-
量化计算调研
1.Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
1.1手段
Prunes the network:只保留一些重要的连接;
Quantize the weights:通过权值量化来共享一些weights;
Huffman coding:通过霍夫曼编码进一步压缩;
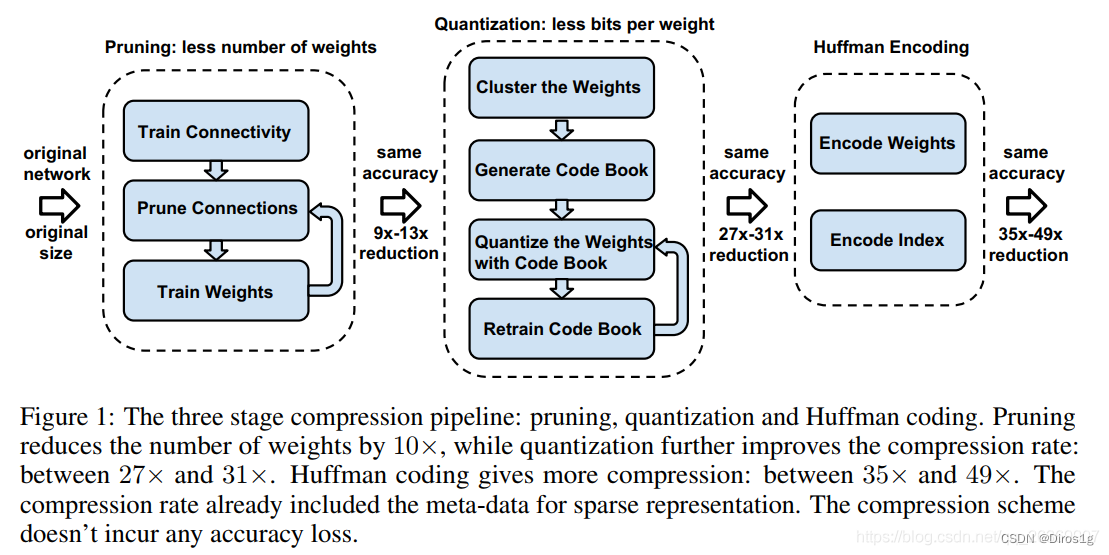
1.1.1剪枝
1.从正常训练出的网络中学习连接
2.修剪权重小的连接,小于阈值的都被删掉;
3 重新训练网络,其参数从剩余的稀疏连接中获取;1.1.2量化和权重共享
量化

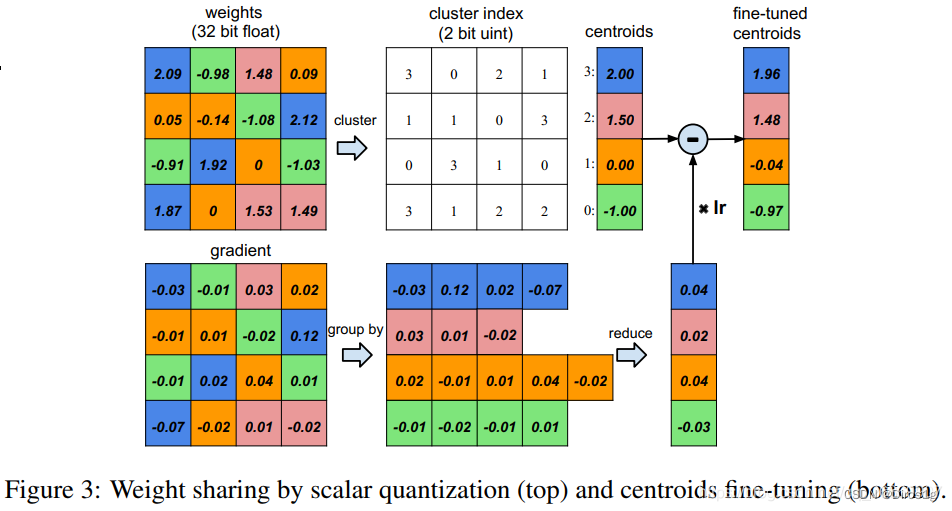
权重共享
用了非常简单的 K-means,对每一层都做一个weight的聚类,属于同一个 cluster 的就共享同一个权值大小。注意的一点:跨层的weight不进行共享权值;
1.1.3哈夫曼编码
哈夫曼编码首先会使用字符的频率创建一棵树,然后通过这个树的结构为每个字符生成一个特定的编码,出现频率高的字符使用较短的编码,出现频率低的则使用较长的编码,这样就会使编码之后的字符串平均长度降低,从而达到数据无损压缩的目的。
1.2效果
Pruning:把连接数减少到原来的 1/13~1/9;
Quantization:每一个连接从原来的 32bits 减少到 5bits;最终效果:
- 把AlextNet压缩了35倍,从 240MB,减小到 6.9MB;
- 把VGG-16压缩了49北,从 552MB 减小到 11.3MB;
- 计算速度是原来的3~4倍,能源消耗是原来的3~7倍;
1.3实验要求
1.训练的权重保存要求是完整的,不能是model.state_dict(),但我们目前大多数的权重文件都是参数状态而不是完整的模型
2.要求有完整的网络结构
3.要有足够的训练数据参考:1.【深度神经网络压缩】Deep Compression
2.深度压缩:采用修剪,量子化训练和霍夫曼编码来压缩深度神经网络
3.Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
4.pytorch官方文档
5.哈夫曼编码的理解(Huffman Coding)2.torch官方自带的量化计算
https://pytorch.apachecn.org/#/
https://pytorch.org/docs/stable/quantization.html2.0数据类型量化Quantized Tensor
可以存储 int8/uint8/int32 类型的数据,并携带有 scale、zero_point 这些参数
>>> x = torch.rand(2,3, dtype=torch.float32) >>> x tensor([[0.6839, 0.4741, 0.7451], [0.9301, 0.1742, 0.6835]]) >>> xq = torch.quantize_per_tensor(x, scale = 0.5, zero_point = 8, dtype=torch.quint8) tensor([[0.5000, 0.5000, 0.5000], [1.0000, 0.0000, 0.5000]], size=(2, 3), dtype=torch.quint8, quantization_scheme=torch.per_tensor_affine, scale=0.5, zero_point=8) >>> xq.int_repr() tensor([[ 9, 9, 9],- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.1两种量化方式
2.2Post Training Static Quantization,模型训练完毕后的静态量化torch.quantize_per_tensor
scale (标度)和 zero_point(零点位置)需要自定义。量化后的模型,不能训练(不能反向传播),也不能推理,需要解量化后,才能进行运算
2.3. Post Training Dynamic Quantization,模型训练完毕后的动态量化 : torch.quantization.quantize_dynamic
系统自动选择最合适的scale (标度)和 zero_point(零点位置),不需要自定义。量化后的模型,可以推理运算,但不能训练(不能反向传播)
-
相关阅读:
Android App ~ LiveData
无人机基础知识:多旋翼无人机系统基本组成
Ascend C 自定义算子 Kernel Launch调用入门
数据可视化分析之新技能——魔数图
Roson的Qt之旅#103 QML之标签导航控件TabBar
2022.11.8每日刷题打卡
直播带货用什么成交话术可以提高销量
ARM、x86 劲敌再度突袭:基于RISC-V 的首台笔记本将于今年面世
Linux 环境删除Conda
Anaconda如何创建一个环境
- 原文地址:https://blog.csdn.net/qq_41950533/article/details/125409366