-
排序模型(learning to rank)发展史
前言
「排序」是一个非常业务化的任务,其实践场景也多为搜索、广告、推荐,被用于解决排序任务的模型也被人一统称作了「排序模型」,但其实「排序模型」也是「普通模型」,只不过或多或少在业务层面针对排序做了一些针对。
观察每一类算法模型的发展,最重要的不是事无巨细的记住所有迭代模型的细节,而是明白每一次发生迭代,每一次技术革新,都或多或少解决了上一代模型存在的某一些问题。记住他们迭代的契机,才是通晓了整个历史。
这次就来梳理一下排序模型的发展史。
前深度学习纪元——机器学习与想象力
典中典——协同过滤
提起推荐系统中的算法,最经典的莫过于协同过滤。协同顾虑最早可以追溯到 1992 年,Xerox 的研究中心开发了一种基于协同过滤的邮件筛选系统,用于过滤一些用户不感兴趣的邮件,但在当时并没有引起很大的凡响。
直至 2003 年,Amazon 发表论文《Amazon.com recommendations: item-to-item collaborative filtering》,协同过滤才较为广泛地被人们所知。协同过滤的原理非常简单,就是协同大家的反馈、评价和意见一起对海量信息进行过滤。简单来说,就是「臭味相投」、「一丘之貉」。
钢铁侠 肖申克的救赎 奇异博士 遗愿清单 用户1 9 6 9 3 用户2 5 10 6 9 用户3 6 9 7 ??? 上表为「共现矩阵」,协同过滤的思路为根据相同爱好的用户,推荐相同的电影,这听上去非常 make sense。在不知道问好处的评分时候,通过已存在的评分,我们发现用户 3 与用户 2 更相似,用户 2 对《遗愿清单》给出了高分,所以用户 3 也应该受到推荐。
每个用户可以用自己的历史行为序列——评分来代表,所以每个用户就是一个向量,所有描述向量相似度的方法都可以用来计算「用户的相似度」,缺失的部分可以用默认值或者均值来代替。在实际场景中用户数量肯定不止例子中的三个,最终结果排序的方式为获取 topn 的相似用户之后,利用他们对目标电影的评分的均值来决定当前用户的评分,也可以利用相似度加权平均。
从另外一个角度,还有「推荐喜欢物品的相似物品」这个思路,其实原理是相似的,也需要共现矩阵,无非列向量代表物品/电影罢了。两类主要是在应用场景上有区别,基于用户的协同过滤使用在偏社交属性的场景,并能够通过相似兴趣的朋友拓展新的兴趣,比如新闻热点。基于物品的协同过滤则适用于兴趣变化比较稳定的场景,比如电商。
协同过滤是一个非常直观、可解释性强的模型,但他有一个很严重的问题——热门物品由于其头部效应,容易跟其他大量物品产生相似性,也就是不管喜欢啥的用户,可能都喜欢头部物品。尾部物品由于向量稀疏,很少与其他物品产生相似性,导致很少被推荐。推荐结果头部效应明显,处理稀疏向量的能力弱,是协同过滤的天然缺陷。
矩阵分解——协同过滤的进化
矩阵分解加入了隐变量的概念,认为「共现矩阵」是有两个更小的矩阵乘得,一个是用户 embedding,一个是物品 embedding。
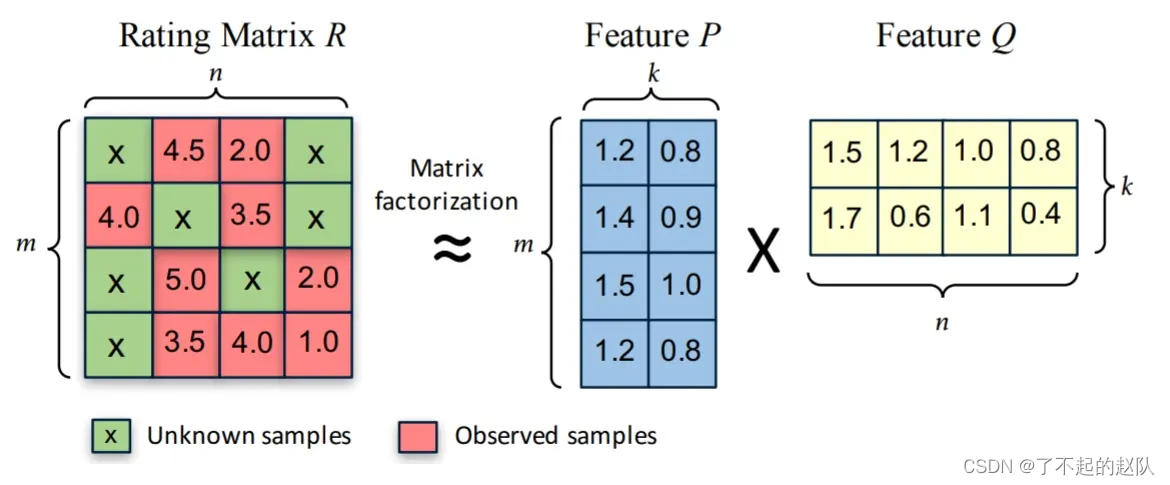
依据共现矩阵中已经存在的打分去训练得到两个小矩阵,反向推导得到未知分数。假设共现矩阵为 m * n,那么两个小矩阵的形状为 m * k 和 k * n,k 一般远小于 m 和 n,具体由尝试得到。矩阵分解的求解方法也是梯度下降,两个小矩阵为变量,目标是乘积后的结果去接近共现矩阵中已经存在的打分。矩阵分解的优势在于一定程度解决了稀疏问题,泛化能力强,而且将共现矩阵退化为两个小矩阵后,极大的节约了存储开支。**不足在于矩阵分解只能用于共现矩阵,**还有很多用户侧的画像信息、物品侧的信息都无法使用,单纯的矩阵分解无法使用其他特征。(但是分解后的结果可与其他特征组合
逻辑回归——能融合多种特征的简单模型
逻辑回归应该都比较熟了,假设数据分布符合伯努利分布,线性回归拟合对数几率,结果在0-1之间,可表示概率。
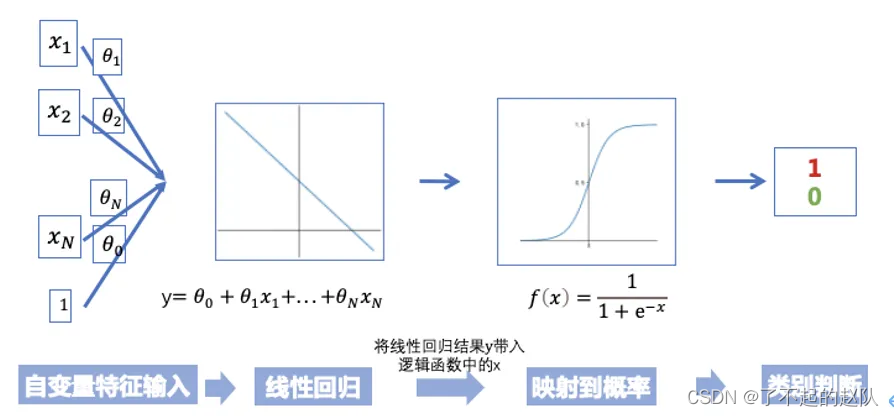
线性回归的优势在于不管啥特征,前期数据处理后一箩筐都能扔进去,而且可解释性强,每个特征一个权值,能直观的看出哪些特征起了主导作用。逻辑回归的优势在于简单直观易用,不足在于表达能力有限,无法进行特征交叉,无法充分挖掘数据中的信息。
POLY2——无脑特征交叉解决方案
poly2 在逻辑回归的基础上加入了特征交叉方案。
人工特征交叉一般会选择特定的一些特征进行手动交叉组合,这些交叉的特征一般也具有业务含义。poly2 选择无脑暴力全部交叉,组合所有可能,然后赋予不同的权值,权值是由训练得到。公式如下:
∅ POLY2 ( w , x ) = ∑ i 1 = 1 n ∑ j 2 = i 1 + 1 n w h ( j 1 , j 2 ) x j 1 x j 2 \emptyset \operatorname{POLY2}(w, x)=\sum_{i_{1}=1}^{n} \sum_{j_{2}=i_{1}+1}^{n} w_{h\left(j_{1}, j_{2}\right)} x_{j_{1}} x_{j_{2}} ∅POLY2(w,x)=i1=1∑nj2=i1+1∑nwh(j1,j2)xj1xj2最暴力的方法往往不是最好的,就如同把一张图片所有像素拍平用全连接神经网络其实不如卷机神经网络一样,这样组合所有的可能性,在特征稀疏时候(例如 one-hot)带来了训练上的困难,由于稀疏性提督也传不过来,很多权值缺乏有效的训练,造成收敛困难。再一个是,这种组合方式实在是,太暴力了,参数数量对比逻辑回归直接平方增长,复杂度太高。
FM——借鉴了矩阵分解的特征交叉方案
FM 算法全称因子分解机,顾名思义,名字中带有分解,那肯定得分解啊。FM 算法借鉴了矩阵分解的思路,不想 poly2 那样儿,每个组合按一个权值,而是认为每个特征有自己权值,组合的权值是组员权值乘积。公式如下:
∅ F M ( w , x ) = ∑ j 1 = 1 n ∑ j 2 = j 1 + 1 n ( w j 1 ⋅ w j 2 ) x j 1 x j 2 \emptyset \mathrm{FM}(w, x)=\sum_{j_{1}=1}^{n} \sum_{j_{2}=j_{1}+1}^{n}\left(w_{j_{1}} \cdot w_{j_{2}}\right) x_{j_{1}} x_{j_{2}} ∅FM(w,x)=j1=1∑nj2=j1+1∑n(wj1⋅wj2)xj1xj2同样,FM 也是在逻辑回归的基础上加入了特征交叉方案,只不过交叉方式没有那么暴力,如果将 poly2 的交叉权值比作上文中提到的「共现矩阵」,那么 FM 的交叉权值就是矩阵分解后的两个小矩阵,这样做的优点在于极大地减少了参数量,复杂度由 poly2 的 n 2 n^2 n2 变为 n k nk nk(k为小矩阵的维度看上去 FM 已经进化完全了,解决了之前的痛点,而且自身没有什么特别明显的硬伤。实际上也是这样,在深度学习到来之前,FM 基本上就是主流模型,即使后面有优化,也都是锦上添花的小操作。在 2012 - 2014 年前后,FM 就是主流的推荐模型之一。
FFM 模型——锦上添花,引入特征域
特征域这个东西,简单来说就是针对不同的特征有不同的权值。例如有 A、B、C 三个特征,按照 FM 的做法,在特征组合的地方,对应也有三个权值 W A W_A WA、 W B W_B WB、 W C W_C WC,哪两个组合就哪两个权值相乘。
FFM 的变化在于针对不同的组合,有不同的权值。也就是说特征 A 不只有一个权值,而是针对特征 B 有一个,针对特征 C 也有一个,不同的组合选择对应的权值。
其实还是利用复杂度和参数量换取更多的特征组合后的表达能力,到底算不算进步这个见仁见智吧。
从 poly2 到 FFM,一路过来都是在追求特征组合的性价比,在性能和代价之间做一个平衡。如果非说 FM 系列算法有什么硬伤的话,那就是没办法进行三阶特征组合,因为组合的数量就爆炸了。
GBDT + LR ——高阶组合与自动筛选
树模型由于其优越的机制天生拥有特征筛选和高阶组合能力,将树模型的结果作为逻辑回归的输入,最终目标转化为预估 CTR,这是直观上 make sense 的想法。
首先来说 GBDT 的部分,GBDT 使用的是回归树,如果要转变成分类问题,可以借鉴逻辑回归的 loss,如下:
L = arg min [ ∑ i n − ( y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ) ] L=\arg \min \left[\sum_{i}^{n}-\left(y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)\right)\right] L=argmin[i∑n−(yilog(pi)+(1−yi)log(1−pi))] GBDT 的训练目标仍然是 CTR 预估,最终生成 N 棵树后,将数据落入的叶子节点的位置置1,其余位置置0,拼接成0/1向量进入下一阶段的逻辑回归。
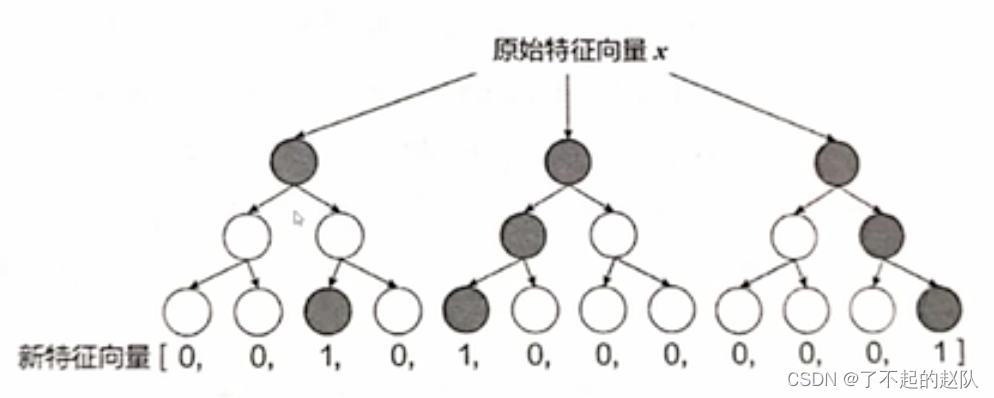
如上图所示,0/1特征进入逻辑回归后正常训练二分类即可。上图中的例子其实已经是三阶特征组合之后的结果,更深的树则拥有更高的组合阶数。当然,逻辑回归中仍然有原始特征作为输入,组合特征是额外输入。这种两阶段的方式不必担心逻辑回归的提督如何向上传导至 GBDT 的问题,极为方便,GBDT 部分可以看作原始流程中的「特征工程」。GBDT 这种特征交叉方式无疑是高阶的,但最后转换为 0/1 也损失了大量的信息,效果相比 FM/FMM 而言,也是见仁见智吧。它的重要贡献在于,实现了特征工程的自动化,实现了真正的端到端的训练。
LS-PLM——接近深度学习的推荐模型
LS-PLM 其实在 2012 年就被阿里巴巴作为主流推荐模型了,只不过在 2017 年才公布出来。
LS_PLM 的思路是将数据从业务层面分类后然后分别进行逻辑回归,分而治之。例如女性专用商品的场景就会排出男性用户的数据,以获得更干净准确的训练数据,其实就是多个 LR 作用在不用的业务域,这是一个纯业务上的 idea。而且在逻辑回归的后面,还加了 L1 和 L2 正则,不过这都是小的锦上添花。
在预测阶段,首先过一个分类模型,这里为softmax,然后根据不同类别的概率对不同域内的逻辑回归结预测的 ctr 结果进行融合,公式如下:
f ( x ) = ∑ i = 1 m π i ( x ) η i ( x ) = ∑ i = 1 m e μ i ⋅ x ∑ j = 1 m e μ j ⋅ x ⋅ 1 1 + e − w i ⋅ x f(x)=\sum_{i=1}^{m} \pi_{i}(x) \eta_{i}(x)=\sum_{i=1}^{m} \frac{e^{\mu_{i} \cdot x}}{\sum_{j=1}^{m} e^{\mu_{j} \cdot x}} \cdot \frac{1}{1+e^{-w_{i} \cdot x}} f(x)=i=1∑mπi(x)ηi(x)=i=1∑m∑j=1meμj⋅xeμi⋅x⋅1+e−wi⋅x1逻辑回归本来就非常像一个最简单的神经网络,加上这种分而治之的策略,就更想神经网络 + attention 机制了,这也是深度学习来临之前最接近深度学习的一次。
深度学习纪元——大杀器来临
AutoRec——矩阵分解的NN版本
-
相关阅读:
MFA-Conformer
【Node.js+koa--后端管理系统】设计标签创建、查询、接口 | 标签绑定到动态
UML 类图
袋鼠云产品功能更新报告01期丨用诚心倾听您的需求
NodeJS | 基于NodeJS的轻量级静态服务器 http-server
信源编码 | 无线通信基础知识
机试打卡 -05 接雨水(动态规划&栈)
世界各国当日数据探索性分析
生成二维码并支持下载
builder(建造者模式)
- 原文地址:https://blog.csdn.net/zhaojc1995/article/details/125520865