-
redis21道经典面试题,极限拉扯面试官
1.为什么使用redis
1、单线程 效率快
2、有丰富的数据类型
3、存储在硬盘上
4、支持持久化
5、高可用支持集群
6、存储的数据较大,单个key和value可以存储到1G
2.Redis 为什么快呢?
redis 的速度非常的快,单机的 redis 就可以支撑每秒 10 几万的并发,相对于 mysql 来说,性能是 mysql 的几十倍。速度快的原因主要有几点:
-
完全基于内存操作
-
C 语言实现,优化过的数据结构,基于几种基础的数据结构,redis 做了大量的优化,性能极高
-
使用单线程,无上下文的切换成本
-
基于非阻塞的 IO 多路复用机制
3.关于两个服务之间redis取不到值时:
1:key是否一致 2:是否连着同一个redis 3:查看两个服务的redis编码格式是否一致 4:是否过期
4.线程模型
严格来说, Redis Server是多线程的, 只是它的请求处理整个流程是单线程处理的。 这一点我们一定要清楚了解到,不要单纯地认为Redis Server是单线程的。
Redis的性能非常之高,每秒可以承受10W+的QPS,它如此优秀的性能主要取决于以下几个方面:
-
Redis大部分操作在内存完成
-
采用IO多路复用机制
-
非CPU密集型任务
-
单线程的优势
5.纯内存操作
Redis是一个内存数据库,它的数据都存储在内存中,这意味着我们读写数据都是在内存中完成,这个速度是非常快的。
Redis底层采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。
6.采用IO多路复用机制
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
7.非CPU密集型任务
采用单线程的缺点很明显,无法使用多核CPU。Redis作者提到,由于Redis的大部分操作并不是CPU密集型任务,而Redis的瓶颈在于内存和网络带宽。
在高并发请求下,Redis需要更多的内存和更高的网络带宽,否则瓶颈很容易出现在内存不够用和网络延迟等待的情况。
当然,如果你觉得单个Redis实例的性能不足以支撑业务,Redis作者推荐部署多个Redis节点,组成集群的方式来利用多核CPU的能力,而不是在单个实例上使用多线程来处理。
8.单线程的优点
基于以上特性,Redis采用单线程已足够达到非常高的性能,所以Redis没有采用多线程模型。
另外,单线程模型还带了以下好处:
-
避免多线程上下文切换导致的性能损耗
-
避免多线程访问共享资源加锁导致的性能损耗
所以Redis正是基于有以上这些优点,所以采用了单线程模型来完成请求处理的工作。
9.单线程的缺点
单线程处理最大的缺点就是,如果前一个请求发生耗时比较久的操作,那么整个Redis都会被阻塞,其他请求也无法进来,直到这个耗时久的操作处理完成并返回,其他请求才能被处理到。
我们平时遇到Redis响应变慢或长时间阻塞的问题,大部分都是因为Redis处理请求是单线程这个原因导致的。
所以,我们在使用Redis时,一定要避免非常耗时的操作,例如使用时间复杂度过高的方式获取数据、一次性获取过多的数据、大量key集中过期导致Redis淘汰key压力变大等等,这些场景都会阻塞住整个处理线程,直到它们处理完成,势必会影响业务的访问。
10.多线程优化
Redis Server是多线程的,除了请求处理流程是单线程处理之外,Redis内部还有其他工作线程在后台执行,它负责异步执行某些比较耗时的任务,例如AOF每秒刷盘、AOF文件重写都是在另一个线程中完成的。
在删除大key时,释放内存往往都比较耗时,所以Redis提供异步释放内存的方式,让这些耗时的操作放到另一个线程中异步去处理,从而不影响主线程的执行,提高性能。
到了Redis 6.0,Redis又引入了多线程来完成请求数据的协议解析,进一步提升性能。它主要是解决高并发场景下,单线程解析请求数据协议带来的压力。请求数据的协议解析由多线程完成之后,后面的请求处理阶段依旧还是单线程排队处理。
可见,Redis并不是保守地认为单线程有多好,也不是为了使用多线程而引入多线程。Redis作者很清楚单线程和多线程的使用场景,针对性地优化。
11.持久化方式
redis 有两种持久化的方式,AOF 和 RDB。

AOF
(append only file) 持久化,redis 每次执行一个命令时,都会把这个
将命令执行后的数据持久化到磁盘中(不包括读命令)
AOF优点:
AOF可以「更好地保护数据不丢失」,一般AOF会以每隔1秒,通过后台的一个线程去执行一次fsync操作,如果redis进程挂掉,最多丢失1秒的数据。
AOF缺点: 对于同一份数据源来说,一般情况下AOF文件比RDB数据快照大
RDB
把某个时间点 redis 内存中的数据以二进制的形式存储的一个.rdb为后缀的文件当中,也就是「周期性的备份redis中的整个数据」,这是redis默认的持久化方式,也就是我们说的快照(snapshot),是采用 fork 子进程的方式来写时同步的。
RDB的优点
它是将某一时间点redis内的所有数据保存下来,所以当我们做「大型的数据恢复时,RDB的恢复速度会很快」
RDB的缺点
举个例子假设我们定时5分钟备份一次,在10:00的时候 redis 备份了数据,但是如果在10:04的时候服务挂了,那么我们就会丢失在10:00到10:04的整个数据。
-
「有可能会产生长时间的数据丢失」。
-
可能会有长时间停顿:我们前面讲了,fork 子进程这个过程是和 redis 的数据量有很大关系的,如果「数据量很大,那么很有可能会使redis暂停几秒」。
12.淘汰策略
实际上redis定义了「8种内存淘汰策略」用来处理redis内存满的情况:
-
noeviction:默认策略,直接返回错误,不淘汰任何已经存在的redis键;
-
allkeys-lru:所有的键使用LRU(最近最少使用)算法进行淘汰;
-
volatile-lru:从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
-
allkeys-random:随机删除 redis 键;
-
volatile-random:随机删除有过期时间的 redis 键;
-
volatile-ttl:删除快过期的redis键;
-
volatile-lfu:根据LFU算法从有过期时间的键删除;
-
allkeys-lfu:根据LFU算法从所有键删除;
13.redis集群模式原理
1、主从模式(手动切换主从)
主从复制模式原理:
-
从数据库连接主数据库,发送的是SYNC的请求
-
主数据库接收到SYNC的请求之后,开始执行bgsave命令,并且生成RDB文件
-
主数据库 执行完bgsave命令,向从数据库去发送快照文件,在此期间主数据可以继续执行写操作
-
从数据接收到文件之后,摒弃旧的替换新的文件
-
主数据库向从数据库发送缓存中的写操作
-
从数据库对快照进行一个载入操作,同时接收主数据库发送过来的缓存写操作
-
出现重新连接的操作的时候,会有一个增量复制操作
-
不论什么情况下redis首先进行的是增量同步操作,如果失败了,那么就全量同步
主从模式的优点:支持主从复制,可以读写分离
最主要的还是为master分担的压力
主从模式的缺点:宕机的时候,如果主的数据没有同步到从数据库中去,那么就会造成数据的丢失
需要手动去切换主服务,费时费力 ,还可能造成一段时间不可以使用的情况
redis支持扩容是很难的
2、哨兵模式(自动选举主)
哨兵模式是一种特殊的模式,哨兵是一个独立的进程,可以独立运行。
哨兵模式的作用:
-
通过发送命令,可以监控运行状态,包括主从服务器
-
当主服务器宕机的时候,会自动去切换新的主服务器,通过发布订阅模式去通知其他的从服务器进行配置的更改,切换主机;可以采用 多哨兵模式去进行监管主服务器
故障切换的过程:
如果主服务器宕机了,监管它的哨兵监测不到消息,在这个时候不会进行failover,这种现象为主管下线。要让其他的哨兵一同去发送ping命令,如果全部都没有检测到,那么这个时候哨兵会重新发布推举,整个服务进行failover操作,此时为客观下线,推选出新的主服务器的时候,采用发布订阅模式去通知其他从服务器,更改配置,进行主机的切换。
哨兵模式的工作流程 :
-
每个以每一秒一次的去监管主服务器去给从服务器以及其他的哨兵去发送ping命令
-
如果最后一次有效回复的ping命令超过了down-after-milliseconds的值,那么实例就会认为此时主机发生了主观下线。
-
如果主服务器被认为 是主观下线,那么其他的哨兵都会以每秒一次的频率去确认这个主服务器是否真的宕机
-
如果全部哨兵监测到的是主观下线,那么就是客观下线
-
一般情况下,每个哨兵会以10秒的一次探测频率去监测主服务器、从服务器。
-
如主服务器被认为是客观下线,那么哨兵在推选的新的主服务器的时候会以每秒一次的频率去发送info命令
-
如果有哨兵不同意主服务器下线,那么是可以从客观下线状态中移除的。如果说主服务器突然活了,发送命令了,那么也是可以从主管下线中移除的。
哨兵模式的优点:
哨兵模式是基于主从模式的,所以主从有的哨兵都有。
主从需要手动去切换主服务器,而哨兵不需要
哨兵模式的缺点:
redis较难支持在线扩容
3、集群
redis的哨兵模式已经实现了高可用,读写分离,但是哨兵模式下每台服务器都存储相同的数据,浪费内存,所以在3.0以后加入了集群模式,实现了分布式
存储,就是每台redis节点上存储不同的内容
14.雪崩穿透解决
雪崩
什么是雪崩
缓存雪崩是指:由于缓存中的数据一下子全部都在同一时间过期了,所以发送过来的全部请求都去请求数据库,导致数据库难以承受而宕机。
解决方法:
-
可以保证 redis高可用,建集群;
-
设置不同的过期时间,防止全部在同一时间过期
15.缓存穿透的概念
缓存穿透指一个一定不存在的数据,由于缓存未命中这条数据,就会去查询数据库,数据库也没有这条数据,所以返回结果是
null。如果每次查询都走数据库,则缓存就失去了意义,就像穿透了缓存一样。
带来的风险
利用不存在的数据进行攻击,数据库压力增大,最终导致系统崩溃。
为什么会产生缓存穿透
-
业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
-
恶意攻击:专门访问数据库中没有的数据。
解决方案
-
对结果
null进行缓存,并加入短暂的过期时间。 -
使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。 -
-
前端进行请求检测。把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉,不让它们访问后端缓存和数据库。
说说Redis 的缓存击穿
悟空拧螺丝 2021-07-22
说说缓存击穿?
缓存击穿的概念
某个 key 设置了过期时间,但在正好失效的时候,有大量请求进来了,导致请求都到数据库查询了。就像把一面墙击穿了一个洞。
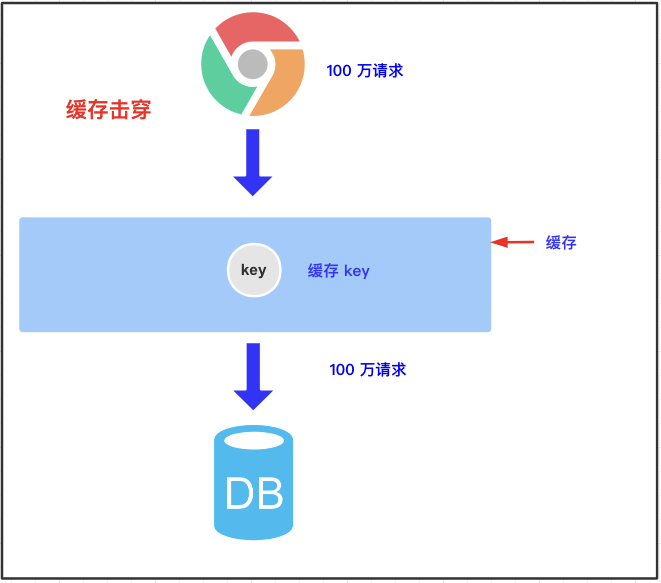
解决方案
不同场景下的解决方式可如下:
-
若缓存的数据是基本不会发生更新的,尝试将该热点数据设置为永不过期。
-
若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下,则可以采用基于Redis、Zookeeper 等分布式中间件的分布式互斥锁,或者本地互斥锁以保证仅少量的请求能请求数据库并重新构建缓存,其余线程则在锁释放后能访问到新缓存。
-
若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到对应的缓存。
16.redis分布式锁底层原理
redis 为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对 redis 的连接并不存在竞争关系 redis 中可以使用 SETNX 命令实现分布式锁。
当且仅当 key 不存在,将 key 的值设为 value。若给定的 key 已经存在,则 SETNX 不做任何动作 SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
返回值:设置成功,返回 1 。设置失败,返回 0 。

使用 SETNX 完成同步锁的流程及事项如下:
-
使用 SETNX 命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功;
-
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该 key 设置一个“合理”的过期时间;
-
释放锁,使用DEL命令将锁数据删除;
17.数据库和redis双写不一致解决
-
先更新数据库,在更新缓存 (造成一个脏读现象)
-
先更新数据库,在删除缓存
-
先增加数据库,在更新缓存(借助了一个
-
1mq去保证一个缓存的更新)
18.redis跳跃表实现

-
跳跃表是有序集合zset的底层实现之一。
-
跳跃表就是在链表的基础上,增加多级索引提升查找效率。
20.redis是单线程吗?
redis是单线程,但是在6.0之后出现了多线程,redis单线程是因为他可以避免上下文的切换,效率高,redis是基于内存的,它的瓶颈并不是CPU而是内存和网络,如果有网络的延迟的话,会读取不到数据,所以说采用多线程的形式,用来避免这种情况的发生
21.Redis 分布式锁原理
Redis 分布式锁,可以参考这篇:《》
Redis 的常用的分布式锁方案:使用 Lua 脚本进行获取锁、比较锁、删除锁的原子操作。
原理如下:

我们先来看一下这段 Redis 专属脚本:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 endCopy to clipboardErrorCopied复制复制失败复制成功先获取 KEYS[1] 的 value,判断 KEYS[1] 的 value 是否和 ARGV[1] 的值相等,如果相等,则删除 KEYS[1]。
那么这段脚本怎么在 Java 项目中执行呢?
分两步:先定义脚本;用 redisTemplate.execute 方法执行脚本。
// 脚本解锁 String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end"; redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);Copy to clipboardErrorCopied复制复制失败复制成功上面的代码中,KEYS[1] 对应
“lock”,ARGV[1] 对应“uuid”,含义就是如果 lock 的 value 等于 uuid 则删除 lock。而这段 Redis 脚本是由 Redis 内嵌的 Lua 环境执行的,所以又称作 Lua 脚本。
[性能方面]
Redis 分布式锁,需要自己不断去尝试获取锁,比较消耗性能。
Zookeeper 分布式锁,获取不到锁,注册个监听器即可,不需要不断主动尝试获取锁,性能开销较
小。
[风险]
Redis 获取锁的那个客户端宕机了,那么只能等待超时时间之后才能释放锁;而 Zookeeper 的话,因为创建的是临时 znode,只要客户端挂了,znode 就没了,此时就自动释放锁。
[易用度]
Zookeeper 创建的是临时顺序节点,所以在出现下面两种情况时,都会自动释放锁:
-
任务完成后,Client会自动释放锁。
-
任务没完成,Client崩溃了,自动释放锁。
Redis 是通过 Lua 脚本中的 del 命令解锁。
每天一道面试题-悟空聊架构 15/365
悟空拧螺丝 2021-07-27
简单说下缓存和数据库的数据不一致
不一致的情况:
-
缓存中有数据,那么,缓存的数据值需要和数据库中的值不相同。
-
缓存中本身没有数据,数据库中的值不是最新值。
操作缓存的模式:
根据是否接收写请求,分为读写缓存和只读缓存。
有哪些与 Redis 交互的操作?
面试者小空听到这题后,窃喜,这题简单,不假思索地回答:键值对 的读和写。
面试官面无表情的说道:还有吗?
小空支支吾吾的没有答上来。
面试官继续说:和 Redis 实例交互的对象分别有四种:客户端、磁盘、主从节点、切片集群实例。
这些对象和 Redis 交互时,有不同的操作:
客户端对象会有网络 IO交互、键值对 增删改查 操作、数据库操作。磁盘对象会有生成 RDB 快照、记录 AOF 日志、AOF 日志重写操作。主从节点对象会有主库生成、传输 RDB 文件、从库接受 RDB 文件、清空数据库、加载 RDB 文件操作。。切片集群实例对象会有向其他实例传输哈希槽信息、数据迁移操作。部分内容是借用别的
-
-
相关阅读:
【CGSize Objecive-C语言】
如何使用 WPF 应用程序连接 FastReport报表
微信小程序接入lottie动画
[附源码]java毕业设计校园共享单车系统
Google Earth Engine(GEE)扩展——制作的GEE app的误区
【职场成长】一篇文章,讲清复盘!
<stack和queue>——《C++初阶》
java毕业设计城镇保障性住房管理系统mybatis+源码+调试部署+系统+数据库+lw
ZYNQ从vitis生成linux系统编译启动文件
支持代理直连Oracle数据库,JumpServer堡垒机v2.24.0发布
- 原文地址:https://blog.csdn.net/Fristm/article/details/125562122