-
【NLP】多语言预训练模型(mBERT和XLM)
融合多语言的预训练模型将不同语言符号统一表示在相同的语义向量空间内,从而达到跨语言处理的目的。
多语言BERT (Multilingual BERT, mBERT)
它能够将多种语言表示在相同的语义空间中。
通过HuggingFace提供的transformers库:
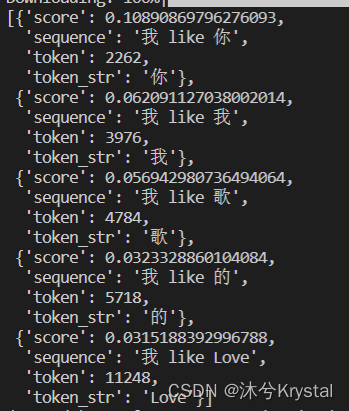
使用区分大小写的多语言BERT-base模型(bert-base-multilingual-cased),任务为掩码填充,即将输入的[MASK]填充为具体的标记。from pprint import pprint from transformers import pipeline unmasker = pipeline('fill-mask', model='bert-base-multilingual-cased') output = unmasker('我like[MASK]') pprint(output)- 1
- 2
- 3
- 4
- 5
语言自身存在混合使用,共享子词等特点:
- 混合使用:在一种语言的文本中,经常混有其他语言,尤其是一些同语族语言,甚至共享了一些词汇;即使是不同语族的语言,在使用时也经常会有意无意地直接使用其他语言的词汇(Code-switch)
- 共享子词:一些同族的语言,虽然使用的词汇有一些差异,但是词根有可能是一样的,因此经过子词切分后,就产生了大量的共享子词。这些共享的词汇或者子词作为桥梁,打通了不用语言之间的壁垒,从而将多种语言都表示在相同的语义空间内。
跨语言预训练语言模型(Cross-lingual Language Model Pretraining, XLM)
XLM采用基于双语句对的 翻译语言模型 (Translation Language Modeling, TLM) 预训练目标,将互为翻译的句子拼接起来,然后在两种语言中随机遮盖若干子词,并通过模型预测。(当一种语言对预测提供的信息不足时,另一种语言可以提供额外的补充信息,从而实现跨语言的目标。
XLM-R(XLM-RoBERTa)模型结构与RoBERTa一致,但不再依赖双语平行语料库。Huggingface Transformers库
我们可以在模型中心[点击进入]搜索符合任务需求的模型:

-
相关阅读:
TestNG如何编排测试用例,第3种方式最实用
python 通过open api 接口 连续问答gpt
创建型设计模式之建造者模式
注册商标流程,商标注册需要材料
09—DOM和BOM
一、docker的安装部署 - docker常用命令 - 底层隔离机制
【Qt】Qt定时器类QTimer
Java 基于SpringBoot的某家乡美食系统
网络协议--TCP的交互数据流
Allegro如何导出带有钻孔数据的dxf文件?
- 原文地址:https://blog.csdn.net/GW_Krystal/article/details/125554805