-
小迈科技 X Hologres:高可用的百亿级广告实时数仓建设
通过本文,我们将会介绍小迈科技如何通过Hologres搭建高可用的实时数仓。
一、业务介绍
小迈科技成立于 2015 年 1 月,是一家致力以数字化领先为优势,实现业务高质量自增长的移动互联网科技公司。始终坚持以用户价值为中心,以数据为驱动,为用户开发丰富的工具应用 、休闲游戏 、益智 、运动等系列的移动应用 。以成为全球领先开发者增长服务平台为愿景及使命,小迈希望通过标准化的产品和服务赋能,为开发者提供全链路解决方案,以技术+服务全方位保驾护航,助燃产品持续增长,帮助工具和休闲游戏的开发者提升产品的成功率。
小迈科技累计开发 400 余款产品,累计用户下载安装量破七亿 ,日活500-1000w,数据量每天 100 亿+。围绕高质量APP、用户增长和商业化变现,公司通过大数据技术相继搭建了商业化变现、智能推广、财务管理等10+应用系统。但用户量指数级增长,业务团队对数据实时化、精细化的要求提升,大数据系统开始备受挑战,如何更好的通过数仓建设为业务增长赋能成为重要突破点。
二、小迈数仓发展历程:从神策到流批一体实时数仓
为了满足业务团队的数据需求,小迈大数据技术团队从业务发展早期就开始建设数仓系统,从传统的神策阶段过渡到离线数仓,再发展到如今稳定的流批一体实时数仓共经历了3个阶段,从业务和技术的挑战中,不断对数仓系统进行迭代优化,从而支撑业务快速增长。下面将会进一步介绍小迈的大数据平台发展历程:
1、神策阶段
在最原始的阶段,业务系统基于神策实现。APP数据直接接入神策,初期只能看到APP内的行为数据, 以及广告数据,分析能力有限,不够灵活,无法自定义处理,不能和第三方数据进行整合分析,无法满足业务进一步要求。但因为业务还是起步阶段,数据平台的建设以满足现有业务需求为主,如果业务有特殊需求,再单独搭建对应的分析系统。
2、离线数仓(引入MaxCompute)
随着公司业务的不断发展,服务的用户越来越多,数据量指数级增长,对应的业务系统越来越多,每个系统之前也是割裂的,并且系统稳定性开始面临巨大挑战。基于神策的局限性,业务开始引入阿里云的MaxCompute、DataWorks和某分布式数据库(以下简称某DB)搭建离线数仓。业务的主要流程:
- 通过JDBC的方式拉去神策罗盘服务器,并通过DataWorks将数据离线同步至MaxCompute;
- 在MaxCompute中通过数仓四层建模(ODS、DWD、DWS、ADS),结果数据通过DataWorks离线同步至某DB;
- 在某DB中对接业务系统的各种分析需求。
离线数仓的引入基本满足了整个公司各个角色的分析决策,但随着业务的不断发展,会出现以下问题:
- 系统间通过神策系统以JDBC的方式拉取数据,过度依赖第三方神策,过于耦合,神策出问题的时候,整个计算流程无法继续,无法满足业务的敏捷分析需求。神策恢复之后,手动参与重新跑数据,浪费了许多人力。
- 数据统计完之后,数据入库慢,大大影响了整个链路的跑数时间,而业务对数据计算的实时性要求越来越高,现阶段无法支撑。
- 数据量呈现指数级别的增长,分析维度越来越多,结果数据基本达到了明细数据级别,现有的数据查询引擎某DB不足以支撑这么大数据的多维度分析,面临最大的挑战就是对百亿级规模的行为数据做低延迟、高QPS的查询分析。
- 为了解决查询引擎不足以支撑大数据量查询的问题,因此数据做了很多的前置计算,造成计算冗余,成本上升。
- 同时系统越来越多,导致运维成本、开发成本也随之线性增长,导致无法快速满足业务的各种诉求。
由于上面阐述的痛点,导致频繁出现的现象就是数据产出变慢,经常卡死,严重影响业务决策,经常被业务部门投诉,影响极其不好。基于此,技术部门迫切需要找到解决方案。
3、流批一体实时数仓(引入Hologres+Flink)
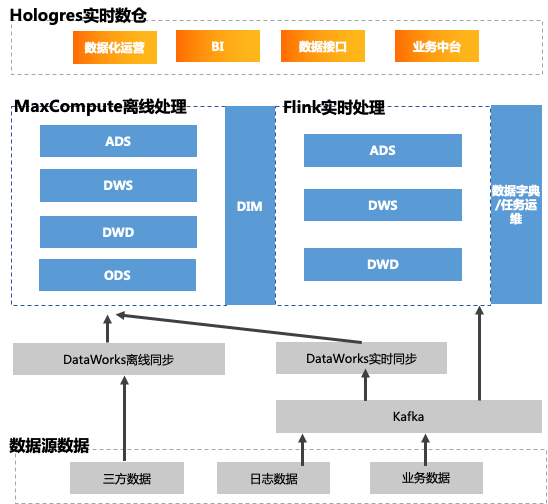
为了更好的解决业务诉求,第三阶段在原有基础上引入了阿里云的Hologres和Flink,并由Hologres替换某DB,搭建了流批一体的实时数仓。主要数据链路如下:
1、日志数据和业务数据Kafka通过DataWorks实时同步写入MaxCompute,实时落地ODS层;对于数据时效性要求较要的业务,直接写入Flink,Flink里面进行实时ETL处理,然后写入Hologres。
2、三方数据则是通过DataWorks离线同步至MaxCompute,在MaxCompute中进行数仓分层(ODS、DWD、DWS、ADS)建设,并将处理好的数据直接写入Hologres。
3、由Hologres存储实时和离线数据,并直接对接上层应用,承载业务系统的多种查询要求,实现流批一体的实时数仓。
通过第三阶段Hologres+Flink+MaxCompute的流批一体实时数仓建设,已经成功支撑小迈科技的众多业务,包括数据化运营,BI,数据接口,业务中台等。新架构带来的好处有:
- 数据结构化更清晰:对于不同层级的数据,它们的作用域不相同,每一个数据分层都有其作用域,这样业务在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:提供给业务使用的是一张业务表,但是这张业务表可能来源很多张表。如果有一张来源表出问题了,我们可以快速准确的定位到问题,并清楚每张表的作用范围。
- 减少重复开发:数据分层规范化,开发一些通用的中间层数据,能够减少重复计算,提高单张业务表的使用率。
- 简化复杂的问题:把一个复杂的业务分成多个步骤实现,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。有点类似Spark RDD的容错机制。
- 减少业务的影响:业务可能会经常变化,这样做就不必改一次业务就需要重新接入数据。
- 数据更加实时,业务决策更加迅速。
- 数据与第三方进行解耦,稳健性更强。
三、为什么选择Hologres?
选择Hologres是我们从多个方面调研以及测试验证的结论。下面我们将结合业务从技术和使用场景两个方面讲述选择Hologres的原因。
1、支持高性能写入和极速复杂查询
最开始我们分别基于某DB和Hologres进行了性能验证,核心是针对查询 、写入进行验证, 因为离线数仓阶段,数据库最大的瓶颈就是查询性能和写入性能。
- 查询性能: 基于目前实际的业务场景,包括简单及复杂 SQL进行查询性能验证,前期未做优化表现差不多,后面对Hologres的表设计和底层优化,我们验证出Hologres基本能有4倍左右的提升,后面也会跟阿里的同事一起做更多性能调优工作。
- 写入性能:之前在某DB 的环境上,MaxCompute写入某DB的时间非常长(1 亿数据一个小时左右),特别是查询业务上来后, 写入性能有几倍的降速 ,甚至会宕机。而写入MaxCompute数据至Hologres的性能表现非常强悍, 1个亿的数据导入10多秒左右即可完成。
2、满足多个分析场景
结合MaxCompute+Hologres+Flink搭建的流批一体实时数仓,使得我们的系统应用场景更加丰富,主要包括:
- 实时数仓: 由于Hologres 与 Flink 集成性好,通过实时的采集数据,Flink实时计算,直接将数据写到入 Hologres 中,就能实时构建实时大屏 、实时监控预警 、实时推荐 、实时训练等应用,快速响应业务需求。
- MaxCompute加速查询:Hologres 可以直接通过外表的方式,对 MaxCompute 的数据进行查询,如果需要更高的性能,则可以将数据导入到 Hologres 中更高性能的查询处理。如果是前一种方式,则可以在数据不输出的情况下,对离线数据进行查询分析。
- 自适应广告分析场景:Hologres有很多丰富的分析函数,比如留存分析函数和漏斗分析函数,这对广告业务的相关场景非常适用,无需我们二次开发,直接就能使用。
综上所述,无论从性能支撑还是使用场景都非常符合我们公司的业务需求。
四、百亿级用户行为分析最佳实践
用户行为是指用户在产品上产生的行为,通过对用户行为的分析,为提供下一步运营运策略提供辅助决策,同时也为产品迭代和发展提供方向。用户行为分析在互联网公司是非常普遍的一种场景,但大多数业务其核心痛点就是用户数据量大,计算逻辑复杂,导致计算性能不够好,往往不能及时拿到计算结果,从而影响下一步决策。
小迈在广告人群数据分析这个场景上,数据量约有上百亿,并且有很多的数亿行大表关联查询场景,之前的系统计算比较吃力,经常受到业务质疑。在现在的系统上,我们通过对Hologres中表的索引设计和性能调优,已经能达到非常明显的性能效果,下面我们具体介绍如何实现。
用户行为分析的流程如下:
1、MaxCompute中存放收入表income_dt_test,小时周期调度至Hologres结果表holo_ad_income_dt_test
2、Hologres存储用户行为表holo_dws_usr_label_df,通过Maxcompute周期性调度写入。
4、在Hologres中对两张表做关联Join计算,进行人群分析,示例分析SQL如下:

结合业务场景对表和SQL做了如下优化操作:
1.因为用户收入表和用户行为表需要做关联查询,因此设置分布字段distribution_key,保证相同的记录会被分配到同一个shard上,尽最大可能减少shuffle,尽量Local Join,所以设置以下分布键,大大提高了关联查询的速度,
- CALL set_table_property('holo_dws_usr_label_df', 'distribution_key', 'product_id,device_id');
- CALL set_table_property('holo_ad_income_dt_test', 'distribution_key', 'product_id,device_id');
2.因为报表筛选经常使用product_id、ad_id、position_id 三个字段,而bitmap_columns的使用场景就是等值查询,所以把这三个字段设置为bitmap_columns
CALLSET_TABLE_PROPERTY('public.holo_ad_income_dt_test','bitmap_columns','"product_id:on","ad_id:on","position_id:on"');3.粗略估算每天的增量数据在1亿左右,因此设置为分区表,提高查询速度,数据量较小的时候不太建议设置分区,否则会影响查询性能。
4.在用户数去重的时候,需要用到大量count(distinct a.device_id),但是会消耗很多的资源,因此我们改用APPROX_COUNT_DISTINCT (a.device_id) 方式,性能提升很多,但是会丢失一定的精度,通过参数
set hg_experimental_approx_count_distinct_precision=20调节精度。
通过对表结构和SQL的优化,我们的广告人群数据分析能够实现秒级响应,大大提升了计算效率,也能快速响应业务需求。
五、Hologres读写分离高可用实现
1、优化背景:读写不分离相互影响
随着迁移到Hologres的业务越来越多,写入任务的频率越来越高,在高峰期实例开始出现查询异常和写入任务报错的情况。具体原因主要有:
- 每天上午十点左右是离线(T+1)任务写入的高峰期,在这个时间段大量报表统计任务聚集,对Hologres写入操作占用资源很多。
- 其中部分写入任务的数据量特别大,天增量的结果数据达到了几亿条,写入时间长,持续占用资源。而又有部分结果表字段数太多,达到了一千多个,消耗资源较多。
- 写入的同时,有部分MaxCompute读取Hologres外表的任务,造成连接数使用上涨,影响其他任务。
- 出报表的时间段也是是业务进行查询的高峰期,大量写入的同时有大量的查询在同时执行,相互影响。
- 写入任务存在自动重试机制,每次oom、timeout或其它异常报错时,任务会自动重跑占用资源,导致大面积的写入任务异常越来越多。
2、优化手段:Hologres共享存储实例部署
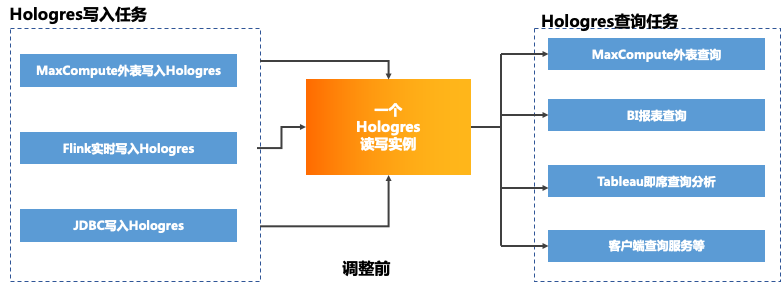
在这种情况下,我们对Hologres实例做了一些调整和优化,配置了Hologres的共享存储多实例,把读和写分离,将一个读写实例调整为一个主实例读写以及一个只读从实例,两个实例共用一份存储:
- 将业务分成不同模块,同时将报表后台、tableau、生产业务等模块的只读查询迁移到只读从实例
- 同步任务和少量的读写任务保留在读写主实例,不同模块数据存放在不同的schema,方便管理。
调整前:
调整后:

与此同时我们还根据业务现状做了一些其他优化,包括:
1、大写入任务增加session级的超时时间设置:set statement_timeout = 'Xmin' ;
2、写入之前对外表和内表进行ANALYZE ,更新统计信息加速写入;
3、取消Hologres写入任务的自动重试机制,避免影响后续的其它写入任务;
4、减少非必要的MaxCompute读取Hologres外表数据的操作,降低连接数的使用;
5、某几个数据量特别大的表,错开写入和查询高峰期,调整为其它时间段写入;
3、优化效果:系统稳定性显著提升
通过Hologres的读写分离实例部署和相关写入优化后,写入任务不再对查询任务造成影响,报表等系统能提供稳定的查询服务,同时写入任务资源使用和分配也更合理,不再出现oom之类的写入异常,系统服务稳定性有较大的提升。
后续,我们将会尝试把不同模块业务拆分到不同的只读实例,进一步增强服务的稳定性,带给服务使用方更好的体验。
六、业务价值
通过Hologres+Flink+MaxCompute搭建的流批一体实时数仓平台,支撑了小迈多个应用场场景,包括监控大盘,DMP人群等智能投放,财务分析等。显著的业务收益有:
1、上层服务共享数据
数据共享之后就由平台统一对外输出服务,各个业务线无需自行重复开发,就能快速得到平台提供的数据支撑,减少了数据孤岛。
2、亿级复杂查询秒级响应
通过Hologres自身的优秀查询性能,再配合建表和SQL的优化手段,大大提高了报表的响应速度,即使是用户画像、行为分析等亿级大表复杂关联查询也能很快出结果,得到了业务的认可。
3、系统读写分离稳定性强
通过Hologres共享存储实例部署的方式,让业务实现了读写分离,同时也只用了一份存储,既保证了系统的稳定性,同时也不会带来额外的成本压力。
作者:李云,小迈高级数据仓库开发工程师,数据仓库负责人、雷文,小迈数仓开发工程师。
本文为阿里云原创内容,未经允许不得转载。
-
相关阅读:
Excel公式:使首字母小写--某列单元格首字母小写
jvm gc日志拿取与分析思路
02 认识Verilog HDL
【正点原子I.MX6U-MINI应用篇】4、嵌入式Linux关于GPIO的一些操作
理解与应用排序算法(快速排序C实现)
http1.0到http3.0的介绍以及新特性
给电脑加硬件的办法 先找电脑支持的接口,再买相同接口的
Archery- SQL审核查询平台告警通知设置
SpringBoot 集成RabbitMQ 实现钉钉日报定时发送功能
Jackson 库中的 ObjectMapper
- 原文地址:https://blog.csdn.net/yunqiinsight/article/details/125557674