-
《Seq2Path: Generating Sentiment Tuples as Paths of a Tree》论文阅读
文章地址:https://aclanthology.org/2022.findings-acl.174/
文章介绍
最近利用生成的方式来解决方面级情感分析任务的方法虽然通过将输出转化情感元组的序列形式从而取得了一些很好的结果,但是情感元组的顺序在文本中并不是显示存在的,而且当前时刻下元组的生成也不应依赖于先前的元组。因此在这篇文章中,作者提出了一种新的生成方式:Seq2Path,该方式将情感元组的生成顺序转化为数的路径。该方式不仅可以有效的应对1对n的问题(如一个方面实体对应多个意见词),而且每个路径的生成都独立而不彼此依赖。在训练阶段,作者计算了Seq2Seq模型在路径上的平均损失。在推理阶段,作者应用了带约束的束搜索(beam search)。在此基础上,通过引入附加的token自动选择有效地路径,基本上在ABSA的各个子任务当中均取得了最好的结果。
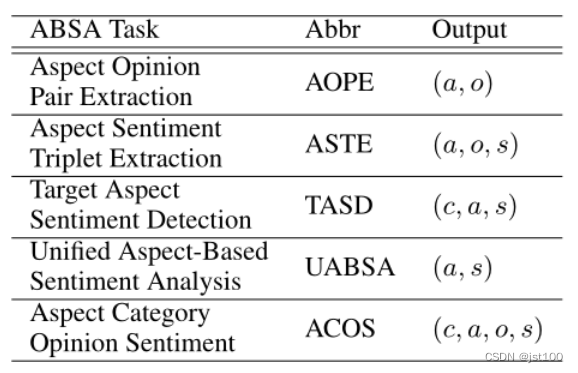
ABSA
ABSA一一般含有4个情感元素:方面实体aspect term (a), 意见词opinion term (o), 方面类别aspect category ©,以及情感极性sentiment polarity (s),对应的ABSA复合型任务及其输出如下所示。
文章方法
Seq2Path介绍
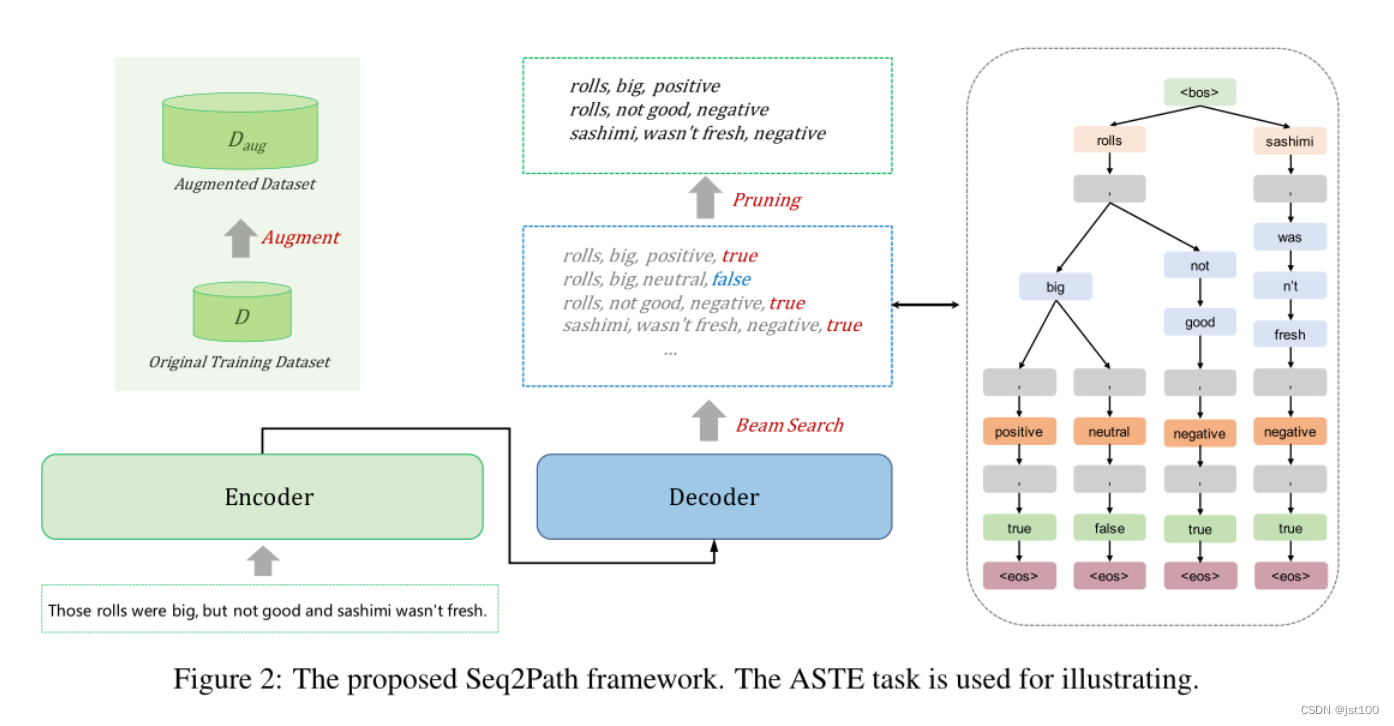
总体上来看,Seq2Path模型与一般的序列到序列模型的架构无异。首先作者将每一个元组视为一个独立的目标,并计算其平均损失,然后通过“树”的形似生成路径上的token,即利用束搜索并行且独立的生成路径。最后通过一个二分类的判别token “v”∈{true,false}判别器是否为有效路径,并添加到路径的末尾。

训练
作者的训练方式是计算路径上的平均损失,

其中k代表路径的数量,y代表数的其中一条路径,作者这里为了方便将y^i写作y。推理
对于推理作者是采用了束搜索,递减输出前k个概率最高的最可能有效的路径,当然并不是要对ABSA任务的所有步骤都需要考虑整个词汇表,如在情感极性判断上只需要在积极positive、消极negative和中性netueal中进行查找即可。一些情况特殊的限制性token如下所示

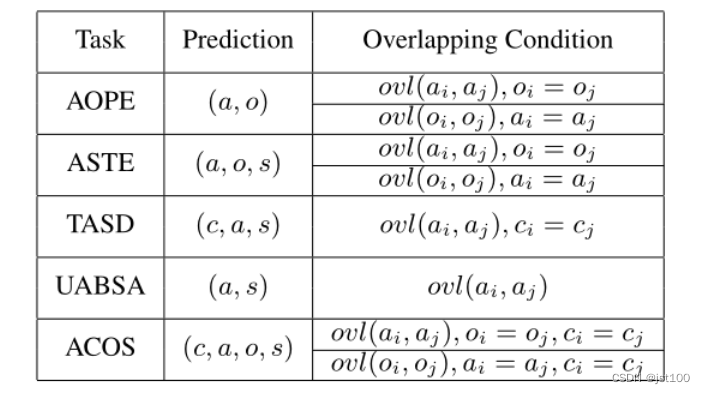
采用了这样的方式也不可避免的会出现路径重叠的情况,如“a, o, s, true”和 “a, o, s, false”等,这里作者就会去选取概率更高的路径,一些可能重叠的情况如下所示。
数据增强
由于原始的数据集中并没有针对于作者自己所加的判别token(true,false)的负样本,也就是判别为false的,因此作者这里进行了样本增强,具体分为两种方式:D1,为随机替换一些情感元素,D2为首先在很少的轮数上训练模型,然后通过束搜索从而生成负样本(也就是欠拟合的模型生成的错误路径)。最后的数据集就是生成的这样负样本与原始样本的拼接。
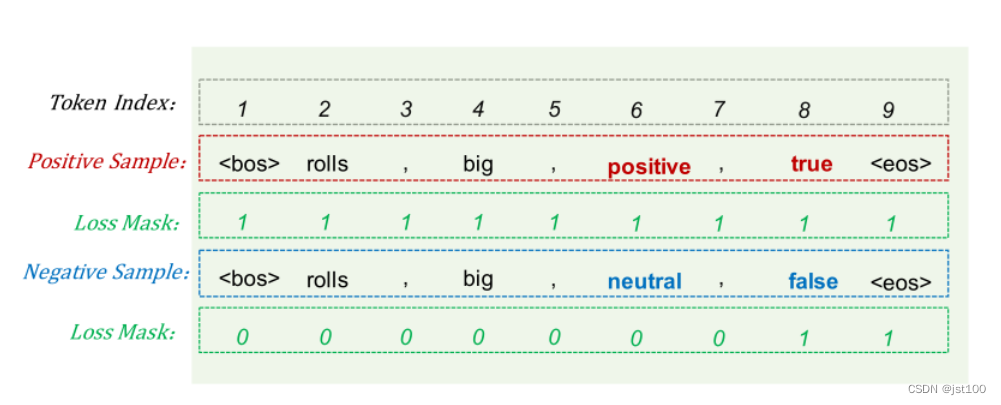
作者这里为了避免模型学习负样本的路径,对负样本路径的损失进行了mask处理(一个trick),对于正样本就不动。具体方式如下:
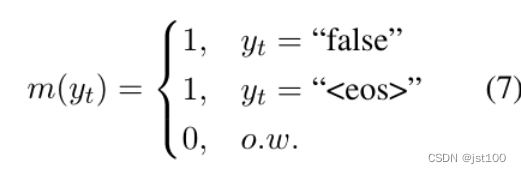
也就是说只对最后的判别token和结束标志有损失传播,其余均为0,样例如下所示
算法
总的算法如下所示,作者这里基本都是用文本描述的,就不再翻译了。

why?
为什么树型
这里作者主要是介绍了为什么采用这种树形的方式,而不是以前直观的序列元组的形式。首先就是作者认为tree可以更好的学习到这种条件转移概率 ,比如对于下图这个例子
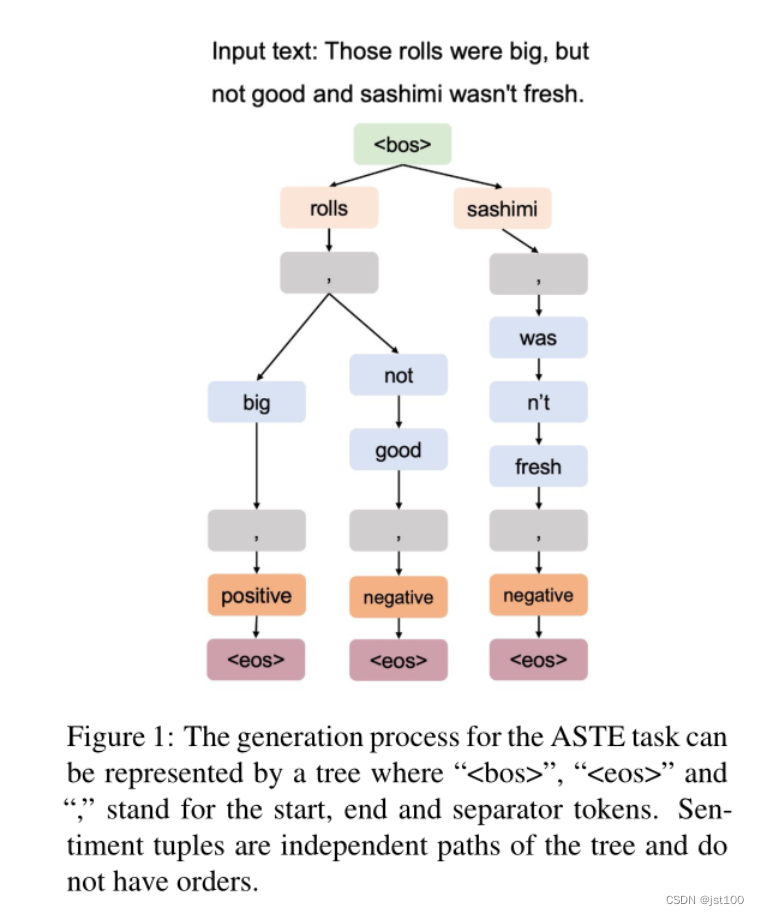
普通的序列模型会在每个时间步直接生成一个独热向量:
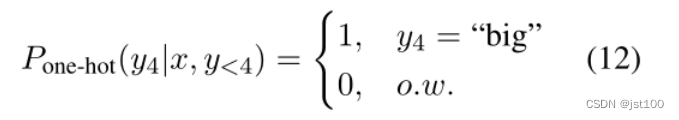
而作者采用的束搜索,就可以生成“多热”向量,从而有效地处理一对多的情况,所以我感觉作者的前提是用了束搜索,所以是一个树型的生成路径,所以要额外添加判别token,因为生成的路径只是概率高,但不一定就对。
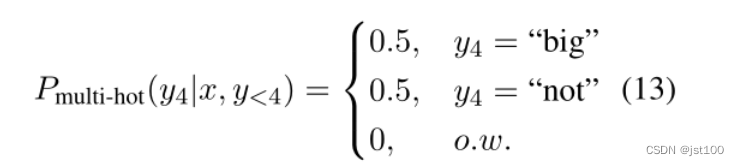
为什么是路径的平均损失?
作者这里是证明了,对于独热向量的平均交叉熵损失等于多热向量转移概率的交叉熵损失。首先假设我们这次要有k个候选结合,也就是束搜索的size为k,那么k个路径在t时刻前的输出如下:
v代表当前时刻要根据前t-1时刻输出的token,那么对于多热向量的转移概率如下所示,也就是走某条的路径的概率是均等的。
 而另一方面,对于普通的序列模型其对于一条路径(独热向量)的转移概率如下所示
而另一方面,对于普通的序列模型其对于一条路径(独热向量)的转移概率如下所示
对于多热向量的目标的交叉熵损失如下所示(结合公式(14)),p为目标概率分布,y为预测概率分布
现在,考虑所有路径上的平均损失,那么对于第i个路径,由于其是一个独热向量,也因此有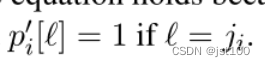
从而推导出下式
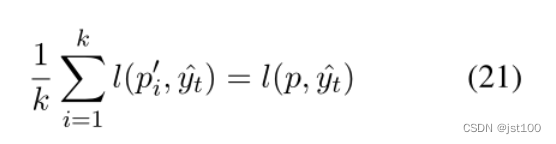
原论文的一个小错误
在论文的附录A.2节这里 ,作者写了一个小错误
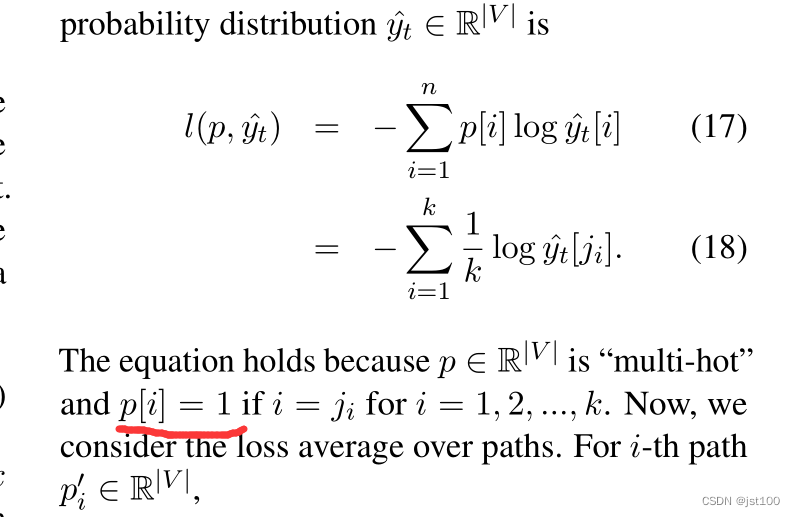
这里应当是1/k,而不是1,我发邮件询问了作者也得到了肯定的回复,后续作者也会将修改好的版本放在arxiv上。 -
相关阅读:
STM32CubeMX教程14 ADC - 多通道DMA转换
JAVA URL请求
基础 | NIO - [FileLock]
基于探针的分布式追踪工具
openlayers版本更新差别
1-图像读取
免费无版权可商用资源|自媒体创业者、设计师、电商商家必备
爬虫及词云总结
【Python】减少不必要的 for 循环
学习笔记:SpringCloud 微服务技术栈_高级篇②_分布式事务
- 原文地址:https://blog.csdn.net/jst100/article/details/125546186