-
string(讲解)
1.标准库里面的string类了解
- string是表示字符串的字符串类
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedefbasic_string<char, char_traits, allocator>string;(报错是basic_string不用太注意)
- 不能操作多字节或者变长字符的序列。在使用string类时,必须包含#include头文件以及using namespace std;
2.sting常用的构造函数用法
#include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个是最常用的,作用是管理动态增长的字符数组,以\0为结尾。
但是注意这里是不能编译成功的
因为在使用string类时,必须包含#include头文件以及using namespace std;(因为c++标准库都是存放在std里面的)如果不包std,可以按下面用法
代码#include<string> //管理动态增长的字符数组,以\0为结尾 int main() { std::string s1; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
不过当然啦,这里我们为了使用方便我们就把std全部展开
string还有一种写法,就是#include<iostream> using namespace std; #include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; string s2("hello world"); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这种就是用常量字符串来初始化,这个使用new或者malloc出来的,然后就把这个数组拷贝过去,这种有个最大的优点就是它这个是动态增长的,你搞个数组它的大小是定死的,但是string的这个可以动态增长,原理也很简单,因为是扩容
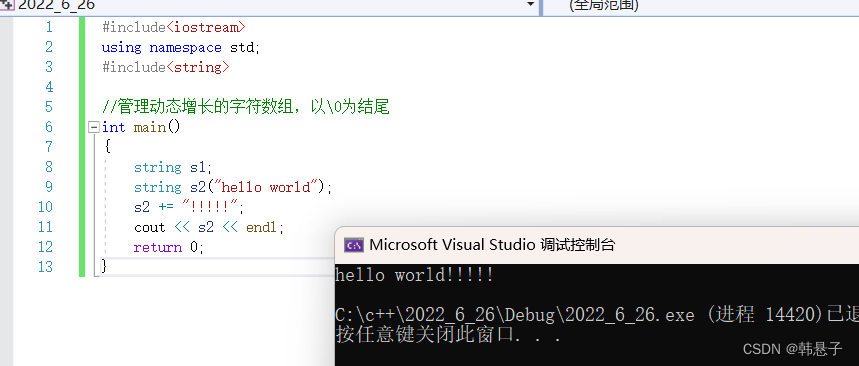
用法#include<iostream> using namespace std; #include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; string s2("hello world"); s2 += "!!!!!"; cout<<s2<<endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
打印结果
不过当然除了这种还有一种拷贝构造
代码#include<iostream> using namespace std; #include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; string s2("hello world"); s2 += "!!!!!"; cout << s2 << endl; string s3(s2); string s4 = s2; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
只要拿一个以存在的对象,去初始化一个未存在的对象,这个都是拷贝构造
还有一种写法,就是想要用这个字符串前n个来初始化,后面的不要
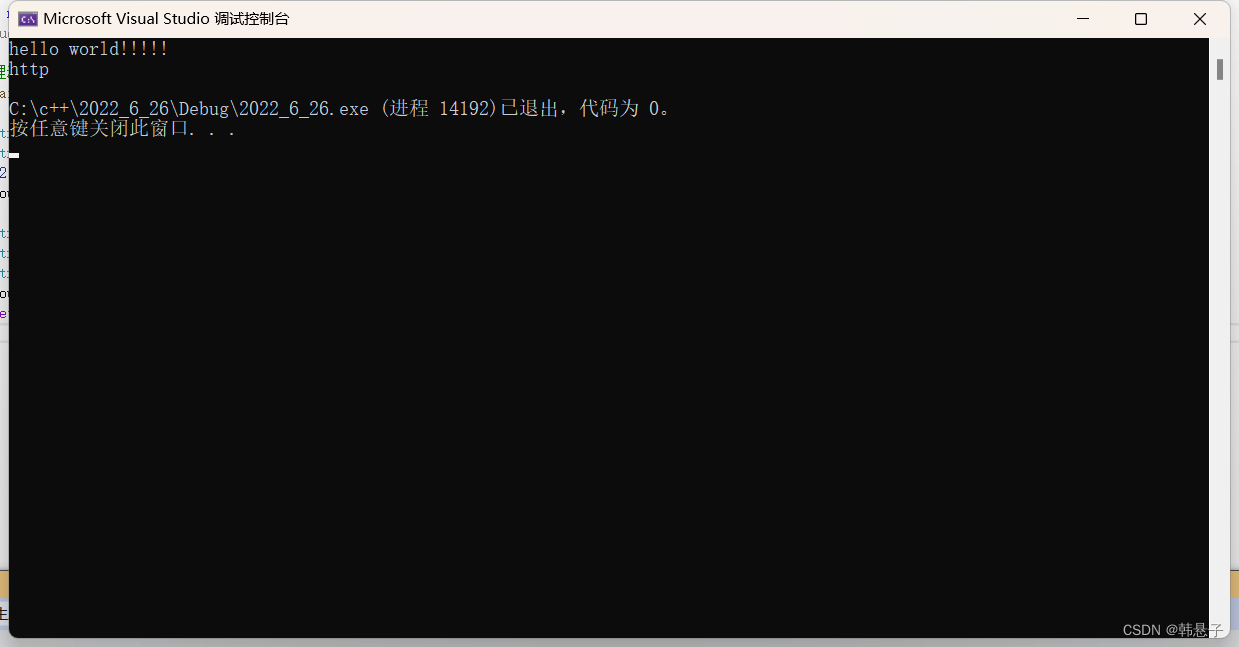
代码#include<iostream> using namespace std; #include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; string s2("hello world"); s2 += "!!!!!"; cout << s2 << endl; string s3(s2); string s4 = s2; string s5("https://editor.csdn.net/md?articleId=125475746", 4); cout << s5 << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果
还有一种是从某个字符串n位置做起始,拷贝n个字符
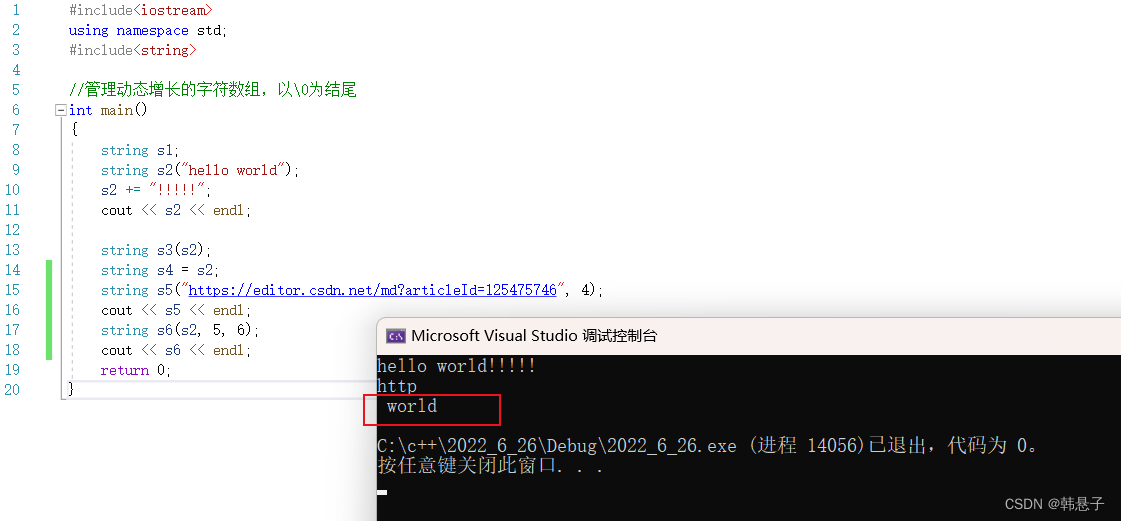
代码#include<iostream> using namespace std; #include<string> //管理动态增长的字符数组,以\0为结尾 int main() { string s1; string s2("hello world"); s2 += "!!!!!"; cout << s2 << endl; string s3(s2); string s4 = s2; string s5("https://editor.csdn.net/md?articleId=125475746", 4); cout << s5 << endl; string s6(s2, 5, 6); cout << s6 << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果
不过这里如果我只要了6个,要是我要100个会报错吗?
答案是不会,超过字符串大小会是有多少给多少3.string小练习
我们把string的用法讲的差不多了我们来做下题吧
题链接题描述
给你一个字符串 s ,根据下述规则反转字符串:所有非英文字母保留在原有位置。
所有英文字母(小写或大写)位置反转。
返回反转后的 s 。不过当然想做这道题最主要的是会遍历字符串
前面没讲string的遍历方式第一种遍历方式的代码
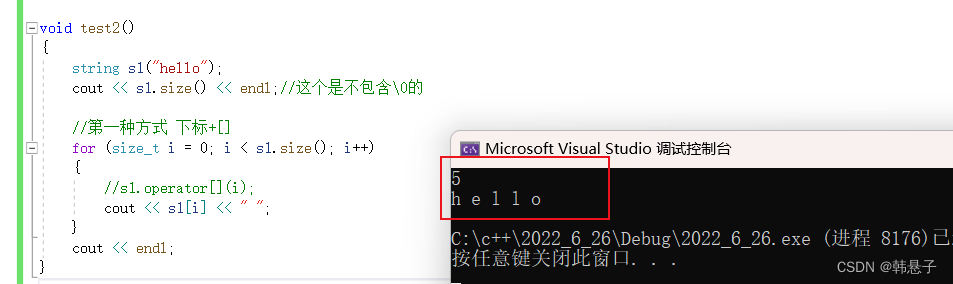
1.下标+[]void test2() { string s1("hello"); cout << s1.size() << endl;//这个是不包含\0的 //第一种方式 下标+[] for (size_t i = 0; i < s1.size(); i++) { //s1.operator[](i); cout << s1[i] << " "; } cout << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个要注意的是这里的size是不包含\0的所以打印是5个,还有遍历方式也是不同这个不是数组,这个相当于调用函数,相当于调用s1.operator;
运行结果
第二种遍历方式
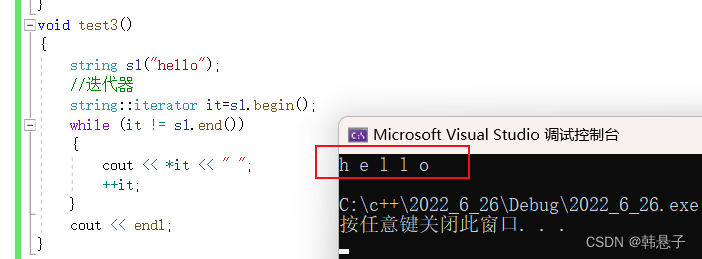
2.迭代器void test3() { string s1("hello"); //迭代器 string::iterator it=s1.begin(); while (it != s1.end()) { cout << *it << " "; ++it; } cout << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这种是迭代器遍历,迭代器是像指针一样的东西或者就是指针,s1.begjn()是代表着起始的位置,而end()是代表着结束的下个位置,其实就是左闭右开。
这里还有一个问题就是能不能把it != s1.begin()改成it < s1.begin(), 在1某些情况可以,比如它们空间是连续的,但是不推荐<的这种写法,因为你的内存不一定是连续的,一旦不是连续的你就会出现错误了运行结果
第三种遍历方式
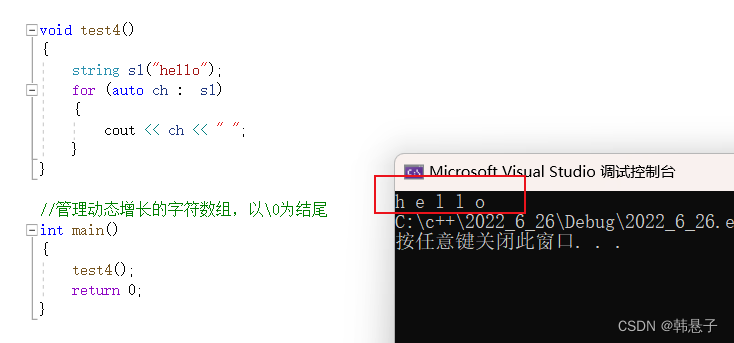
void test4() { string s1("hello"); for (auto ch : s1) { cout << ch << " "; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.范围for
原理很简单,其实底层原理就是替换成迭代器运行结果
题目答案
下标+[]的写法class Solution { public: bool isLetter(char ch) { //只要是26位字母就返回真 if( ch >='a' && ch<='z') return true; else if(ch>='A' && ch<='Z') return true; else return false; } string reverseOnlyLetters(string s) { int left=0,right=s.size()-1; while(left<right) { //是26位字母就不动,直接交换,如果不是就按要求加加减减 while(left<right && !isLetter(s[left])) ++left; while(left<right && !isLetter(s[right])) --right; swap(s[left],s[right]); ++left; --right; } return s; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
迭代器的写法
代码class Solution { public: bool isLetter(char ch) { if( ch >='a' && ch<='z') return true; else if(ch>='A' && ch<='Z') return true; else return false; } string reverseOnlyLetters(string s) { string::iterator leftit=s.begin(); string::iterator rightit=s.end()-1; while(leftit<rightit) { while(leftit<rightit && !isLetter(*leftit)) ++leftit; while(leftit<rightit && !isLetter(*rightit)) --rightit; swap(*leftit,*rightit); ++leftit; --rightit; } return s; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.迭代器
1.正向迭代器
这个很简单的就是前面讲遍历字符串的那个迭代器就是正向迭代器
代码void test3() { string s1("hello"); //迭代器 string::iterator it=s1.begin(); while (it != s1.end()) { cout << *it << " "; ++it; } cout << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.反向迭代器
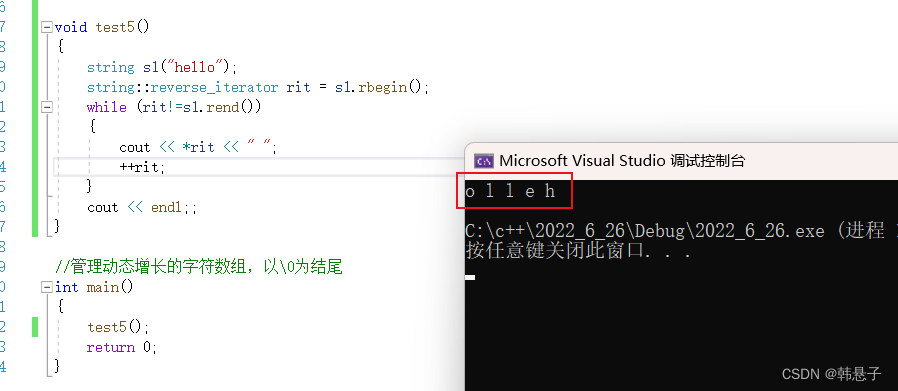
这个和名字相同,正向遍历是从前面遍历,那么反向遍历就是从后面开始遍历的
代码void test5() { string s1("hello"); string::reverse_iterator rit = s1.rbegin(); while (rit!=s1.rend()) { cout << *rit << " "; ++rit; } cout << endl;; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果
3.加了const的迭代器
代码
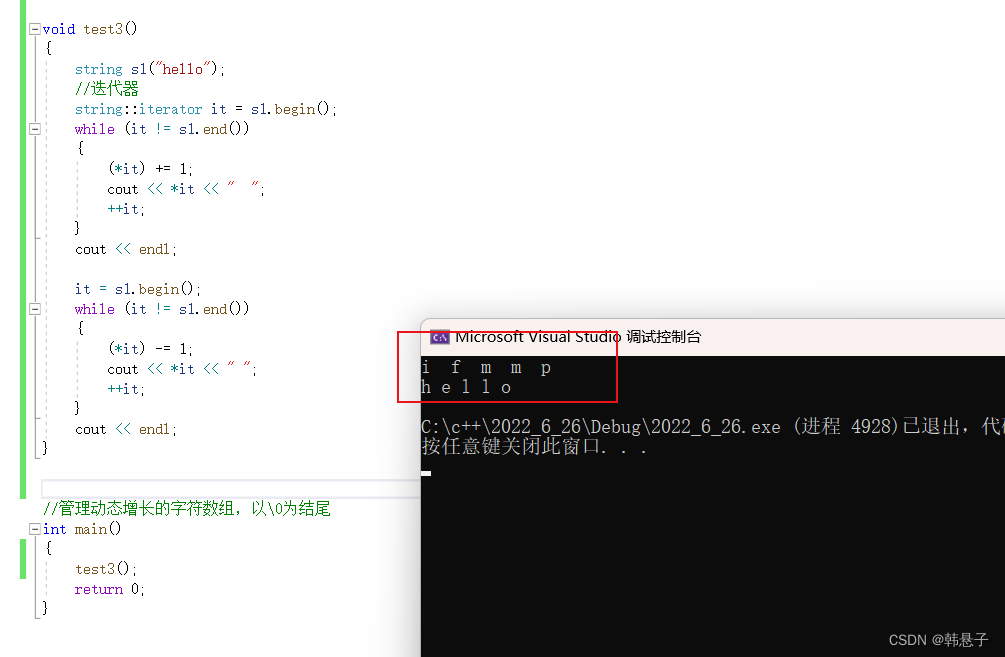
void test3() { string s1("hello"); //迭代器 string::iterator it = s1.begin(); while (it != s1.end()) { (*it) += 1; cout << *it << " "; ++it; } cout << endl; it = s1.begin(); while (it != s1.end()) { (*it) -= 1; cout << *it << " "; ++it; } cout << endl; } //管理动态增长的字符数组,以\0为结尾 int main() { test3(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
因为迭代器是像指针一样的东西或者就是指针,所以他可以可读可写
下面是运行结果,上面代码的意思是让hello每一位-1,然后通过加1来变回hello
所以这里正常的版本,有了这个版本也有const的版本了
const的版本就只能只能可读了,不能可写了
代码
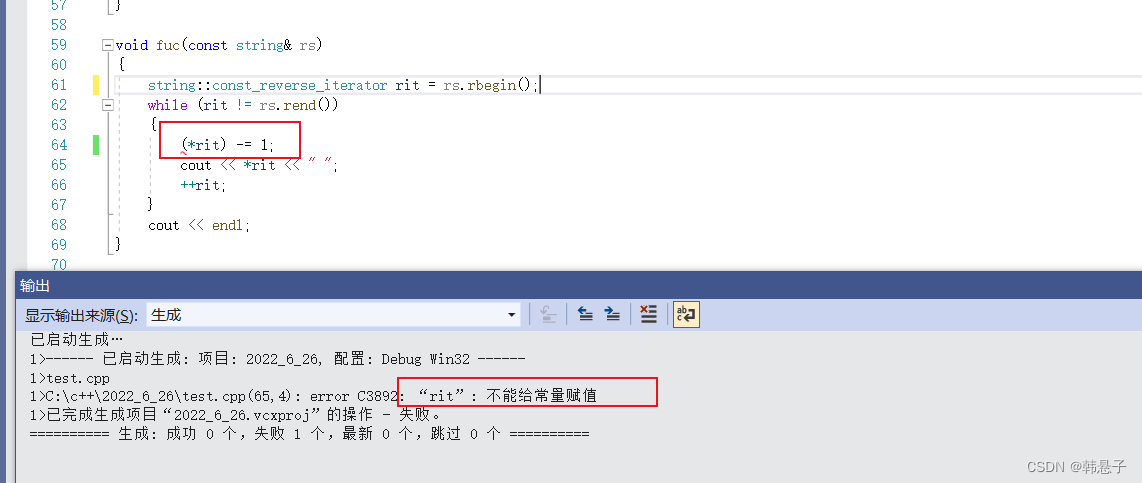
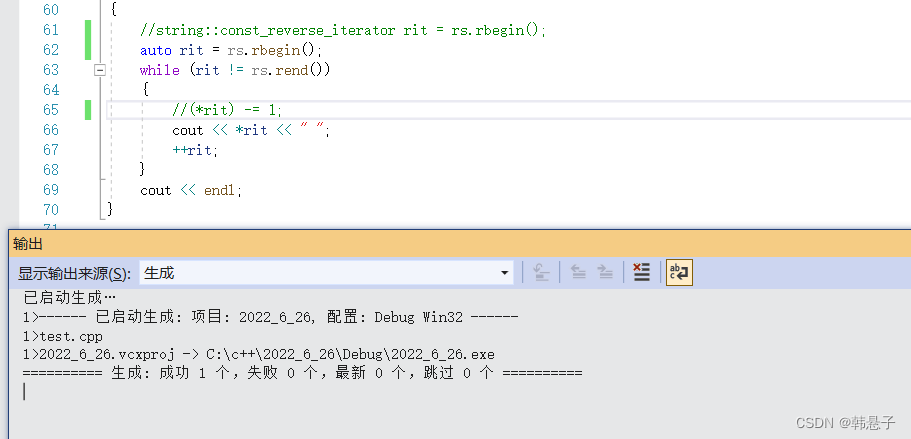
可以看到其实迭代器不只是二种其实是四种,正向迭代器,const正向迭代器,反向迭代器,const反向迭代器不过当然有人可能觉得迭代器太麻烦了要打那么多代码,这时候有个好办法
那就是auto
代码
-
相关阅读:
java SpringBoot登录验证token拦截器
【无标题】
MATLAB源码-第55期】matlab代码基于m序列的多用户跳频通信系统仿真,输出各节点波形图。
世界上第一台个人电脑是哪台?
呕血回顾一次提高接口并发的经历,很实用
2个比较经典的PHP加密解密函数分享
输入两个3位的正整数m,n,输出[m,n]区间内所有的“水仙花数”。所谓“水仙花数”是指一个3位数,其各位数字的立方和等于该数本身。
【Lua基础 第2章】lua遍历table的方式、运算符、math库、字符串操作方法
Android音视频开发:MediaRecorder录制音频
技术面试面面观
- 原文地址:https://blog.csdn.net/li1829146612/article/details/125475746
