-
lnmp架构之mysql路由器、MHA高可用(三)
书接上文,我们接着来看主从复制的优化。
十、mysql路由器(读写分离)
在应用层到mysql集群之间加一个mysql路由器。mysql路由器是通过绑定不同端口来实现不一样的读写分离的策略。

再添加一台虚拟机,此主机用来做读写分离层:
首先下载mysql-router的rpm包 ,下载地址:MySQL :: Download MySQL Router (Archived Versions)

编辑mysql-router配置文件:
- # 读请求
- [routing:ro]
- bind_address = 0.0.0.0
- bind_port = 7001
- destinations = 172.25.254.1:3306,172.25.254.2:3306,172.25.254.3:3306
- routing_strategy = round-robin
- #写请求
- [routing:rw]
- bind_address = 0.0.0.0
- bind_port = 7002
- destinations = 172.25.254.1:3306,172.25.254.2:3306,172.25.254.3:3306
- routing_strategy = first-available #始终会发到第一台主机,如果第一台挂了,发到第二台


在其他任意一台mysql主机上授权用户:

在集群外的一台主机上远程访问server4的只读7001端口:

此时查看server3的3306端口,发现是server4和server3相连的,这说明server4就相当于一个代理,外部客户端通过读写分离层server4和server3相连:

由于只读7001端口我们设置的是round-robin轮询模式,所以我们退出再访问,就连接到mysql集群中其他节点上了。
接下来我们访问7002端口,由于我们设置的是server1先响应,所以肯定是server1相连:


此时我们将server1挂掉,再访问:


跟我们设置的一样,也是server1先响应,再是server2,再是server3。
十一、mysql主从的MHA高可用切换
MHA解决了mysql数据库单点故障,提高了数据的安全性。
MHA概念
MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。
MHA 的出现就是解决MySQL 单点的问题。
MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。
MHA能在故障切换的过程中最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA 的组成
MHA Node(数据节点)
MHA Node 运行在每台 MySQL 服务器上。
MHA Manager(管理节点)
MHA Manager 可以单独部署在一台独立的机器上,管理多个 master-slave 集群;也可以部署在一台 slave 节点上。
MHA Manager 会定时探测集群中的 master 节点。当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master, 然后将所有其他的 slave 重新指向新的 master。整个故障转移过程对应用程序完全透明。
MHA 的特点
- 自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失
- 使用半同步复制,可以大大降低数据丢失的风险,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性
- 目前MHA支持一主多从架构,最少三台服务,即一主两从
实验环境、安装包
主机 操作系统 IP地址 安装包 / 软件 / 工具 MHAmanager CentOS7-6 172.25.254.4 MHAnode组件、MHAmanager组件 master CentOS7-6 172.25.254.1 mysql-boost-5.7.20.tar.gz、MHAnode组件 slave1 CentOS7-6 172.25.254.2 mysql-boost-5.7.20.tar.gz、MHAnode组件 slave2 CentOS7-6 172.25.254.3 mysql-boost-5.7.20.tar.gz、MHAnode组件 在做这个实验之前我们要先把这个mysql集群转成一主两从的架构。我们把所有节点上的mysql服务关闭,并把/data/mysql 中的数据删除干净,重新设置初始化:
server1的/etc/my.cnf:

初始化数据库:
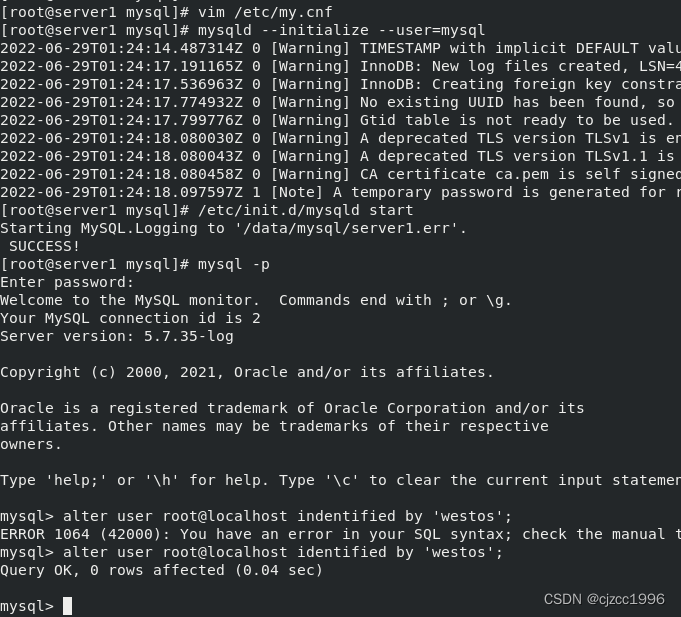
创建用户并授权,此时server1已经是master了:

server2:

server2 slave启动成功:

server3完全和server2一样的操作。由于我们在master上已经创建了repl用户,所以在其他slave端我们不需要再创建,因为所有节点的二进制日志都是同步的。
在刚刚实验的路由节点server4上,我们要下一个MHA的软件包(下载地址:mha官网:https://code.google.com/archive/p/mysql-master-ha/ github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads):
安装mha时会有需要的依赖性,如下图所示:

此时mha工作时要求管理节点必须可以免密访问所有的数据库节点,所以我们先做免密:


server2、3和server1一样。在三个数据库节点上要安装以下node-rpm:

Manager工具包主要包括以下几个工具:
- masterha_check_ssh //检查MHA的SSH配置状况
- masterha_check_repl //检查MySQL复制状况
- masterha_manger //启动MHA
- masterha_check_status //检测当前MHA运行状态
- masterha_master_monitor //检测master是否宕机
- masterha_master_switch //控制故障转移(自动或者手动)
- masterha_conf_host //添加或删除配置的server信息
Node工具包(由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
- save_binary_logs //保存和复制master的二进制日志
- apply_diff_relay_logs //识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog //去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs //清除中继日志(不会阻塞SQL线程)
在管理端server4编辑配置文件:
首先我们把源码包里的配置文件模板保存到我们刚刚新建的目录 /etc/mha 中:

为了方便,我们将两个文件合成一个文件:

编辑此文件:

指定备机时还有一个优化选项:
[server2]
hostname=172.25.254.2
port=3306
candidate_master=1 #指定failover时此slave会接管master,即使数据不是最新的。
check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master,即不管落后多少都死等
检查环境是否准备好需要两步:
1、masterha_check_ssh --conf=/etc/mha/app1.conf (检查免密)

出现错误 除了管理段和数据库节点之间是免密的,集群节点之间也必须是免密的。
解决:
我们将server4上的密钥复制给其他集群节点,由于密钥都是一对一对的,所以用同一套密钥即可。

测试一下是否能免密连接,若是不能,就重新ssh-copy-id 一下,重新拷贝到mysql节点上。此时再检测就没问题了:

2、 masterha_check_repl --conf=/etc/mha/app1.conf 检测数据库主从配置是否到位

上面错误的意思是从管理段server4无法远程访问集群节点的数据库。
解决: 登陆server1 master 的数据库,给root用户远程访问的权限,由于现在集群mysql都是同步的,所以我们只需要在master上操作就行了,其他节点会自动同步:

此时再执行脚本,检测成功:

手动切换:
当master还alive时:
- #当master还活着时
- masterha_master_switch --conf=/etc/mha/app1.conf --master_state=alive --new_master_host=172.25.254.2 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
执行命令成功(中途选项都选yes):

此时在server2上:

在server1上显示master已经变成server2:

当master挂掉了:

masterha_master_switch --master_state=dead --conf=/etc/mha/app1.conf --dead_master_host=172.25.254.2 --dead_master_port=3306 --new_master_host=172.25.254.1 --new_master_port=3306 --ignore_last_failover执行命令成功(中途选项都选yes):

切换过程中会生成一个锁定文件,下次切换时必需加上 --ignore_last_failover :

此时查看server1、3状态都已经切换成功了。但是由于server2停掉了,当server2重新启动起来时,要手动把master切到server1上:

自动切换:
自动切换只需要把程序打到后台即可。

测试:
将master server1停掉:

在管理端server4上:

自动检测到master挂掉,自动切换并退出后台监听程序。此时server2切换成master:

使用脚本文件进行切换:
在我们刚刚解压的源码包里,有一个自动切换和一个手动切换的脚本,我们可以通过修改这两个脚本模板来实现自己的目的:

此处的四个脚本分别对应于配置文件中的设置:

编辑配置文件:
将更改好的脚本放入指定文件,此脚本文件除了切换master之外,还实现了VIP的漂移:

测试:
首先,我们再master上加个VIP:

在外部访问VIP:

手动切换master:

此时的VIP已经漂移到server1上了:

在客户端有短暂的报错后就正常了:

自动切换master:

此时停掉server1 master:

master 自动切回到server2上,VIP也漂移到server2上:

客户端经过重连会重新连接上:

-
相关阅读:
【知识总结】金九银十offer拿到手软的前端面试题——Web篇
亚马逊云购买和配置苹果MacOs系统的云主机
Python数据容器
大数据生态安全框架的实现原理与最佳实践(下篇)
DSPE-PEG2K-MAL|磷脂聚乙二醇马来酰亚胺(DSPE-PEG-MAL)|二硬脂酰基磷脂酰乙醇胺 聚乙二醇 马来酰亚胺,齐岳生物
Jmeter系列(4) 线程属性详解
xss.pwnfunction.com靶机 Warmups
Maya vs Blender:制作3D动画首选哪一个?
什么是C语言中的命名空间?
目标检测——【Transformer】Accelerating DETR Convergence via Semantic-Aligned Matching
- 原文地址:https://blog.csdn.net/cjzcc1996/article/details/125516404