-
从分布式锁谈CAP
前言
微服务的流行,使得现在基本都是分布式开发,也就是同一份代码会在多台机器上部署运行,此时若多台机器需要同步访问同一个资源(同一时间只能有一个节点机器在运行同一段代码),就需要使用到分布式锁。然而做好一个分布式锁并不容易,要考虑的点非常多,建议架构能力一般的公司对于分布式锁还是使用现有的开源框架来做(例如Redis的Redisson、Zookeeper的Curator、etcd等等),如果需要基于Redis、ZK进行自研的话,建议阅读接下来讨论的几个要点。
AP与CP的选择
首先我觉得最重要的就是考虑分布式协议的CAP特性,因为这直接决定了分布式锁的强弱、性能的强弱。接下来看看AP、CP模型的分布式锁都将会有哪些表现。
CP模型
这里CP模型我选用了Zookeeper(Zab协议)做例子,其实Etcd的Raft算法也是一个道理。首先,Zab和Raft是如何保证CP模型呢?
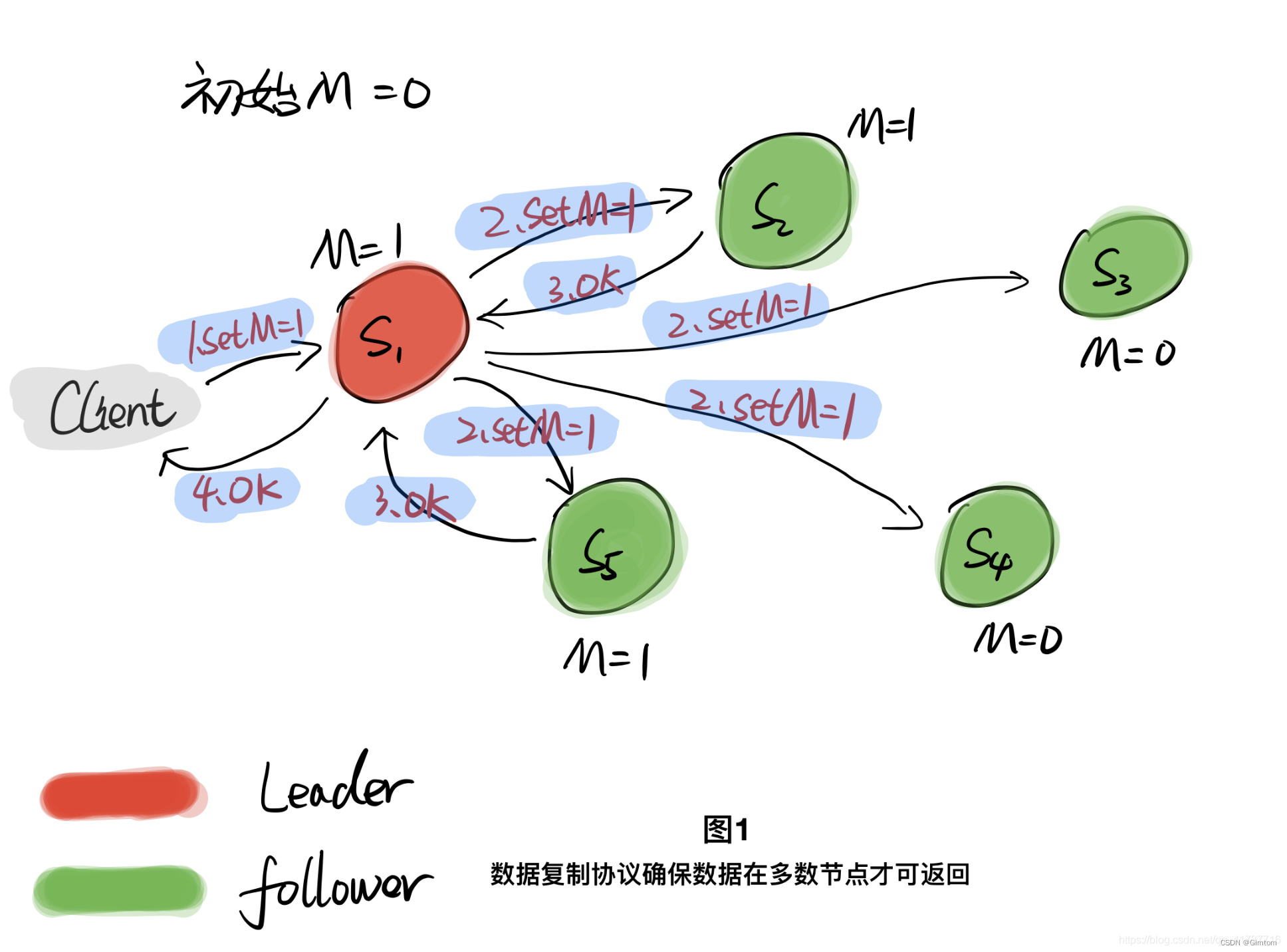
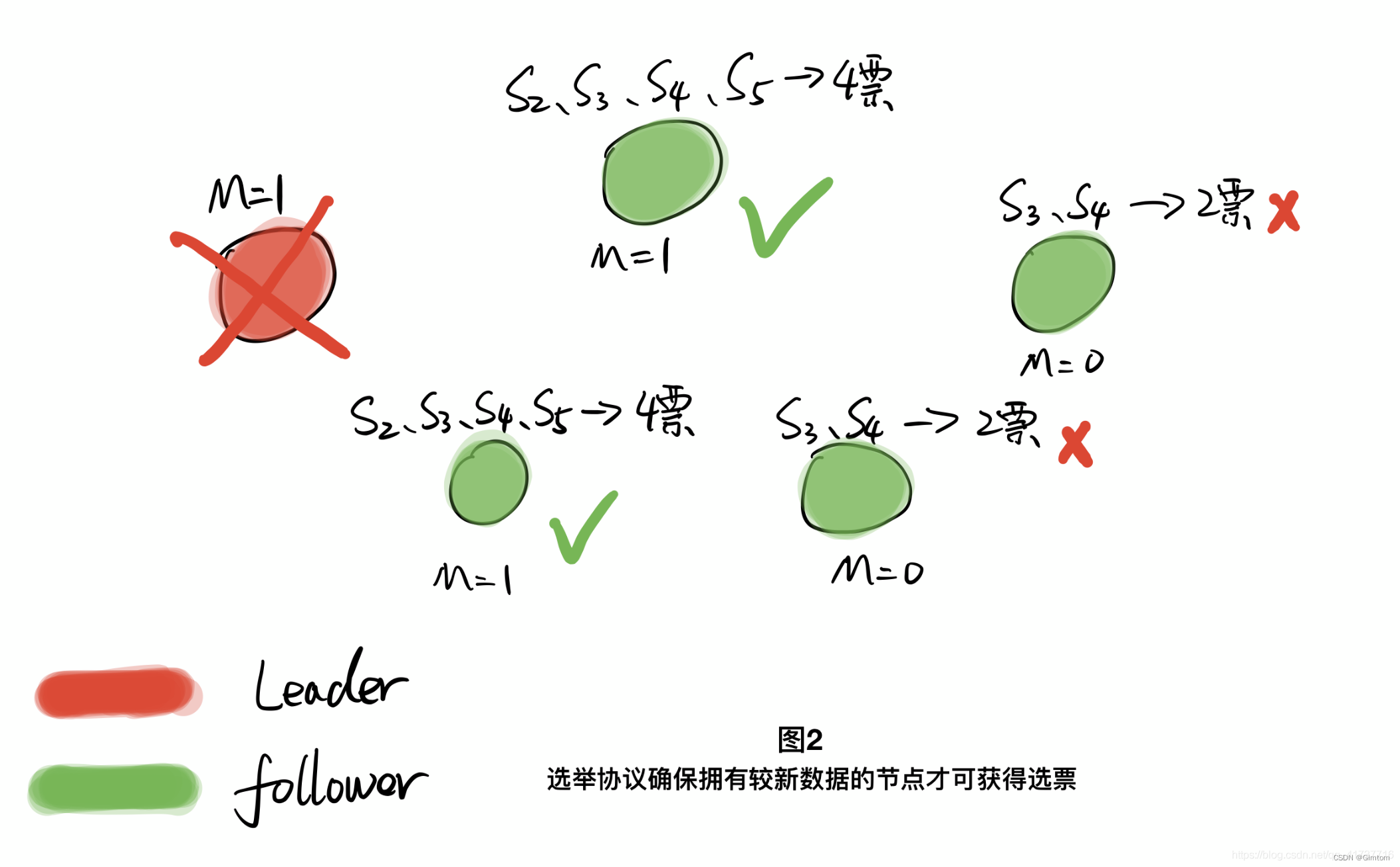
主要是由图1的数据复制规则+图2的选举主节点规则结合起来,使得set的数据在集群半数节点以上存活的时候一定不会丢,保证了数据一致性,但是如果集群半数以上节点宕机,集群将不对外服务,查询不到值,也是一种一致性的体现(不给总比给错误的值更好,至少在分布式锁场景下是这样,不加锁总比锁失效强吧)。CP模型存在的问题
从以上图1的数据复制规则来看,客户端要求set一个值的时候并没有立即返回,而是需要确保这个值在半数以上的节点上保存下来了才会返回给客户端成功响应,这样的话延时性就取决于最快的那半数节点的写入性能,而且还要加上网络通信来回的开销,在一定程度上延时性会弱一些,框架如果在高并发场景下可能会出现性能下滑(Zookeeper)的结果,这也就是为什么Zookeeper作为注册中心不被看好的原因,微服务链路调用都需要使用注册中心获取服务的IP地址,并发量可见一斑,但IP地址这种东西小概率存在不一致(服务刚上线,但注册中心没有这个服务的IP地址,使得不被访问到)其实是可以接受的,在注册中心的场景下延时性才最重要,这也就是为什么Nacos的注册中心会选用我们接下来要讨论的AP模型,他的延时性相对是要好的。
但是如果在不容许分布式锁失效且并发量、性能要求不是特别严格的场景下,这种CP模型是再合适不过了。
AP模型
这里AP模型我选用了Redis的主备集群(带哨兵)做例子。首先,为什么Redis的主备是AP模型?

从上图可以看出来,Redis的主备复制采用了异步增量复制(在新的节点启动时会全量+增量优化启动复制的时间,这里不讨论全量+增量模式),主Master节点设置值之后立刻就会返回给客户端OK信息,接下来异步地将增量复制值给传给slave从节点。
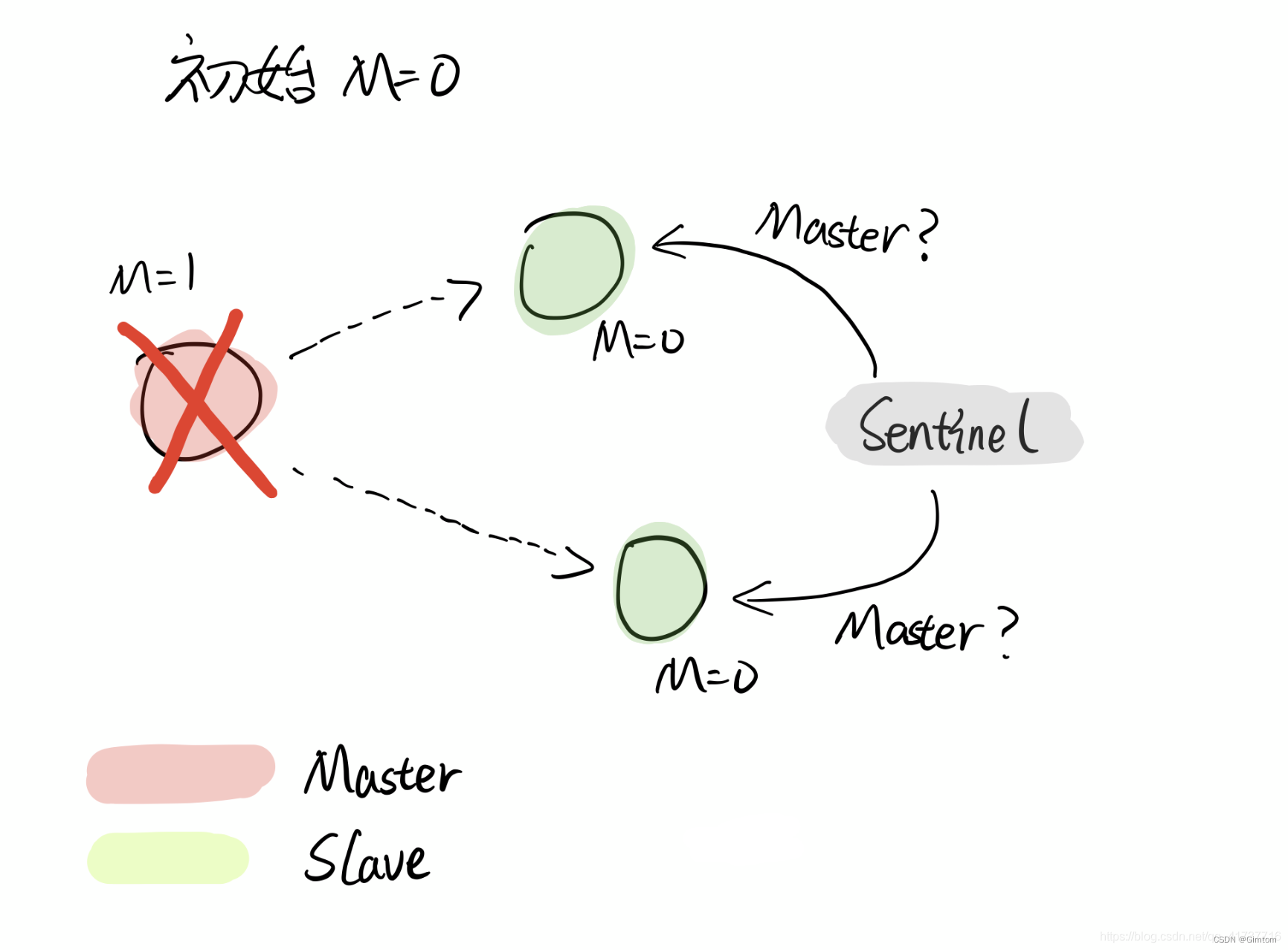
试想一下,若在第三步返回给客户端OK信息后主Master节点宕机了,数据没来得及复制给Slave从节点,此时Sentinel哨兵会选择一个从节点成为Master主节点,由上图可以看出,不管我们此时选择哪个节点做为Master,刚刚设置的值确实是丢失了,这里就造成了不一致(锁失效),这种主从集群架构会丢失或不一致主节点宕机的一段时间的数据。AP模型的好处
但这种模型有什么好处呢?又或者说Redis的主备设计成AP模型有什么考量呢?我们结合上面的CP模型来看,可以发现在接受事务请求(增删改数据)的时候,主Master节点只需要确保自己写入即可立即返回给客户端,复制的过程由于是异步的,客户端延时性上来说影响并不大,相比于CP模型的确保半数提交成功,AP模型的延时性是比较低的,Redis本身的定位就是要快,所以这相当符合Redis的设计初衷。再来看看可用性,如果集群有三个节点,它可以容许宕机两个节点,可以看出来,可用性的容错节点是N-1个,相比于CP模型它的可用性会更高,Redis的定位不就是缓存(快+高可用+数据丢失一部分可以接受)吗?
RedLock
那么有没有办法解决Redis主从集群模式下的不一致呢?这就是RedLock所做的事,其思想其实和CP模型一样,基于至少3个独立的Redis实例(官方推荐最好5个实例),获取锁的时候要分别访问3个Redis实例去获取锁,半数以上的Redis实例返回获取锁成功后才能算获取到锁(这不是和CP一样吗),保证了数据一致性,但是却带来了额外的延时性,要访问全部的3个Redis服务,至少等待其中半数以上返回成功,这里也存在网络开销,还带来了额外的后期运维复杂性(需要多个独立的Redis实例)。
笔者个人觉得,非要一致性强的场景,为什么不去用Zookeeper或是Etcd呢?在延时要求高、锁偶尔失效可以接受的场景下才会用Redis主从集群来构建分布式锁吧,RedLock为了保证一致性牺牲了速度,带来了额外的复杂度,在某种程度上得不偿失,还不如使用专门做这个的强一致性分布式协议做。
由于Redis作为分布式锁的话有可能会造成数据的不一致(锁失效),在分布式锁的场景下有可能会造成两个节点同时获取同一把锁,有可能你需要互斥访问的资源会在同一时间被执行两次,如果你使用分布式锁的场景是为了更好的利用系统资源(CPU和内存),让多节点不做一些重复的工作,并行互斥执行不同的任务,那么不妨将你的任务做成幂等的,这样就算两个节点做同一个任务,任务被执行了两次但是它们是幂等的,其结果也不会被影响,而且大部分时间上来看Redis的这把分布式锁确实能够更好的分配系统资源,让一些节点互斥并行起来。
总结
- 在延迟性要求高、客户端响应不能太慢、性能要求高的场景下,允许牺牲小部分时间的锁失效来换取好的性能,那么建议使用AP模型(例如Redis)来实现分布式锁,某些场景可以通过幂等弥补小部分锁失效带来的负面影响。
- 在延迟性要求不高、主要保证锁不能失效、高一致性的场景下,允许牺牲一点性能来换取一致性,那么建议使用CP模型(Zookeeper、Etcd)来实现分布式锁并发量极高的情况下可能有问题,选型时注意调研考虑考虑这点。
-
相关阅读:
A-Level物理例题解析及练习Phase Difference
井盖异动传感器丨井盖状态监测仪助力排水管网系统装上“眼睛”
小谈设计模式(27)—享元模式
智能指针基础知识【C++】【RAII思想 || unique_ptr || shared_ptr&weak_ptr || 循环引用问题】
Android 9.0系统源码_SystemUI(二)StatusBar系统状态栏的启动流程
VScode配置Ros环境
CSRF +self xss的运用【DVWA测试】
UI设计必备网站,一定要收藏。
AI智能分析视频监控系统如何助力智慧民宿规范化、安全最大化?
【Ubuntu】磁盘/系统空间占满导致黑屏死机无法开机的解决办法_unbuntu内存满了打不开
- 原文地址:https://blog.csdn.net/One_hundred_nice/article/details/125531272