-
447-哔哩哔哩面经1
1、对const和volatile的理解
const:
- const表示修饰的变量不可修改,如果修改,那编译器会报错。
- 如果对一个const修饰的变量取地址或引用之后再修改,那就会产生未定义行为,编译器不保证会得到想要的结果。
volatile:
- volatile有一点一定要注意,它和多线程一点关系都没有;
- 它的作用就是内存可见性,防止编译器对volatile修饰的变量做一些相关优化;
不对变量加volatile,编译器会对变量做一些优化:

而加了volatile修饰,生成的汇编是这样:

C++的volatile一般只会用在与硬件通信,平时我们编程几乎用不到。具体可以看:https://en.cppreference.com/w/cpp/language/cv
2、Linux生成可执行程序的过程
四个过程!
1、预处理;主要做了以下工作:
- 展开所有#define宏定义,进行文本替换;
- 删除程序中所有的注释;
- 处理所有的条件编译,#if、#ifdef、#elif等;
- 处理所有的#include指令,把这些头文件的内容都复制到引用的源文件中;
- 添加行号和文件名标识,方便编译器产生警告及调试信息;
- 保留所有的#pragma编译器指令,因为编译器会使用他们;
2、编译;把预处理后的文件进行一系列操作生成相应的汇编文件
- 词法分析:又称词法扫描,通过扫描器,利用有限状态机的算法将源码中的字符串分割成一系列记号,如加减乘除数字括号等。
- 语法分析:使用语法分析器对词法分析产生的记号运用上下文无关语法的手段进行语法分析,产生语法分析树。这期间如果表达式不合法(括号不匹配等),就会报错。
- 语义分析:语法分析检查表达式是否合法,检查表达式是否有意义,如浮点型整数赋值给指针,编译器就会报错。
- 中间语言生成:做一些语法树优化,如6+2=8。
- 目标代码生成及优化:将中间代码生成目标汇编代码。
3、汇编;
- 使用汇编器将汇编代码转成机器可以执行的指令,其实就是将汇编指令和机器指令按照对照表一一翻译。
4、链接;
- 上面处理的基本单元都是源文件,多个源文件经过上面的处理后变成多个目标文件;
- 链接就是将多个目标文件打包组装成一个整体的过程,这个整体就是可执行程序。
想更深入了解的朋友,建议看看《程序员的自我修养》,也可以看看我的总结篇:https://mp.weixin.qq.com/s/PaXLQnaCjGkQGIjnPnqRww
3、Linux程序是如何运行起来的
这块涉及到很多知识点:
- 什么是进程,进程是如何建立的?
- 什么是虚拟内存?为什么要有虚拟内存?
- 程序如何运行起来的?
1、通过fork系统调用创建一个新的进程;
2、通过execve系统调用执行指定的ELF文件,附带环境变量和参数;
3、检查ELF可执行文件的有效性,比如魔数(通过魔数可以确定文件格式)、Segment的数量等;
4、寻找动态链接的段,设置动态链接器路径;
5、根据ELF可执行文件的程序头表描述,对ELF文件进行映射,比如代码、数据、只读数据;
6、初始化ELF进程环境;
7、将系统调用的返回地址修改为ELF可执行文件的入口地址4、内存缺页的过程
涉及很多前置知识点:
- 虚拟内存管理
- 虚拟内存与物理内存的映射
- 页表和页面的概念
内存缺页就是要访问的页不在主存中,需要操作系统将页调入主存后再进行访问,此时会暂时停止指令的执行,产生一个页不存在的异常。
缺页中断的处理过程如下:
1、如果内存中有空闲的物理页面,则分配一物理页帧r,然后转第4步,否则转第2步;
2、选择某种页面置换算法,选择一个将被替换的物理页帧r,它所对应的逻辑页为q,如果该页在内存期间被修改过,则需把它写回到外存;
3、将q所对应的页表项进行修改,把驻留位置0;
4、将需要访问的页p装入到物理页面r中;
5、修改p所对应的页表项的内容,把驻留位置1,把物理页帧号置为x;
6、重新运行被中断的指令。5、左值和右值的概念
能取地址的就是左值,不能取地址的就是右值。
6、移动语义
官方定义:
- 移动语义主要是提供将昂贵的对象从内存中的一个地址移动到另外一个地址的能力,同时窃取源资源以便以最小的代价构建目标。
主要用途:
- 能够使用移动构造函数和移动赋值运算符,使得我们在使用临时对象时,减少不必要的拷贝操作。
7、模板使用的优缺点?
优点:
- 比较灵活,可重用;
- 通过编译期自动生成代码,大大减少了开发时间;
缺点:
- 调试起来比较困难;
- 一般情况下模板中函数的实现都会放在头文件中,会暴露出实现细节;
- 大量使用模板,会导致编译时间较长。
8、程序输出
for (char i = 0; i < 256; ++i) { printf("%d\n", i); }- 1
- 2
- 3
- 4
输出为:
0 1 2 … 127 -128 -127 … -1 0 1…无限循环!127 的二进制为 0111 1111(补码)
-128的二进制为 1000 0000(补码)原因:
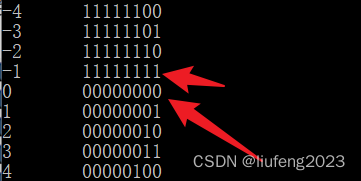
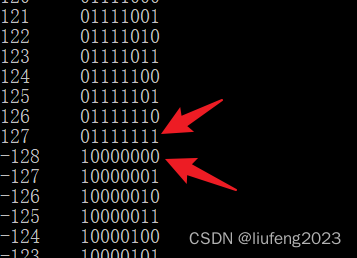
由上图的结果可以看到,ch在127之后,数值由127变成了-128,继续执行下去当ch为-1时又回到最初的 0 值。就像上文画的闭环一般,0->127,-128->0->127…下面我们从二进制的角度分析:
在计算机中,有符号数字都使用补码表示。
对于char类型的1字节8位数字,第一位是符号位,其余位是数值位。
2^7-1 = 127
- 127 的二进制为 0111 1111(补码)
- -128的二进制为 1000 0000(补码)
由于 127 + 1 后进位,使得高位溢出到符号位。
而符号位标志着数组的正负,则数值从原先的正数变为负数。
而 1000 0000(补码) 是-128的补码,则他表示有符号数 -128 。
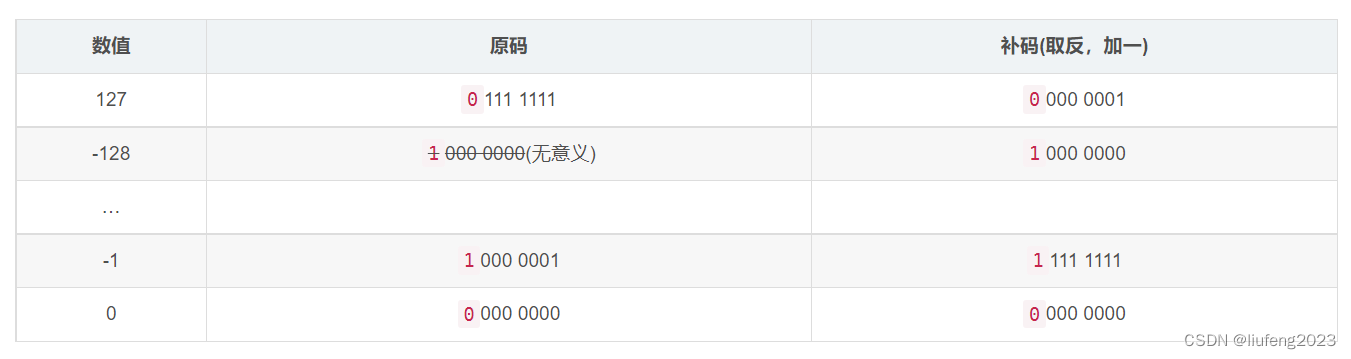
负数的原码与补码之间的关系是:
原码 -> 取反+1 => 补码。对于正数,不区分原码/反码/补码,都用自身原码表示,只有负数才进行区分。
对于有符号的数,我们在首位取一位作为符号位,表示数值的正负。
而对于0,我们就有两种表示方法:即
+0 ⇒ 0000 0000、-0 ⇒ 1000 0000,这显然是不合理的。+0与-0应该表示的同一个数,而且我们可以发现:1000 0000(原) 作为原码时,它的补码任然是1000 0000(补)(高位溢出,丢弃)- -127
1111 1111(原) 减一后(加负一)的二进制值也是1000 0000。而-127 - 1的值为-128。(负数用补码运算,1111 1111 +1000 0001 =》1000 0000)
则我们可以用 补码 1000 0000 表示 -128 。而且由于我们取消“负0”这个概念,就空出了一个二进制位组合可以表示其他数值(用于表示-128)。
由之前的分析可知,补码 1000 0000 的原码值可以表示 负0, 然而我们并不需要“负0”,因此对于 补码 1000 0000 我们并不研究其原码,它只有补码有意义,表示 -128 。因此,在127加一之后就变成了-128 。
-
相关阅读:
2022.07.26面试
chapter8 Dimensionality Reduction(降维)
elementUI 弹窗居中 并且tabs组件 tab-position=“left“时显示的样式优化
三分钟快速了解什么是MES系统
数据库 自动增长
数据结构与算法系列二之链表、哈希表及栈
【自定义列表头】vue el-table表格自定义列显示隐藏,多级表头自定义列显示隐藏,自由搭配版本和固定列版本【注释详细】
ESP32智能手表项目总目录
合并区间问题
javaEE7
- 原文地址:https://blog.csdn.net/Edward_LF/article/details/125563786