-
Redis(7)----数据库与过期键
1,服务器中的数据库
Redis中相应的概念:
简单动态字符串
链表
字典
整数集合
压缩列表
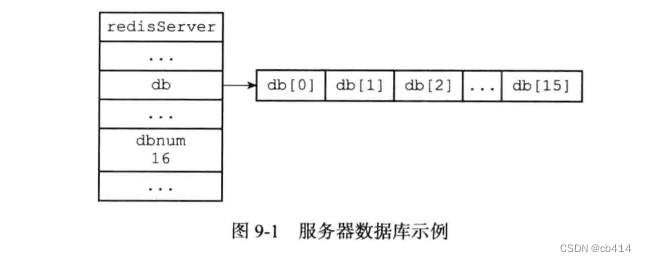
对象Redis服务器将所有数据库都保存在服务器状态:redisServer结构的db数组中,db数组中每个元素都是一个redisDb结构,每个结构代表一个数据库struct redisServer{ //... //一个数组,保存着服务中的所有数据库 redisDb *db; //服务器的数据库数量 int dbnum; //... };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
dbnum属性的值由服务器配置的database选项决定,默认下是16,所以默认情况下会创建16个数据库
2,切换数据库
每个
Redis客户端都有自己的目标数据库,每当在客户端编写命令或者数据库执行命令时,目标数据库就会成为这些命令的操作对象。默认情况下,客户端的目标数据库是0号数据库,可以通过SELECT命令切换数据库。redis> SET msg "hello world" OK redis> GET msg "hello world" redis> SELECT 2 OK redis[2]> GET msg (nil) # 因为2号数据库并没有 msg 这个键,msg是存在于0号数据库中 redis[2]> SET msg "another world" OK redis[2]> GET msg "another msg"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
客户端状态
redisClient结构的db属性记录了客户端当前的目标数据库,这个属性是一个指向redisDb结构的指针。typedef struct redisClent{ //... //记录客户端当前正在使用的数据库 redisDb *db; //... } redisClient;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
redisClient.db指针指向redisServer.db数组中的元素,该元素代表当前客户端正在使用的数据库例如当前客户端正在使用1号数据库,那么
redisClient和redisServer的关系示意图如下: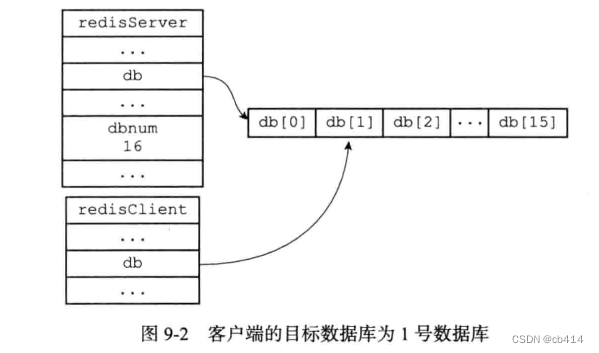
执行
SELECT 2之后: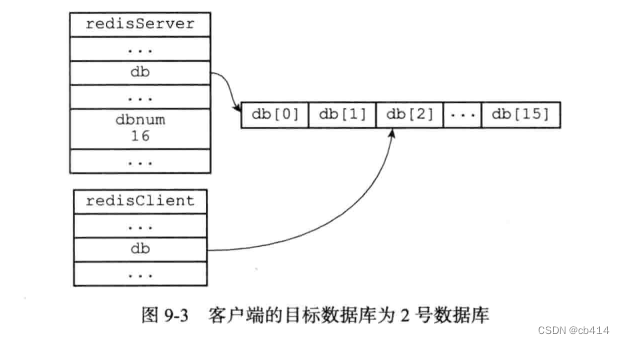
通过修改
redisClient.db指针,让它指向数组中的不同元素,从而实现切换目标数据库的功能,这就是SELECT命令的实现原理。3,数据库键空间
Redis是一个键值对服务器,每个数据库都由一个redisDb结构表示,其中redisDb结构的dict字典中的所有键值对,我们将其称为键空间(key space)typedef struct redisDb{ //... //数据库键空间,保存着数据库中的所有键值对 dict *dict; //... } redisDb;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键,每个键都是一个字符串对象
- 键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种
Redis对象
如果执行下面的命令:
redis> SET message "hello world" OK redis> RPUSH alphabet "a" "b" "c" (integer) 3 redis> HSET book name "Redis in Action" (integer) 1 redis> HSET book author "Josian L. Carlson" (integer) 1 redis> HSET book publisher "Manning" (integer) 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
执行过后,数据库的键空间会是这样的:【值得注意的是,这里的
StringObject代表字符串对象,HashObject代表哈希表对象,ListObject代表列表对象,这些均是为了简化表达方式】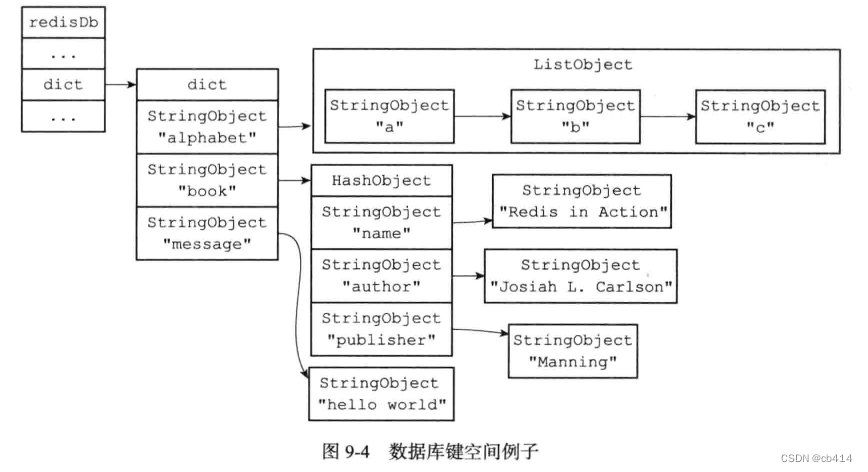
alphabet是一个列表键,键的名字是一个包含字符串alphabet的字符串对象,键的值则是一个包含三个元素的列表对象book是一个哈希表键,键的名字是一个包含字符串book的字符串对象,键的值是一个包含三个键值对的哈希表对象message是一个字符串键,键的名字是一个包含字符串message的字符串对象,键的值则是一个包含字符串hello world的字符串对象
因为数据库的键空间是一个字典,所以所有针对数据库的操作,实际上都是对这个键空间字典进行操作来实现的。
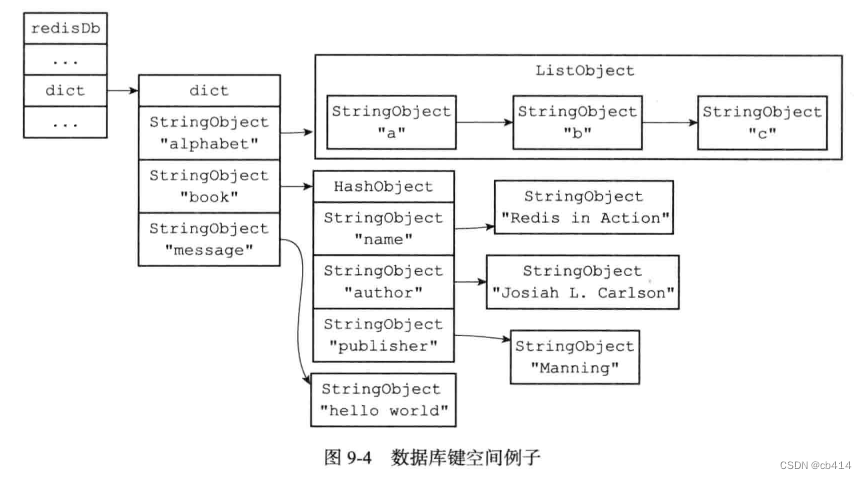
3.1,添加新键
添加一个新键,实际上就是将一个新的键值对添加到键空间字典中,其中键为字符串对象,而值则为任意一种类型的
Redis对象比如当前状况下的键空间示意图如下所示:
当往这个键空间添加一个新的键值对之后:
redis> SET date "2013.12.1" OK- 1
- 2
添加之后的示意图:
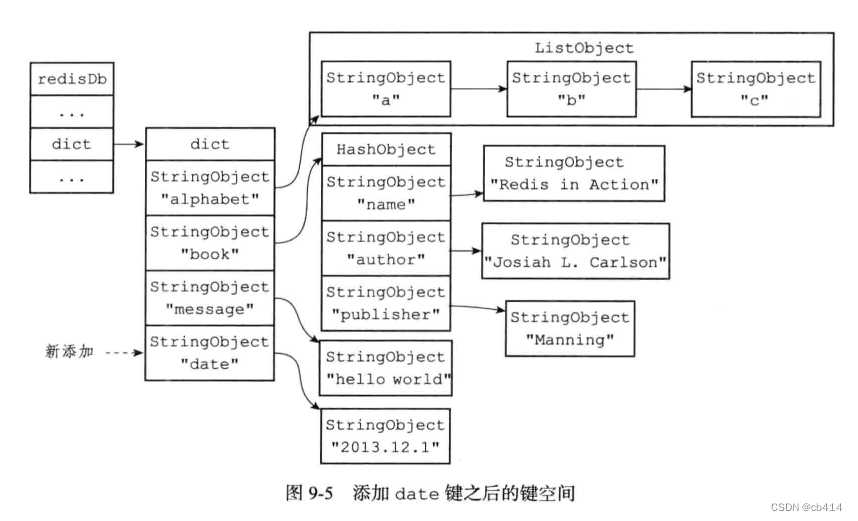
这个新的键值对的键是一个字符串对象,值是一个包含字符串“2013.12.1”的字符串对象
3.2,删除键
删除数据库的一个键,实际上就是在键空间里面删除键所对应的键值对对象。
假设键空间的状态如图9-4所示,执行以下命令:
redis> DEL book (integer) 1- 1
- 2
执行命令之后的键空间状态为:

3.3,更新键
对一个数据库键进行更新,实际上就是在键空间里对键所对应的值对象进行更新,根据值对象的类型不同,更新的具体方法也会不同
假设当前键空间的状态如图9-4所示,执行下面命令:
redis> SET message "blah blah" OK- 1
- 2
执行命令后,键空间状态应为:

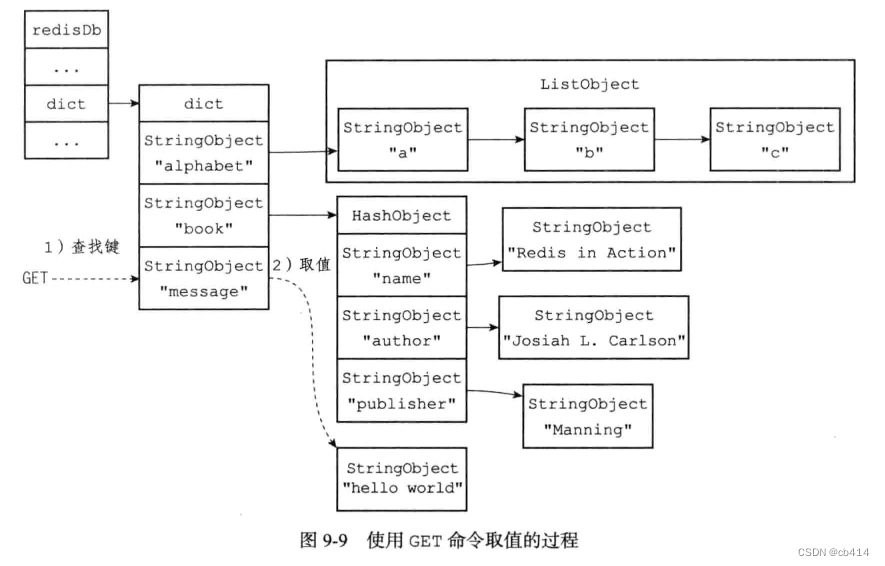
3.4,对键取值
对一个数据库键进行取值,实际上就是在键空间中取出键所对应的值对象,根据值对象的类型不同,具体的取值方法也会有所不同
假设当前键空间的状态如图9-4所示,执行执行下列命令:
redis> GET message "hello world"- 1
- 2
那么这个取值过程会是这样的:
3.5,读写键空间时的维护操作
在对键空间进行相应读写操作时,
Redis还会执行一些额外的维护操作,包括:- 在读取一个键之后(读操作和写操作都需要读取键),服务器会根据键是否存在来更新服务器的键空间命中(
hit)次数或键空间不命中(miss)次数 - 读取一个键之后,服务器会更新键的
LRU时间,这个值可以用于计算键的闲置时间 - 如果在读取时发现这个键已经过期,那么服务器会先删除这个过期键,然后才执行余下的其他操作
- 如果有客户端使用
WATCH命令监视某个键,那那么服务器在对这个键进行修改之后,会将这个键标记为脏(dirty),从而让事务程序注意到这个键已经被修改过了 - 服务器每次修改一个键之后,都会对脏键计数器的值增1,这个计数器会触发服务器的持久化以及复制操作
- 如果数据库开启数据库通知功能,那么在对键进行修改后,服务器将按配置发送相应的数据库通知
4,设置键的生存时间或过期时间
4.1,设置过期时间
Redis有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候被删除)EXPIRE <key> <ttl>:命令用于将键key的生存时间设置为ttl秒PEXPIRE <key> <ttl>:命令用于将键key的生存时间设置为ttl毫秒EXPIREAT <key> <timestamp>:命令用于将键key的过期时间设置为timestamp所指定的秒数时间戳PEXPIREAT <key> <timestamp>:命令用于将键key的过期时间设置为timestamp所指定的毫秒数时间戳
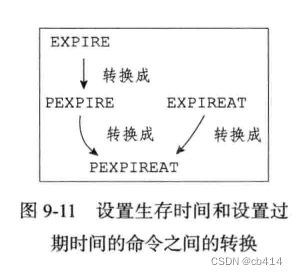
虽然有多种不同单位和不同形式的设置命令,但实际上
EXPIRE、PEXPIRE、EXPIREAT三个命令都是使用PEXPIREAT命令实现的# EXPIRE命令 def EXPIRE(key,ttl_in_sec): # 将TTL从秒转换成毫秒 ttl_in_ms=sec_to_ms(ttl_in_sec) PEXPIRE(key,ttl_in_ms) ###################################### # PEXPIRE又可以转换成PEXPIREAT def PEXPIRE(key,ttl_in_ms): # 获取以毫秒计算的当前UNIX时间戳 now_ms=get_current_unix_timestamp_in_ms() # 当前时间加上TTL,得出毫秒格式的键过期时间 PEXPIREAT(key,now_ms+ttl_in_ms) ###################################### # EXPIREAT命令可以转换成PEXPIREAT def EXPIREAT(key,expire_time_in_sec): # 将过期时间从秒转换为毫秒 expire_time_in_ms=sec_to_ms(expire_time_in_sec) PEXPIREAT(key,expire_time_in_ms)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.2,保存过期时间
redisDb结构的expires字典保存了数据库中的所有键的过期时间,我们称这个为过期字典- 过期字典的键是一个指针,指向键空间的某个键对象
- 过期字典的值是一个
long long类型的整数,这个整数保存了键所指向的数据库键的过期时间(一个毫秒精度的UNIX时间戳)
typedef struct redisDb{ //... //过期字典,保存着键的过期时间 dict *expires; //... }redisDb;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
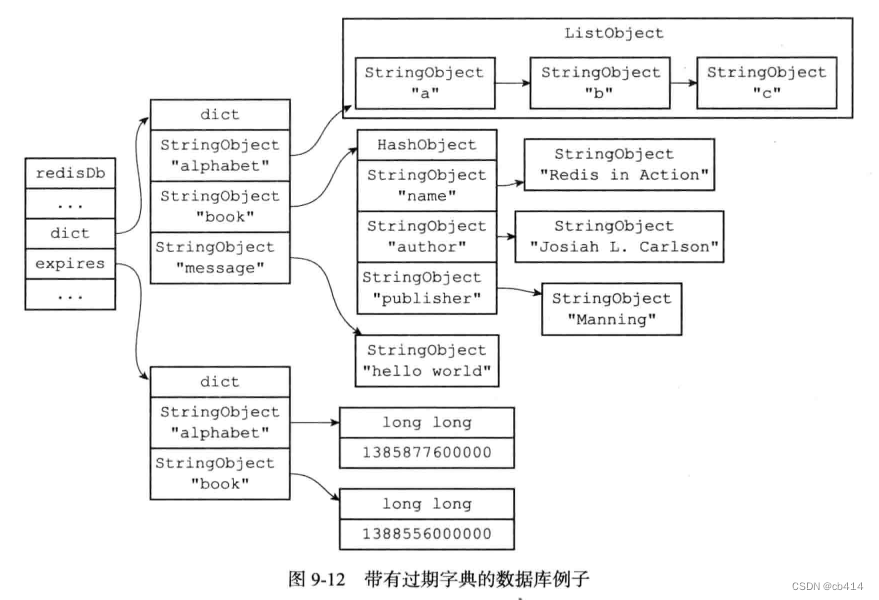
值得一提的是:过期字典中的键是指向键空间的键对象,图9-12这样表示是为了展示方便
前文提到的
PEXPIREAT命令的伪代码如下:def PEXPIREAT(key,expire_time_in_ms): # 如果给定的键不存在于键空间,那么不能设置过期时间 if key not in redisDb.dict: return 0 # 在过期字典中关联键和过期时间 redisDb.expires(key)=expire_time_in_ms # 过期时间设置成功 return 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.3,移除过期时间
PERSIST命令可以移除一个键的过期时间redis> PEXPIREAT message 1391234400000 (integer) 1 redis> TTL message (integer) 13893281 redis> PERSIST message (integer) 1 redis> TTL message (integer) -1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
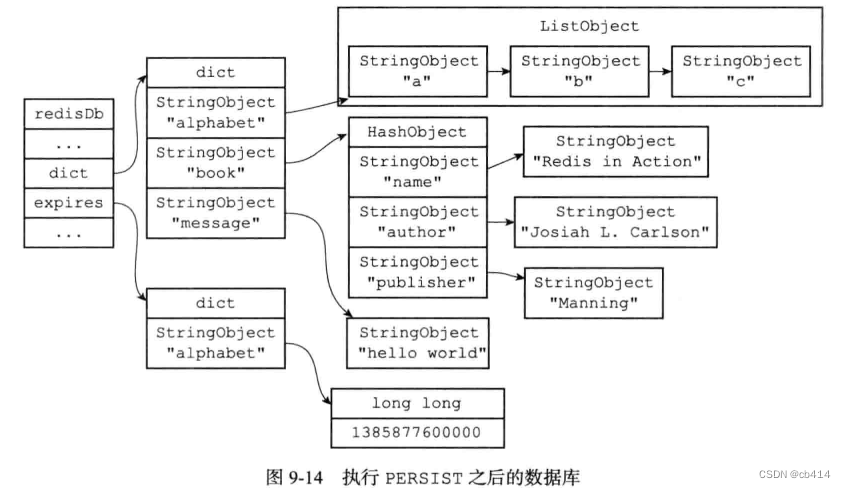
PERSIST命令就是PEXPIREAT的反操作:PERSIST命令会在过期字典中查找给定的键,并解除键和值在过期字典中的关联(也就是移除键的过期时间)假设数据库当前状态如图9-12所示,当执行下面的命令后:
redis> PERSIST book (integer) 1- 1
- 2
PERSIST命令的伪定义:def PERSIST(key): #如果键不存在,或者键没有设置过期时间,那么直接返回 if key not in redisDb.expires: return 0 #移除过期字典中给定键的键值对关联 redisDb.expires.remove(key) #键的过期时间移除成功 return 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.4,计算并返回剩余生存时间
TTL:以秒为单位返回键的剩余生存时间PTTL:以毫秒为单位返回键的剩余生存时间
PTTL伪代码
def PTTL(key): # 键不存在于数据库 if key not in redisDb.dict: return -2 # 尝试获取键的过期时间 # 如果键没有设置过期时间,那么expire_time_in_ms 将为none expire_time_in_ms=redisDb.expires.get(key) # 键没有设置过期时间 if expire_time_in_ms is None: return -1 # 获取当前时间 now_ms=get_current_unix_timestamp_in_ms() # 过期时间减去当前时间,得出的差就是键的剩余生存时间 return(expire_time_in_ms - now_ms)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
TTL伪代码
def TTL(key): #获取以毫秒为单位的剩余生存时间 ttl_in_ms=PTTL(key) if ttl_in_ms <0 : #处理返回值为-2和-1的情况 return ttl_in_ms else: #将毫秒转换为秒 return ms_to_sec(ttl_in_ms)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.5,过期键的判定
通过过期字典,程序用以下步骤检查一个键是否过期
- 检查给定键是否存在于过期字典,如果是,取得其过期时间(不存在过期字典代表没有设置过期时间)
- 检查当前
UNIX时间戳是否大于键的过期时间:如果是的话,那么键已经过期了;反之
4.6,过期键删除策略
如果一个键过期了,那么它什么时候会被删除呢?
这个问题有三种可能的答案,代表着三种不同的删除策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键过期时间来临时,立即执行对键的删除操作
- 惰性删除:每次从键空间获取键的时候,判断是否过期。如果过期就删除该键;反之
- 定期删除:每隔一段时间,数据库进行一次检查,删除里面的过期键,至于要删除多少过期键、检查多少数据库则由算法决定
定时删除
定时删除策略对内存非常友好:因为使用定时器,每当键过期了就会立马被删除。但如果存在了大量的过期键,程序需要花费一部分
CPU时间去删除这些过期键(可以理解为:删除过期键的动作会与主要任务抢夺CPU的执行时间);并且创建一个定时器需要使用Redis服务器中的时间事件,而当前时间事件的实现方式----无序链表,因为其查找时间复杂度为O(N),所以并不能高效的处理大量时间事件惰性删除
惰性删除策略对
CPU时间来说是非常友好的:只有当用到某个键的时候才会去判断这个键是否过期,过期就将删除;反之。并且删除的目标仅限于当前处理的键,并不会在其他无关的键上花费任何CPU时间。但缺点就是:如果数据库中存在大量过期键,但是这些过期键又恰好都没有被访问到,那么它们或许永远都不会被删除,这可以看成是一种内存泄漏(垃圾数据占用了大部分内存,但却删除不了)
定期删除
- 定时删除的缺点是:删除操作有可能占用太多
CPU时间,与任务执行抢夺时间,影响服务器的响应时间和吞吐量 - 惰性删除的缺点是:因为无法处理没有被访问的键,所以容易造成内存泄漏
定期删除策略是对定时删除和惰性删除的一种整合和折中
- 定期删除每隔一段时间执行一次删除过期键的操作,并且通过限制删除操作执行的时长和频率来减少删除操作对
CPU时间的影响。 - 并且通过这种定期删除,来减少因为过期键而导致的内存浪费
这种策略的关键在于:删除操作的时长和频率的确定。如果时间太长或者执行太频繁,那就会退化成定时删除策略;如果时间太短或者频率过低,容易造成大量过期键堆积,退化成惰性删除。
Redis服务器实际使用的是惰性删除和定期删除两种策略,通过两种策略配合使用,可以合理地在CPU时间和内存上取得平衡 -
相关阅读:
阿里面试官:给我描述一下缓存击穿的现象,并说说你的解决思路?
go语言中的结构体和组合思想入门示例
父子组件间的通信,插槽(slot)
【Linux】Centos 8 服务器部署:阿里云域名注册、域名解析、个人网站 ICP 备案详细教程
【大模型】2024大模型典型示范应用案例集——附219页PDF
ELMo模型、word2vec、独热编码(one-hot编码)的优缺点进行对比
SpringBoot 中使用布隆过滤器 Guava、Redission实现
typescript47-函数之间的类型兼容性
iPhone15线下购买,苹果零售店前门店排长队
【云原生与5G】微服务加持5G核心网
- 原文地址:https://blog.csdn.net/weixin_41043607/article/details/125538283
