-
【MindSpore论文精讲】AAAI长尾问题中训练技巧的总结

一、研究背景
近年来,基于元学习等各种复杂范式,长尾分布上的视觉识别取得了很大进展。而除了这些复杂方法外,对训练过程的简单调整对于性能提升也起到了不可忽视的作用。
这些调整虽然简单却很有效,如对数据分布或是损失函数权重的调整,但不同的技巧可能会相互冲突,如果使用不当,可能会导致识别准确度比预期更差。不幸的是,在现有文献中还没有关于这些技巧的科学指导。
二、作者介绍
魏秀参,博士,南京理工大学计算机科学与工程学院教授(PCA Lab骨干成员),南京大学学生创业导师。
主要研究领域为计算机视觉和机器学习,在相关领域国际顶级期刊和会议发表论文四十余篇,Google Scholar Citations 近2000次,相关研究成果获得含iNaturalist在内的计算机视觉领域国际权威赛事共4项世界冠军。
曾在CVPR、ICME等国际会议讲授“图像细粒度分析”为主题的短课程,著有《解析深度学习–卷积神经网络原理与视觉实践》一书。
曾获江苏省科协青年人才托举工程、南京经开区中青年优秀人才、南京理工大学青年拔尖人才、《中国科学:信息科学》优秀评审人、CVPR 2017 Best PC Member等荣誉。
任中国计算机学会高级会员、CCF计算机视觉专委会委员、中国图象图形学报青年编委。担任ICCV、IJCAI、ACM Multimedia、ACCV等国际会议Workshop程序委员会主席,ACCV 2022 Tutorial主席,IJCAI 2021高级程序委员,二十余次CCF-A类会议的程序委员,及IEEE TPAMI、TIP、TNNLS、MLJ、TMM等国际期刊审稿人。
三、论文主要内容简介
本文收集了已有的长尾视觉识别技巧,然后进行了广泛的系统性实验,给出了详细的实验指导,并获得了这些技巧的有效组合。
此外,本文还提出了一种基于类激活映射的长尾视觉数据增强方法,该方法能够与重采样技巧结合,并取得了良好的结果。通过科学地组合这些技巧,可以在4个长尾基准数据集上超越最先进的方法,包括ImageNet-LT和iNaturalist 2018。

四、链接
【论文链接】
https://ojs.aaai.org/index.php/
【代码链接】(点击“阅读原文”获取完整链接)
https://gitee.com/mindspore/con
五、算法框架技术要点
重加权法
成本敏感重加权法是长尾识别中常用的方法,这些方法通过对不同类别赋予不同的权重,引导网络更加关注少数类。本文比较了一个基线损失和4种重加权损失,分别为:
▶ Cross-entropy loss (CE)

▶ Cost-sensitive cross-entropy loss (CS_CE)

▶ Class-balanced cross-entropy loss (CB_CE)
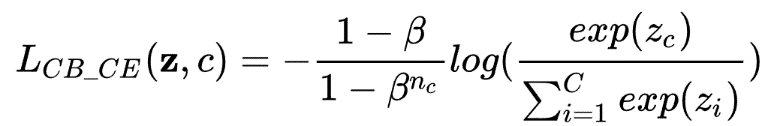
▶ Focal loss

▶ Class-balanced focal loss (CB_Focal)

重采样法
重采样法试图对数据重新抽样,以获得均匀分布的数据集。
▶ Random over-sampling
复制从少数类中随机取样的训练图像。这种方法在大部分场景下都是有效的,但可能会导致过拟合。
▶ Random under-sampling
随机删除头部类的训练图像直到所有类变得平衡。在某些情况下,欠采样比过采样更有效。
▶ Class-balanced sampling
每个类被选中的概率为:

其中q=0,即首先对每个类别均匀抽样,然后从所选类别中随机抽取一个样本。
▶ Square-root sampling
将上面公式中q设为0.5,构造出一个介于原分布与平衡分布之间的采样集。
▶ Progressively-balanced sampling
逐步将类的抽样概率从原来的不平衡分布转为平衡分布,类j的采样概率如下:

其中t为当前epoch数,T为总epoch数。
混淆训练
混淆训练可以看作是一种数据增强技巧,其目的是正则化卷积网络。我们发现混淆训练在长尾识别中具有良好效果,特别是与重采样相结合时。
▶ Input mixup
将两张原始输入图像在像素层面线性相加,合并后图片标签也由原标签线性相加。
▶ Manifold mixup (MM)
在网络某些层输出的特征图上做混淆,鼓励神经网络对隐藏表示的预测更加保守。
▶ Fine-tuning after mixup training
首先使用输入混合训练,然后对模型进行几个epoch的微调。
两阶段训练
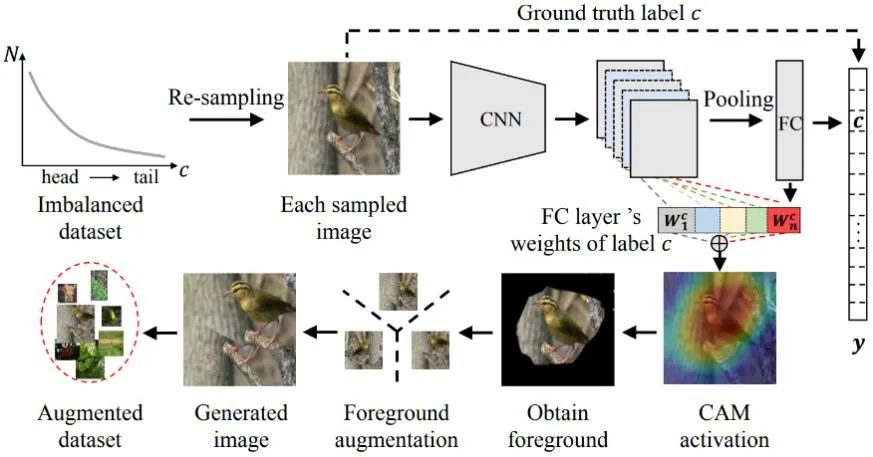
将训练过程分为不平衡训练和平衡微调两个阶段,本节重点探讨平衡微调的不同方法,并提出了基于CAM的采样方法。
▶ deferred re-balancing by resampling (DRS)
首先使用普通训练方法,然后在二阶段使用平衡采样进行微调。
▶ deferred re-balancing by re-weighting (DRW)
在二阶段使用重加权方法。
▶ CAM-Based Sampling (CAM-BS)
DRS中使用的重采样方法仅从原始数据集中复制或删除随机选择的样本以生成平衡子集,所以在平衡微调过程中改进有限。
为了生成判别信息,受类激活映射(class activation maps, CAM)的启发,我们提出了基于CAM的采样方法。
如下图所示,我们首先使用重采样来获得均衡的采样图像。对于每一幅采样的图像,我们使用第一训练阶段训练的参数化模型,根据其标签和对应的全连通层权值来生成CAM。根据CAM的平均值将前景和背景分离,前景包含大于平均值的像素,背景包含其余像素。
最后,我们在保持背景不变的情况下对前景应用转换。变换(由昇思MindSpore实现)包括水平翻转、平移、旋转和缩放,我们对每个图像随机选择一个变换。
六、实验结果
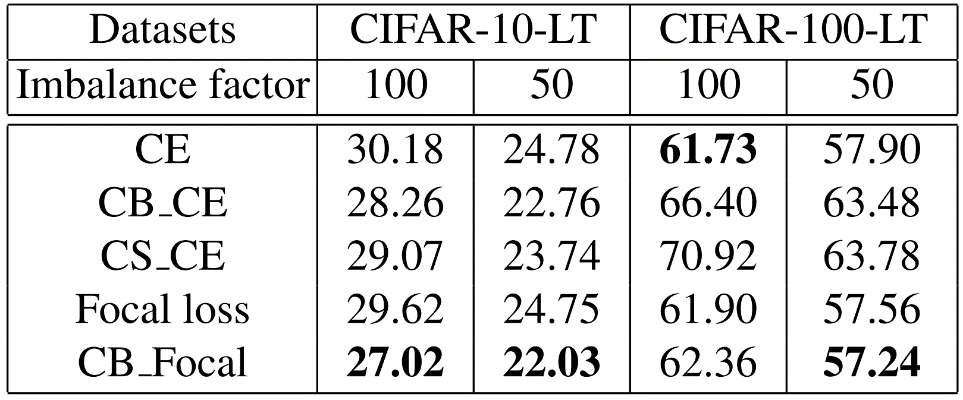
重加权法:5种方法的错误率如下表所示。结果表明单独使用重加权策略是不合适的,特别是当类的数量增加时。
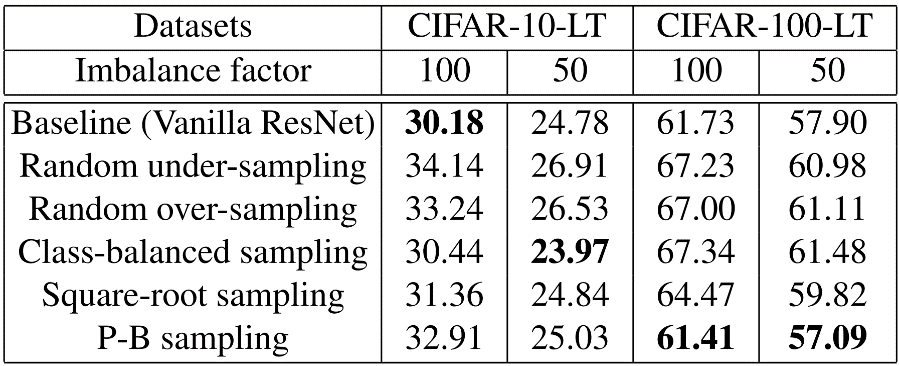
重采样法:不同重采样方法的错误率如下图。可以看到,单独使用重采样只能获得轻微改进。
混淆训练:结果如下表,“ft.“表示混淆训练后使用二阶段平衡微调。可以看到,输入混淆和MM相比是有竞争力的,MM中不同层的混淆对结果影响有限。输入混淆对于对于后续的微调更有帮助。


两阶段训练:下表为DRS中不同重采样方法的Top-1错误率。其中,基于cam的平衡采样得到了最好的结果。

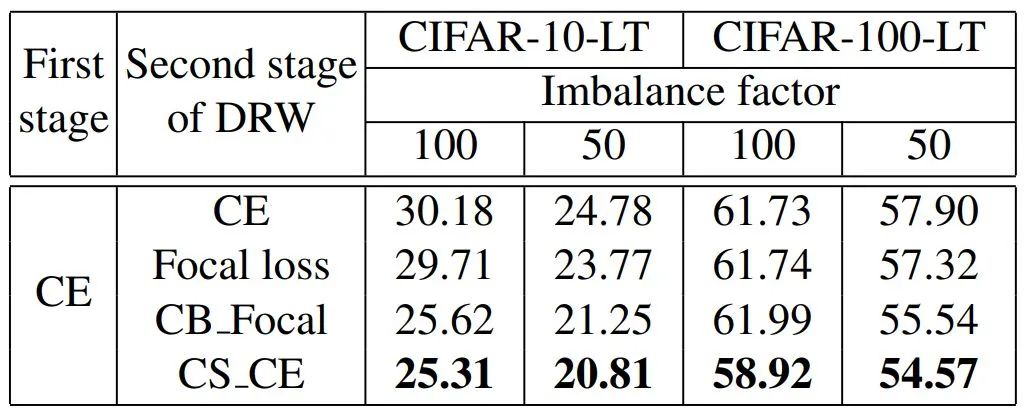
下表为DRW中不同重权方法的Top-1错误率。CS_CE在DRW训练计划中取得了最好的成绩。
下表为将混淆训练与其他最佳技巧相结合的TOP-1错误率。我们很容易发现输入混合比MM获得更大的增益。

下表为组合各个最优训练策略后的TOP-1错误率,随着训练技巧的增加,性能稳步提升,这证明了我们的方法在小型和大型真实世界的数据集上的有效性。
七、昇思MindSpore代码实现
- def construct(self, logit, label, **kwargs):
- """
- Args:
- inputs: prediction matrix (before softmax) with shape (batch_size, num_classes)
- label: ground truth labels with shape (batch_size)
- """
- logit_max = self.max(logit, -1)
- exp = self.exp(self.sub(logit, logit_max))
- exp_sum = self.sum(exp, -1)
- softmax_result = self.div(exp, exp_sum)
- label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
- softmax_result_log = self.log(softmax_result)
- loss = self.sum_cross_entropy((self.mul(softmax_result_log, label)), -1)
- loss = self.mul2(ops.scalar_to_array(-1.0), loss)
- if self.weight_list is not None:
- weight = self.mul3(self.squeeze(self.weight_list), label)
- weight = self.sum2(weight, -1)
- loss = self.mul3(loss, weight)
- loss = self.mean(loss, -1)
- return loss
通过细化算子粒度增强算法在多卡情况下的性能。
八、总结与展望
本文系统地探索了现有的简单有效的长尾识别方法,为长尾视觉识别提供了科学的训练指导。
此外,我们发现现有的简单抽样方法缺乏判别信息。基于此,我们提出了一种基于类激活映射的数据增强方法,并将其与现有的重采样方法相结合。
通过大量的实验,我们得到了最优的训练trick组合,在长尾基准测试上取得了最好的结果。我们还将源代码作为一个科学实用的工具箱发布,为长尾视觉识别的未来研究提供了有益的参考。
在未来,我们将尝试探索其他具有挑战性的长尾任务的trick包,例如检测和分割。
有任何问题可通过官方QQ群: 871543426,以获得第一时间解答。

MindSpore官方资料
官方QQ群 : 486831414
官网:https://www.mindspore.cn/
Gitee : https : //gitee.com/mindspore/mindspore
GitHub : https://github.com/mindspore-ai/mindspore
论坛:https://bbs.huaweicloud.com/forum/forum-1076-1.html
-
相关阅读:
Eclipse初步学习使用
最短编辑距离( 动态规划 + 线性dp )
类隔离(自定义类加载器实现)
Uniapp有奖猜歌游戏系统源码 带流量主
3.np.random
文艺复兴科技
easyphoto 妙鸭相机
PHP8的匿名类-PHP8知识详解
第1章丨IRIS SQL —— 简介
IRQ中断服务函数
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/125534202
