-
杂谈:花样滑冰智能解析系统与基于骨骼点数据的串烧
数据来源
数据来源的两个分支:骨骼点数据和双流I3D数据
关于骨骼点数据,我们是通过调用OpenPose的API,直接导出的数据,对于每个人都能够提取 出25个骨骼点,这些骨骼点特征以三维的形式存储,组织形式是骨骼点的二维坐标,再加上该点的置信度,共同构成三维特征。
关于双流I3D特征,全称为双流膨胀3D卷积网络
粗粒度和细粒度
MCF-22数据集
适用范围:对于以动作为中心的动作任务,骨骼点数据或者说骨架数据,往往比RGB数据更为鲁棒、简洁。相对于RGB数据来说,骨骼点数据中并不包含场景的信息,如观众席、场地等,使得模型更加关注动作本身,指向性更强,数据集也更为简洁。从这个角度来看,骨骼点数据并不适合区分切番茄和切土豆这种与场景或道具相关联的任务,而更适合纯粹的关注于动作本身的任务,如花样滑冰、跳水等。
encoder-decoder架构,很容易导致细粒度语义的丢失
《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》2018
从这篇论文开始,图卷积方法被广泛应用于骨骼点任务,之后z,图卷积方法与Attention模块结合,以增强网络的灵活性而这些工作,为了获得更棒的鲁棒性,都选择构建全局的图拓扑结构。但是,对于细粒度动作而言,不同种类的动作可能具有相似的拓扑结构
对于花样滑冰任务来说,由于不同的花滑选手有不同的运动习惯,如落地位置等,相同选手的不同动作往往比不同选手的相同动作更为相似。
在另一些情况下,local joints的不同(个人理解是,细小的差异)在粗粒度的数据集上也会有明显区别。我们研究细粒度动作,通常对其划分为细粒度动作层次和粗粒度运动两方面来分析。
粗放的行动,通过全局的联合依赖来区分;
细粒度的运动之间差异的划分主要依靠局部分组的联合依赖来划分由此提出,空间焦点注意力机制,设计局部分组的联合依赖来主导优化。
具体思路是,
代表全局依赖的标准attention map可以理解为树的根节点
通过求每个joint做近似的分类,实现对每个动作节点解耦,以建立新的子节点
不同的叶子结点之间相互补充,通过加强局部的分组依赖性,引导模型关注不同的细粒度动作这篇文章提出了一个新颖的空间焦点注意力机制,通过树状的attention map来增强细粒度任务中多个互补的分组联合依赖性
空间焦点注意力机制:
全局的attention map可以以更低的计算复杂性和更高的灵活性、鲁棒性来捕获动态全局依赖性。
然而细粒度的动作更加依赖于局部分组的联合依赖性
只考虑局部依赖性而忽略全局依赖性是不理智的,因为完整的全局依赖性是确定动作潜在类别的关键,局部分组的依赖性可以帮助区分两个相近的细粒度动作。综上,我们采取在空间焦点注意力中加强局部依赖的方法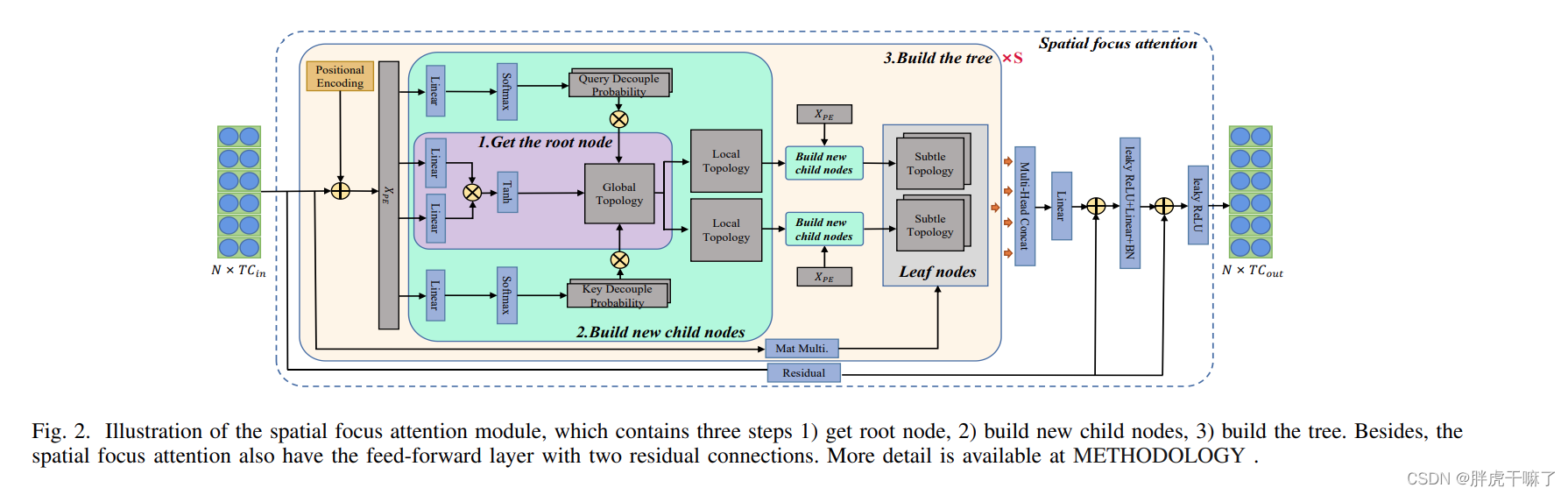
该模型分为三步,第一步为生成根节点
原始的attention map可以被认为是根节点,优点是易于划分,且能够提供良好的全局拓扑结构第二步为生成新的子节点
在解耦父节点的过程中,了解每个joint所相关的潜在类别是很重要的,相同潜在类别的节点的依赖性应该在局部拓扑结构中被增强。针对确定的一帧t,生成子节点的算法如下

解耦的过程,由于没有标签,更类似于聚类,唯一的规则就是子节点的数目。动态的全局拓扑可以分别解耦出许多局部拓扑结构。
为了帮助模型能够联合处理来自不同表征子空间的信息,设置了S个注意力头对数据进行处理。所有注意力头的处理结果被连接,map到输出空间
-
相关阅读:
steam搬砖,长期稳定副业,附防坑指南助你不掉坑
【leetcode】【2022/8/27】662. 二叉树最大宽度
CyclicBarrier和CountDownLatch的⽤法及区别?
java毕业设计健身房课程预约平台(附源码、数据库)
Spring源码-6.动态代理原理分析
[每日学习]算法学习1——数组二分
LeetCode.H76.最小覆盖子串
【继承之extends关键字和super关键字】
StringAOP统一问题处理
Qt安装使用
- 原文地址:https://blog.csdn.net/m0_53327618/article/details/125428247