ls+α×Lb+β×Lt(7)
其中 L s L_{s} Ls是概率图的损失, L b L_{b} Lb 是二值图的损失。 根据损失的数值,α和β分别设置为1.0和10。

我们对 L s L_{s} Ls 和 L b L_{b} Lb 应用二元交叉熵 (BCE) 损失。 为了克服正负数量的不平衡,在 BCE 损失中使用hard negative mining对困难负样本进行上采样。
L s = L b = ∑ i ∈ S l y i log x i + ( 1 − y i ) log ( 1 − x i ) (8) L_{s}=L_{b}=\sum_{i \in S_{l}} y_{i} \log x_{i}+\left(1-y_{i}\right) \log \left(1-x_{i}\right)\tag{8} Ls=Lb=i∈Sl∑yilogxi+(1−yi)log(1−xi)(8)S l S_{l} Sl 是正负比例为 1:3 的采样集。
L t L_{t} Lt 计算为膨胀文本多边形 G d G_{d} Gd内预测和标签之间的 L 1 L1 L1 距离之和:
L t = ∑ i ∈ R d ∣ y i ∗ − x i ∗ ∣ (9) L_{t}=\sum_{i \in R_{d}}\left|y_{i}^{*}-x_{i}^{*}\right| \tag{9} Lt=i∈Rd∑∣yi∗−xi∗∣(9)
其中 R d R_{d} Rd 是膨胀多边形 G d G_{d} Gd 内像素的一组索引; y ∗ y^{∗} y∗ 是阈值图的标签。在推理期间,我们可以使用概率图或近似二值图来生成文本边界框,产生几乎相同的结果。 为了提高效率,我们使用概率图,以便可以去除阈值分支。 框的形成过程包括三个步骤:(1)先用常数阈值(0.2)对概率图/近似二值图进行二值化,得到二值图; (2)从二值图中得到连通区域(缩小文本区域); (3) 使用 Vatticlipping 算法 (Vati 1992) 用偏移量 D ′ D^{\prime} D′ 对收缩区域进行扩张。 D ′ D^{\prime} D′ 计算为:
D ′ = A ′ × r ′ L ′ (10) D^{\prime}=\frac{A^{\prime} \times r^{\prime}}{L^{\prime}} \tag{10} D′=L′A′×r′(10)
其中 A ′ A^{\prime} A′是收缩多边形的面积; L ′ L^{\prime} L′ 是收缩多边形的周长; $ r^{\prime}$ 根据经验设置为 1.5。实验
数据集
SynthText(Gupta、Vedaldi 和 Zisserman 2016)是一个由 800k 图像组成的合成数据集。 这些图像是从 8k 背景图像合成的。 该数据集仅用于预训练我们的模型。
MLT-2017 数据集是一个多语言数据集。它包括代表 6 种不同文字的 9 种语言。该数据集中有 7,200 个训练图像、1,800 个验证图像和 9,000 个测试图像。我们在微调期间同时使用训练集和验证集。
ICDAR 2015 数据集 (Karatzas et al. 2015) 由 1000 张训练图像和 500 张测试图像组成,由 Google 眼镜以 720 × 1280 的分辨率捕获。文本实例在单词级别进行标记。
MSRA-TD500 数据集(Yao et al. 2012)是一个包含英文和中文的多语言数据集。有 300 个训练图像和 200 个测试图像。文本实例在文本行级别标记。按照之前的方法(Zhou et al. 2017; Lyu et al. 2018b; Long et al.2018),我们包含了来自 HUSTTR400 的额外 400 张训练图像(Yao、Bai 和 Liu 2014)。
CTW1500 数据集 CTW1500 (Liu et al. 2019a) 是一个专注于弯曲文本的数据集。它由 1000 个训练图像和 500 个测试图像组成。文本实例在文本行级别进行注释。
Total-Text 数据集 Total-Text(Chng 和 Chan 2017)是一个数据集,包括各种形状的文本,包括水平、多向和弯曲的。它们是 1255 个训练图像和 300 个测试图像。文本实例在单词级别进行标记。
实施细节
对于所有模型,我们首先使用 SynthText 数据集对它们进行 10 万次迭代的预训练。 然后,我们在相应的真实世界数据集上对模型进行了 1200 个 epoch 的微调。 训练批量大小设置为 16。我们遵循多学习率策略,其中当前迭代的学习率等于初始学习率乘以 ( 1 − i t e r max-iter ) power \left(1-\frac{i t e r}{\text { max-iter }}\right)^{\text {power }} (1− max-iter iter)power ,其中初始学习率设置为 0.007,幂为 0.9。 我们使用 0.0001 的权重衰减和 0.9 的动量。 max_iter 表示最大迭代次数,取决于最大epochs。
训练数据的数据增强包括:(1)角度范围为(-10°;10°)的随机旋转; (2) 随机裁剪; (3) 随机翻转。 所有处理后的图像都重新调整为 640×640 以提高训练效率。
在推理期间,我们保持测试图像的纵横比,并通过为每个数据集设置合适的高度来重新调整输入图像的大小。 推理速度是在批量大小为 1 的情况下测试的,在单线程中使用单个 1080ti GPU。推理时间成本包括模型前向时间成本和后处理时间成本。 后处理时间成本约为推理时间的 30%。
消融研究
我们对 MSRA-TD500 数据集和 CTW1500 数据集进行了消融研究,以展示我们提出的可微二值化、可变形卷积和不同主干的有效性。详细的实验结果见表1。
可微二值化 在 Tab.1 中,我们可以看到我们提出的 DB 在两个数据集上显着提高了 ResNet-18 和 ResNet-50 的性能。对于 ResNet-18 主干,DB 在 MSRA-TD500 数据集和 CTW1500 数据集上的 F-measure 分别实现了 3.7% 和 4.9% 的性能提升。对于 ResNet-50 主干,DB 带来了 3.2%(在 MSRA-TD500 数据集上)和 4.6%(在 CTW1500 数据集上)的改进。此外,由于可以在推理期间去除DB,因此速度与没有DB的速度相同。
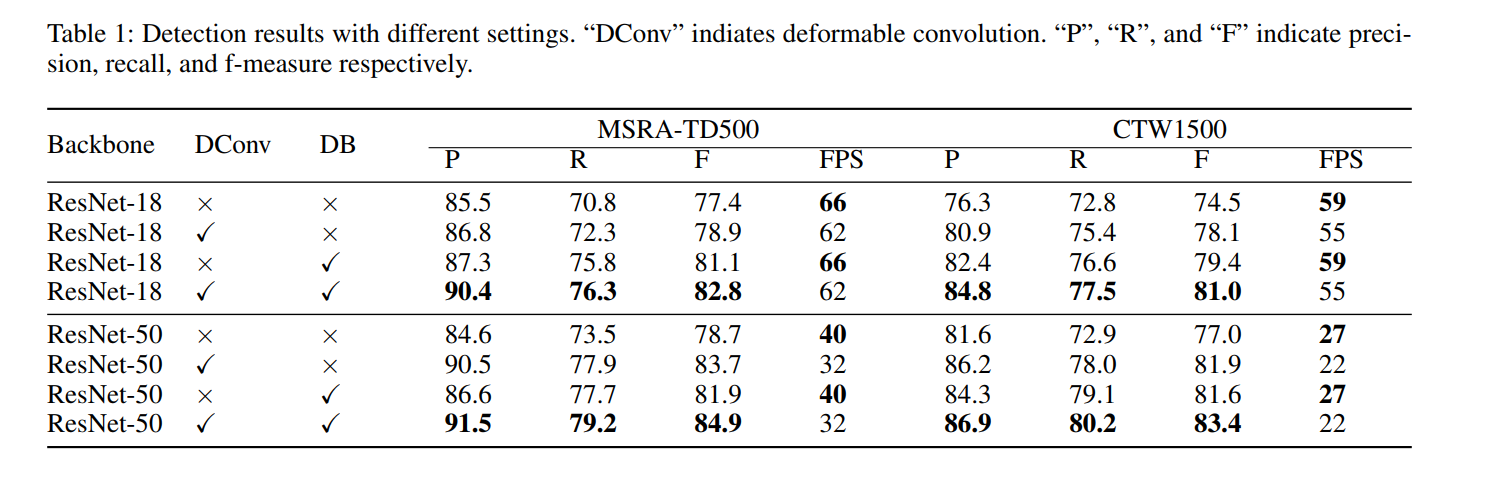
可变形卷积 如表 1 所示,可变形卷积还可以带来 1.5 - 5.0 的性能增益,因为它为骨干网提供了一个灵活的感受野,并且额外的时间成本很小。对于 MSRA-TD500 数据集,可变形卷积将 F-measure 提高了 1.5%(使用 ResNet-18)和 5.0%(使用 ResNet-50)。对于 CTW1500 数据集,可变形卷积实现了 3.6%(使用 ResNet-18)和 4.9%(使用 ResNet-50)的改进。
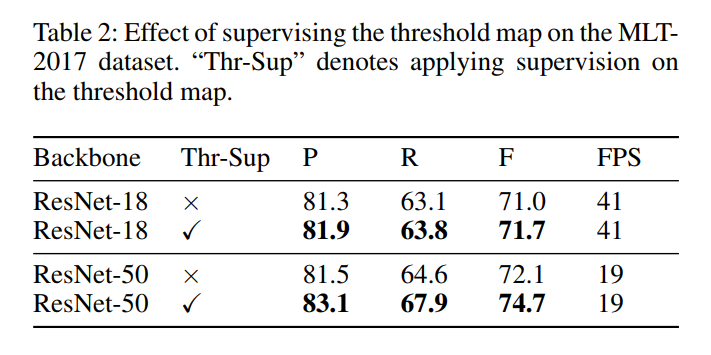
阈值图的监督 尽管有/无监督的阈值图在外观上相似,但监督可以带来性能增益。 如表 2 所示,监督在 MLT-2017 数据集上提高了 0.7%(ResNet-18)和 2.6%(ResNet-50)。
Backbone 所提出的具有 ResNet-50 主干的检测器实现了比 ResNet-18 更好的性能,但运行速度较慢。 具体来说,最好的 ResNet-50 模型比最好的 ResNet-18 模型高出 2.1%(在 MSRA-TD500 数据集上)和 2.4%(在 CTW1500 数据集上),时间成本大约是两倍。
与以往方法的比较

我们在五个标准基准上将我们提出的方法与以前的方法进行了比较,包括两个弯曲文本基准、一个多向文本基准和两个长文本行的多语言基准。 一些定性结果在图 7 中可视化。
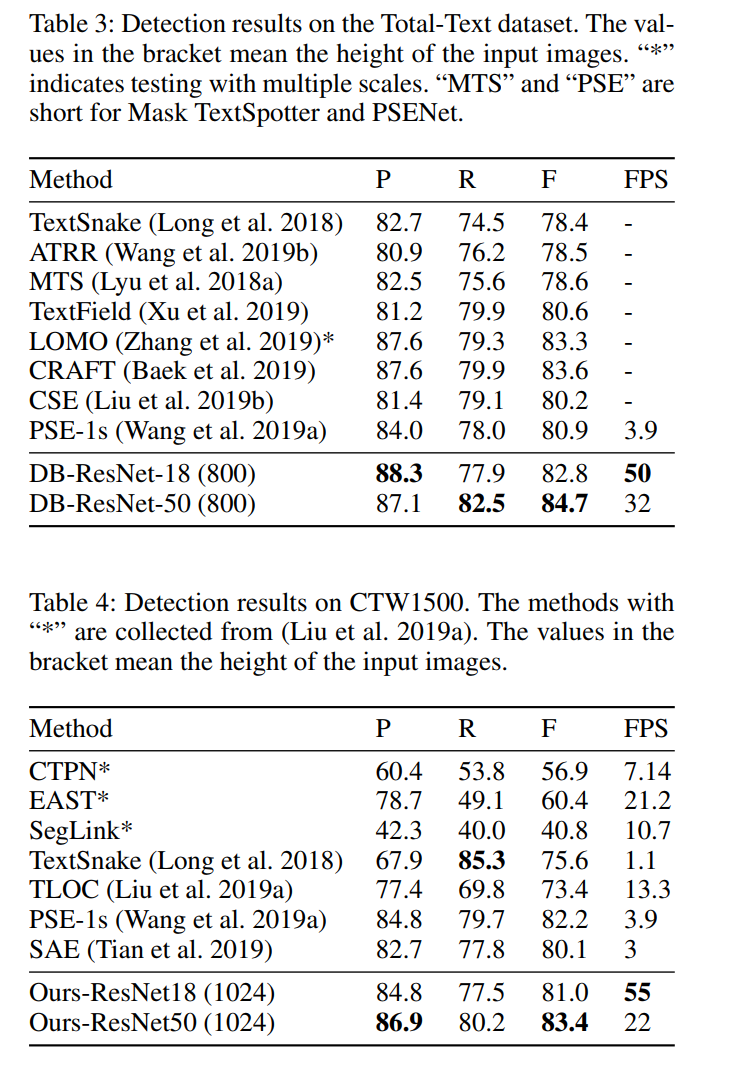
弯曲文本检测 我们在两个弯曲文本基准(Total-Text 和 CTW1500)上证明了我们方法的形状稳健性。 如 Tab.3 和 Tab.4 所示,我们的方法在准确度和速度上都达到了最先进的性能。 具体来说,“DB-ResNet-50”在 TotalText 和 CTW1500 数据集上比之前的最先进方法分别高出 1.1% 和 1.2%。 “DB-ResNet-50”的运行速度比以前所有的方法都快,并且可以通过使用 ResNet-18 主干进一步提高速度,性能下降很小。 与最近在 TotalText 上运行 3.9 FPS 的基于分割的检测器 (Wang et al. 2019a) 相比,“DB-ResNet-50 (800)”快 8.2 倍,“DBResNet-18 (800)”快 12.8 倍 。
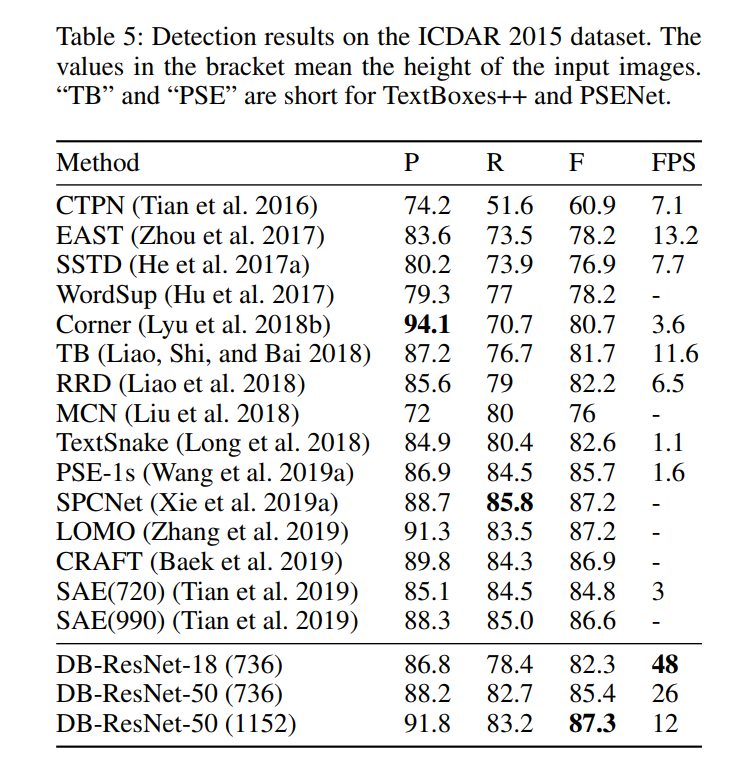
多向文本检测 ICDAR 2015 数据集是一个多向文本数据集,其中包含许多小而低分辨率的文本实例。 在 Tab.5 中,我们可以看到“DB-ResNet-50 (1152)”在准确度上达到了最先进的性能。 与之前最快的方法(Zhou et al.2017)相比,“DB-ResNet-50 (736)”在准确率上比它高出 7.2%,运行速度快了两倍。 对于“DBResNet-18 (736)”,当 ResNet-18 应用于主干时,速度可以达到 48 fps,f-measure 为 82.3。
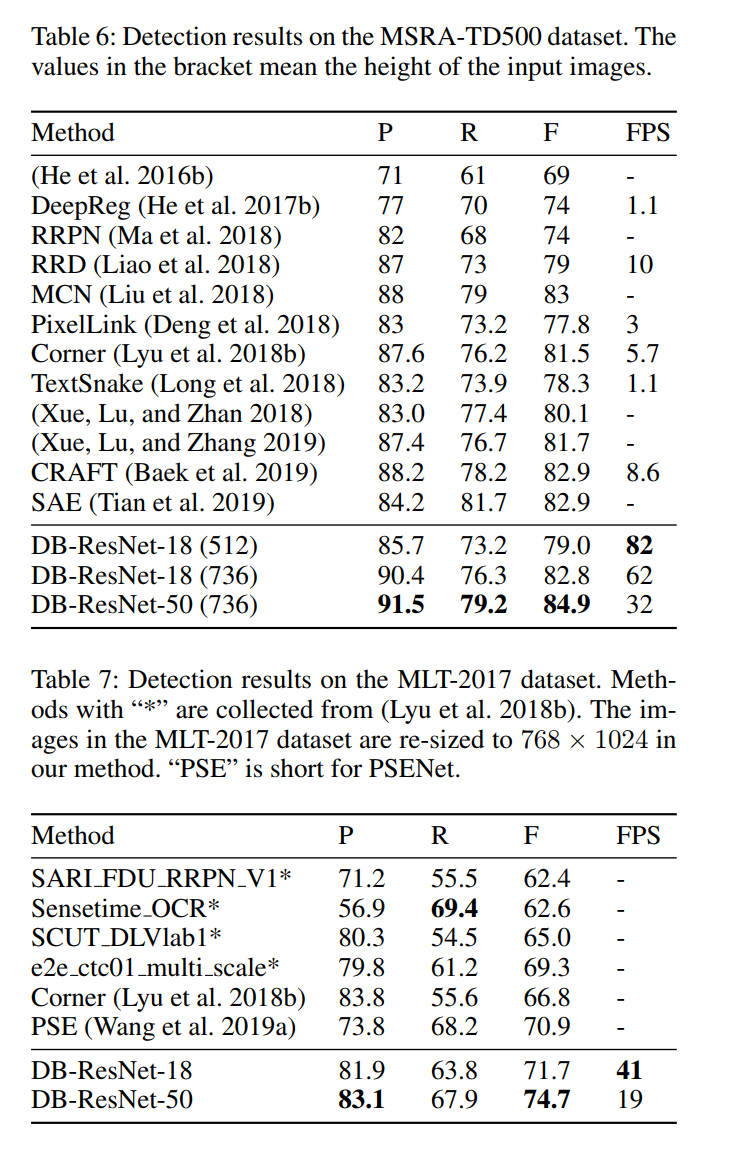
多语言文本检测 我们的方法在多语言文本检测上是稳健的。 如 Tab.6 和 Tab.7 所示,“DB-ResNet-50”在准确性和速度上都优于以前的方法。 在准确性方面,“DB-ResNet-50”在 MSRA-TD500 和 MLT-2017 数据集上分别超过了之前的最先进方法 1.9% 和 3.8%。 对于速度,“DB-ResNet-50”比之前在 MSRA-TD500 数据集上最快的方法(Liao et al. 2018)快 3.2 倍。 凭借轻量级主干,“DBResNet-18 (736)”与之前最先进的方法(Liu et al.2018)(82.8 vs 83.0)相比,实现了相当的准确度,并以 62 FPS 运行, 在 MSRA-TD500 上,比之前最快的方法(Liao 等人,2018 年)快 6.2 倍。 通过减小输入大小,速度可以进一步加速到 82 FPS(“ResNet-18 (512)”)。
局限性
我们的方法的一个限制是它不能处理“文本中的文本”的情况,这意味着一个文本实例在另一个文本实例中。 虽然缩小的文本区域有助于文本实例不在另一个文本实例的中心区域的情况,但当文本实例恰好位于另一个文本实例的中心区域时它会失败。 这是基于分段的场景文本检测器的常见限制。
结论
在本文中,我们提出了一种用于检测任意形状场景文本的新框架,其中包括在分割网络中提出的可微二值化过程 (DB)。 实验验证了我们的方法(ResNet-50 主干)在速度和准确性方面始终优于五个标准场景文本基准的最先进方法。 特别是,即使使用轻量级骨干网(ResNet-18),我们的方法也可以在所有测试数据集上以实时推理速度实现具有竞争力的性能。 将来,我们有兴趣扩展我们的端到端文本定位方法。
-
相关阅读:
第十章、python字符串操作与with语句及上下文管理器------字符串的匹配与分割、字符串连接
JVM的Class对象的存储位置和作用
ElasticSearch中关于Nasted嵌套查询的介绍:生动案例,通俗易懂,彻底吸收
食品饮料行业数智化采购管理系统规范供应商管理,完善企业协同体系
mac安装python虚拟环境
设计模式之工厂模式
【建议收藏】对线面试官:多线程硬核50问
嵌入式驱动初级-字符设备驱动基础
STC8H开发(十五): GPIO驱动Ci24R1无线模块
IDEA clion + vim =neovim
- 原文地址:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/125513523