-
jmm内存模型及volatile实现原理
一,深入理解java内存模型
1,什么是jmm模型
java memory model,java内存模型,是一种针对于多线程工作的一种抽象的规范,主要是针对在多线程的并发状态下,共享资源是如何被访问的。jmm只是一种抽象的概念,并不真实存在。
jvm运行的实体是线程,每个线程在创建jvm时都会创建一个工作内存,用于存储私有的数据。java内存模型规定所有的共享变量都存储在主内存中,主内存是共享的内存区域,私有线程都可以访问。但是线程操作变量必须在工作内存中进行,即通过拷贝复制的方式,对线程操作完成之后再将线程写回到主线程中。不能直接操作主内存的变量,必须通过变量的副本拷贝到工作内存中。当然jmm这个主内存不像jvm一样真实存在具体的区域,只是一种抽像出来的一种模型,即线程开启之后,就会存在这种无形的规范。
工作内存是私有数据,因此不同线程无法访问对方的工作内存,即本地变量对于其他线程是不可见的,线程间的通信需要通过主线程完成
如下图所示。

共享变量是存储在主内存里面的,线程ABC都是通过复制这个变量作为副本加入到当前线程的工作内存里面。主内存主要存储的是java的实例对象。所有创建的实例对象都存放在主内存中。由于是共享区域,多条线程在访问同一个变量时就会可能发生线程安全的问题。如下面的initFlag这个就是存储在主内存中,线程AB就是两个独立的线程,会去访问主内存中的这个变量initFlagpublic class Jmm_Study { //共享变量,存储在主内存中 private volatile static boolean initFlag = false; //计数器 private volatile static int counter = 0; public static void refresh(){ log.info("refresh data......."); initFlag = true; log.info("refresh data success......."); } public static void main(String[] args){ Thread threadA = new Thread(()->{ while (!initFlag){ //System.out.println("runing"); //counter++; } log.info("线程:" + Thread.currentThread().getName() + "当前线程嗅探到initFlag的状态的改变"); },"threadA"); threadA.start(); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } Thread threadB = new Thread(()->{ refresh(); },"threadB"); threadB.start(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2,数据同步的八大原子操作
1,lock:作用于主内存的变量,把一个变量标记为一条线程独占状态
2,unlock:把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
3,read(读取):作用于主内存中,需要先对变量进行副本的拷贝,然后将变量值传输到工作内存中
4,load(载入):在工作内存中,需要对传输过来的副本变量进行一个获取,并且存入到工作内存中
5,use(使用): 需要将获取的变量传给执行引擎
6,assign(赋值):执行引擎会将这个收到的变量赋值给工作内存的变量
7,store(存储):修改这个传过来的副本之后,会将修改的值存储并送到主内存中
8,write(写入):会将这个存储的变量写回到主内存中即每个操作都具有原子性,即运行期间不可中断。并且必须按 read–>load–>use 、assign–>store–>write这个顺序执行,不允许乱序
3,java并发的三大特性
可见性:基于jmm的内存模型可知,线程之间的内部变量时不可访问的。所以为了知道别的线程修改了这个对象的变量之后,自己线程也要知道,因此增加了这个可见性的规范。即线程B修改了主内存的变量值,需要去通知线程A,这个值被修改了,并且重新去获取新的值。如通过volatile实现
原子性:要么同时成功,要么同时失败。一个操作是不可中断的,即使是在多线程环境下,一个操作一旦开始就不会被其他线程影响。
有序性:从时间片的角度上看,代码应该从上往下顺序执行,如入栈出栈等。但是编译器认为如果经历指令重排之后,即代码的执行顺序与代码的编写顺序不一致,这样的话cpu的效率会更高。除了cpu之外,这个java的编译器也会对这个代码进行指令重排。volatile:java并发里面的一个轻量级的锁。可以保证可见性,也可以保证有序性,但是不能保证原子性
4,volatile
在字节码方面:对象会有一个ACC_VOLATILE指令
在底层方面:主要通过这个EMSI协议,来保证这个缓存的一致性。
在现象方面:主要可以保证数据的可见性和有序性
可以保证修改之后别的线程可以及时的看到。主要是通过这个缓存行的方式实现。但是不加volatile也能看到别的线程的更改,但是看到的时间不能确定。volatile只是保证了这个及时性。
通过以下程序可以发现,在不用synchronized锁时,这个volatile修饰的counter并不能保证这个原子性。private volatile static int counter = 0; static Object object = new Object(); public static void main(String[] args) { for (int i = 0; i < 10; i++) { Thread thread = new Thread(()->{ for (int j = 0; j < 10000; j++) { //保证原子性 //synchronized (object){ //counter++;//分三步- 读,自加,写回 //} counter++; } }); thread.start(); } try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(counter); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
如假设两个线程A和B都去操作这个count++,通过这个八大原子类操作可以发现,需要先将数据加到工作内存中,最后修改之后再把数据返回给主内存中,因此每个线程都有以下两个步骤在工作内存中:
counter = 0;线程A1 counter = 0;线程B1 ... counter = counter + 1;线程A2 counter = counter + 1;线程B2 ...- 1
- 2
由于在多线程的场景下,每个线程获取cpu的资源都是轮询的。因此可能会出现以下场景,线程A在执行到A1时,cpu资源此时给到了线程B,线程B会去主内存中获取这个counter并且修改这个counter值,完成之后会将值返回到主内存中,并且之后会告诉其他线程这个值已经被修改,此时线程A收到了这个通知,因此也会去主内存中获取到这个值,但是,之前存在的线程A的A2步骤就会被丢弃,这样就会导致counter少加1,这就解释了为什么最终结果会小于上面的100000了。因此volatile并不能保证线程之间的原子性。
内部通过内存屏障的方式实现有序性,禁止了指令重排。内存屏障会告诉这个编译器,哪些地方不能实现这个指令重排,否则会直接报错。
public class CodeReorder { private static int x = 0, y = 0; private static int a = 0, b = 0; public static void main(String[] args) throws InterruptedException { int i = 0; for (;;){ i++; x = 0; y = 0; a = 0; b = 0; Thread t1 = new Thread(new Runnable() { public void run() { shortWait(10000); a = 1; x = b; //手动实现指令重排 UnsafeInstance.reflectGetUnsafe().fullFence(); } }); Thread t2 = new Thread(new Runnable() { public void run() { b = 1; UnsafeInstance.reflectGetUnsafe().fullFence(); y = a; } }); t1.start(); t2.start(); t1.join(); t2.join(); String result = "第" + i + "次 (" + x + "," + y + ")"; if(x == 0 && y == 0) { System.out.println(result); break; } else { log.info(result); } } } /** * 等待一段时间,时间单位纳秒 * @param interval */ public static void shortWait(long interval){ long start = System.nanoTime(); long end; do{ end = System.nanoTime(); }while(start + interval >= end); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
5,CPU缓存一致性
5.1MESI协议
MESI协议规定:对一个共享变量的读操作可以是多个处理器并发执行的,但是如果是对一个共享变量的写操作,只有一个处理器可以执行,其实也会通过排他锁的机制保证就一个处理器能写。MESI为缓存一致性协议中的其中一种,这四个字母分别表示四种状态
M :Modified,在缓存行中,将主内存读取的数据修改了
E :Exclusive,互斥或者独占状态,当前只有本cpu中获取了这个变量
S :Shared,共享状态,此时有多个cpu中的缓存行中都获取了这个变量
I :Invalid,失效状态,如果其他cpu中的缓存行这个值修改之后,当前cpu中的值就是脏数据,需要设置成失效状态
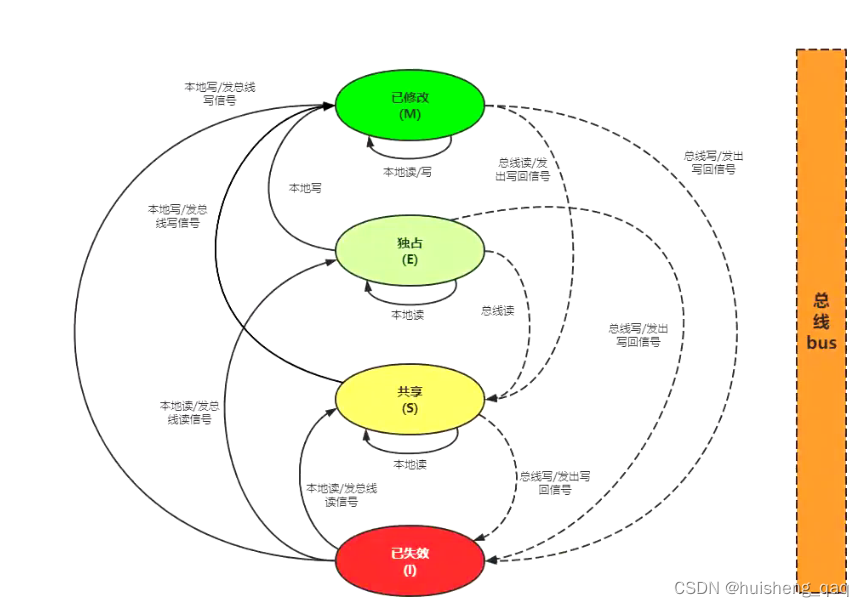
工作原理:cpu启动之后会采用一种监听的模式,一直监听bus总线里面的消息的传递。任何人通过bus总线从内存里面获取了东西,cpu都可以感知到。
1,如一个cpu0要读取变量x,先从总线里面获取变量x,如果被lock前缀修饰之后,就会被cpu0监听到消息被读取,在读取的cpu里面会增加一个这个变量的副本,并且此时设置的状态为E,独占状态;
2,如果此时有cpu1读取这个变量,也会在cpu1里面增加一个副本,并且由于有多个cpu此时都拥有这个变量的副本,因此会将这个状态设置为S共享状态;
3,如果两个cpu都要修改同一个变量,则需要在每一个cpu里面的缓存行上加锁。如果其中一个cpu,如cpu0将这个变量值修改,则需要往bus总线里面发出修改的消息,并且告知cpu1里面拥有同一个变量的缓存行,此时cpu1里面的这个数据就变成了脏数据,状态需要设置成I,失效状态,并且需要去主内存中读取这个新数据。bus总线需要去裁决哪个cpu可以获取修改这个变量的资格,如果总线裁决失效,就会上升到总线锁。
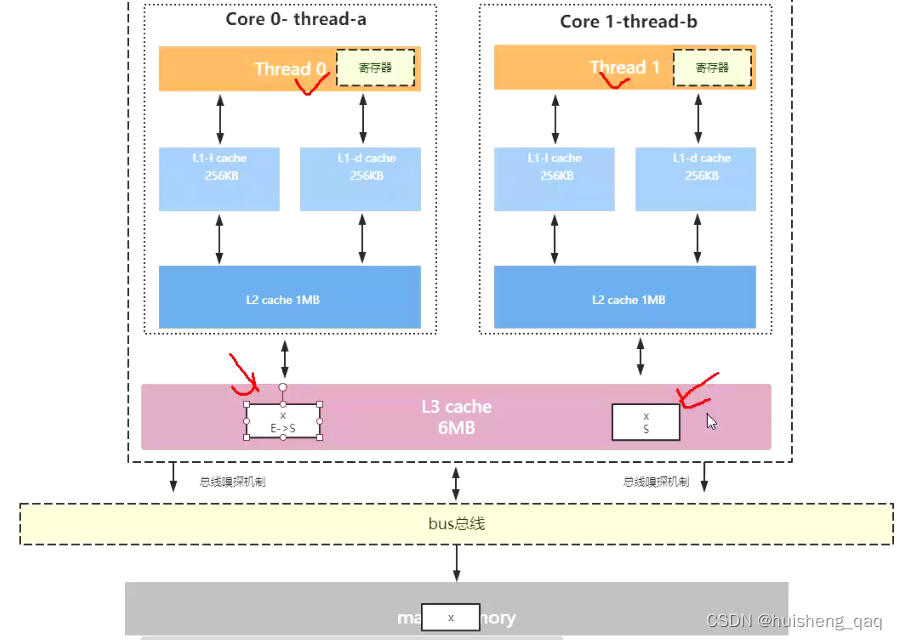
5.2,volatile不保证原子性
结合这个MESI这个协议,再来分析一下之前这个counter,就可以很清楚的知道为啥小于100000次了。
counter = 0;线程A1 counter = 0;线程B1 ... counter = counter + 1;线程A2 counter = counter + 1;线程B2 ...- 1
- 2
如下图,在cpu0和cpu1同时从主内存将这个副本拷贝到工作内存中,并且同时保存在当前cpu的缓存行中。此时两个cpu都要向这个bus总线发送修改这个变量的请求,bus总线会通过这个总线裁决的方式来判断哪个cpu拥有这个修改这个变量的执行权,主要通过这个电位高低的方式实现,如此时cpu1获取到修改这个变量的执行权,那么就会执行以下的第三步,此时执行counter = counter + 1,并且会告知拥有这个变量的其他cpu,如cpu0,这个变量被修改了,此时cpu0的counter也会接收到这个通知,并且会将当前的counter设置成失效状态,并且会丢弃它,那么这个第四步就会不执行,这样就失去了一次counter++的操作,这样就导致了这个总和小于100000了。
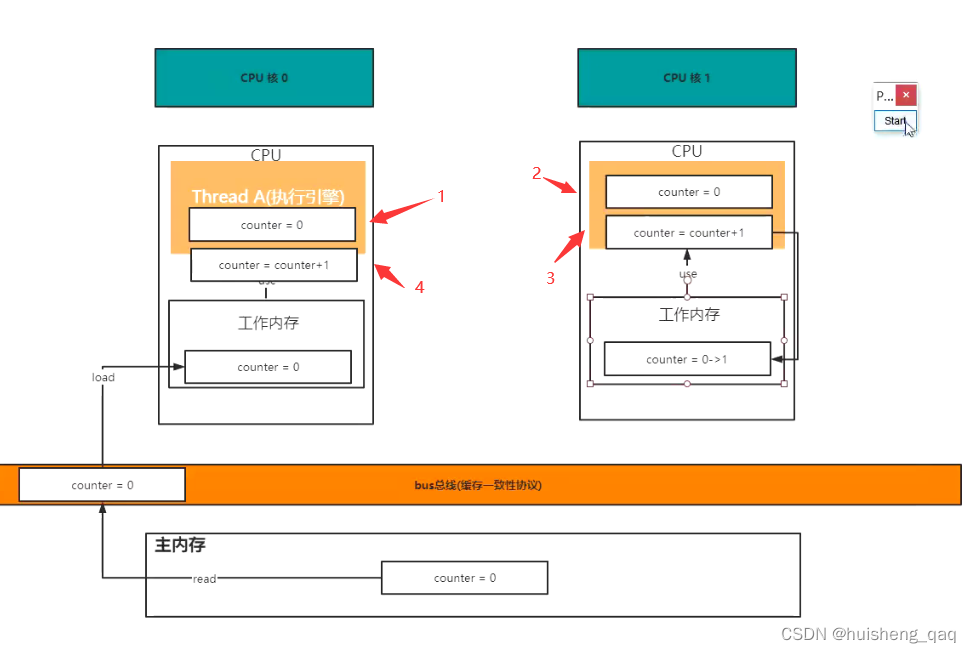
当然这个cpu0里面的这个counter也不一定是丢弃,也可能是覆盖。EMSI只能保证这个缓存行的一致性,但是如果这个cpu0里面的1,4操作已经处于这个寄存器中,那么这个counter不一定只会去这个内存中获取这个最新值,也可能是从寄存器获取到这个最新值。无论是覆盖还是丢弃,都可以得到最后的counter值为1,同时也说明了这个volatile并不能保证这个原子性。
6,总结
就是通过这个JMM的内存模型来规范这个在多线程的场景下的共享变量的访问,并且通过八大原子操作,规范每一个线程的执行步骤。在多个线程只需要保证有序性和可见性的时候的时候,可以直接使用这个volatile,并且通过这个EMSI协议来保证缓存的一致性,即用一句话来解释volatile就是,主动刷新主内存,强制过期其他线程的工作内存
-
相关阅读:
Notepad++ 常用
大屏可视化开发
2023高教社杯数学建模B题思路代码 - 多波束测线问题
python中Request Payload参数使用(持续更新)
SpringMvc 如何同时支持 Jsp 和 Json 接口?
JavaScript作用域链与预解析
黑马JVM总结(二十三)
微服务架构的现状与未来:服务网格与云原生趋势解析
vtkImageViewer2 解析
【数据结构】单链表
- 原文地址:https://blog.csdn.net/zhenghuishengq/article/details/125550673
