-
中级C++:哈希
前言
- 以前的计数排序就是一种哈希结构,通过直接映射,或者间接映射;
- 通过对pair<K,V>中的K进行取模、直接定制法(一元一次方程:Hash(Key)= A*Key + B))、平方取中法、数学分析法、 随机数法、折叠法等等一系列方法,把K映射到一个vector数组上。
- 该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)。
哈希冲突
- 发现不同的K值,取模后,可能会用同一个下标(哈希地址),该种现象称为哈希冲突或哈希碰撞。
哈希冲突的解决
- 解决方案常见的两种方法:闭散列,开散列。
闭散列
- 也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。如果要查找某个元素,找到空也没有找到,说明不存在该元素。
- 空:用一个枚举类型,表示三种状态:存在、删除、空
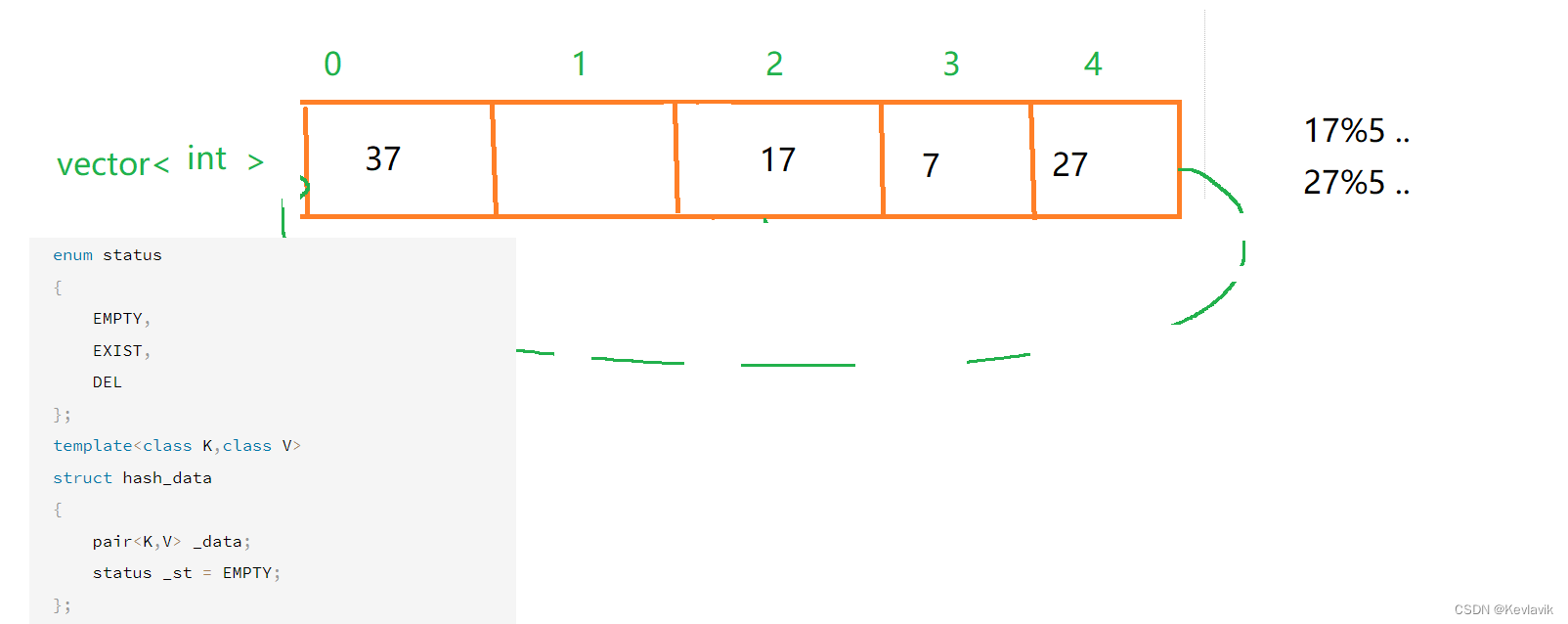
线性探测
-
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
- 如若走到头了,则和循环队列一样,%一个vector的长度可以回到下标 0 处。
- 我的位置被占了,我就去占别人的位置。。
-
负载因子:存放数据的个数,和数组的长度的比值;比值越低,说明冲突的可能性越小…应严格限制在0.7左右…
-
二次探测:找下一个空位置的方法进行了改进,让有相同哈希地址的分散一点,不要太集中。
-
闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
-
ntspt = start+i*2;
namespace close_hash { enum status { EMPTY, EXIST, DEL }; template<class K,class V> struct hash_data { pair<K,V> _data; status _st = EMPTY; }; --- template<class K, class V> class hash_table { typedef hash_data<K, V> hashdata; public: .... private: vector<hashdata> _ht; size_t _n= 0;//有效数据的个数 }; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
插入
bool Insert(const pair<K, V>& kv) { if (find(kv.first))//先看K值在不在数组里 { return false; } if (_n==_ht.size() || _n*10 /_ht.size()>=7) //看是不是空的或者负载因子大于7 越大,说明越冲突 { size_t newsize = _ht.size() == 0 ? 10 : _ht.size() * 2; hash_table<K,V> newht; newht._ht.resize(newsize); for (auto& i : _ht) { if (i._st == EXIST)//把是存在状态的数据插入到新数组里。 { newht.Insert(i._data); } } _ht.swap(newht._ht); } size_t start = kv.first % _ht.size(); //数组的下标 size_t i = 0; size_t inspt = start + i;//冲突了往后找空位置 while (_ht[inspt]._st == EXIST) { ++i; inspt = start + i; //intspt = start+i*2; inspt %= _ht.size(); } _ht[inspt]._data = kv; _ht[inspt]._st = EXIST; _n++; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
查找、删除
hashdata* find(const K& key) { if (_n==0) { return nullptr; } size_t findk = key%_ht.size();//找坐标 while (_ht[findk]._st != EMPTY) { if (_ht[findk]._st == EXIST && _ht[findk]._data.first == key) { return &_ht[findk]; } ++findk;//往后找 } return nullptr; } bool Erase(const K& key) { if (_n==0) { return true; } auto ret = find(key); if (ret) { ret->_st = DEL;//伪删除.. _n++; return true; } return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
测试用例
void test() { close_hash::hash_table<int, int> ht1; ht1.Insert(make_pair(10, 20)); ht1.Insert(make_pair(30, 20)); ht1.Insert(make_pair(24, 20)); ht1.Insert(make_pair(34, 20)); ht1.Insert(make_pair(44, 20)); ht1.Insert(make_pair(54, 20)); ht1.Insert(make_pair(64, 20)); ht1.Insert(make_pair(74, 20)); ht1.Erase(74); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
开散列
- 底层:单链表指针数组,就算有冲突了,就往那个坐标下面头插。Hash bucket,哈希桶。
- 一般开散列用的多。
- 这里直接写的哈希模板,T可以是key,也可以是key-value模型的。使用者传递获取K类型的仿函数。
- K值类型:string类型转int; 用于取模获取数组中哈希地址的仿函数。
- 开散列的负载因子到1再扩容。
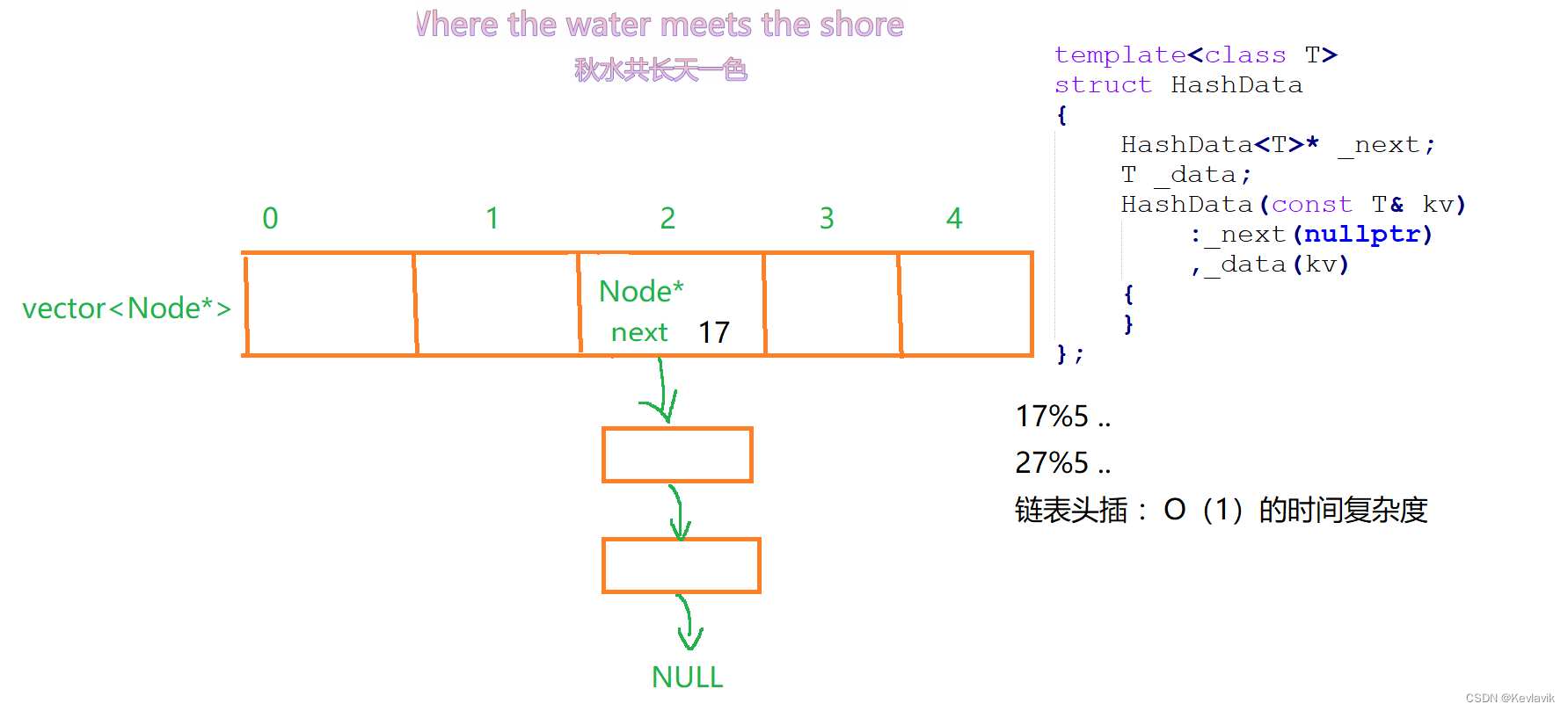
namespace myhash { template<class T> struct HashData { HashData<T>* _next; T _data; HashData(const T& kv) :_next(nullptr) ,_data(kv) { } }; //每次数组满了进行扩容的长度建议. size_t GetNextPrime(size_t prime) { const int PRIMECOUNT = 28; static const size_t primeList[PRIMECOUNT] = { 53ul, 97ul, 193ul, 389ul, 769ul, 1543ul, 3079ul, 6151ul, 12289ul, 24593ul, 49157ul, 98317ul, 196613ul, 393241ul, 786433ul, 1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul, 50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul, 1610612741ul, 3221225473ul, 4294967291ul }; size_t i = 0; for (; i < PRIMECOUNT; ++i) { if (primeList[i] > prime)//传过来原数组的长度 return primeList[i]; } return primeList[i]; } .....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
template<class K, class T,class HashFunc= HashFunc<K>, class KeyofT= KeyofT<K,T>> class HashTable { friend Hashiterator<K, T, HashFunc, KeyofT>; //友元 typedef HashData<T> Node; //单个数据类型 typedef Hashiterator<K, T, HashFunc, KeyofT> iterator; //迭代器 public: .. private: vector<Node*> _tabarry; size_t _n = 0;//存储的有效数据 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
析构
- 从哈希地址0开始,先找桶释放…
- vector再释放…
~HashTable() { for (size_t i = 0; i < _tabarry.size(); i++) { Node* cur = _tabarry[i]; while (cur) { Node* next = cur->_next; delete cur; cur = next; } _tabarry[i] = nullptr; } _n; cout << "最后还是调用我了呵呵呵" << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
仿函数
- 获取K的类型:pair<K,V>
- 内置类型,直接返回就行。
template<class K,class T> struct KeyofT { const K& operator()(const T& kv) { return kv.first; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- K值:string类型转 int
template<class K> struct HashFunc { size_t operator()(const K& key) //float double 等等支持隐式类型转换的都可以 { return key; } }; template<>//特化 struct HashFunc<string> { size_t operator()(const string& key) { // BKDR Hash思想 把字符串的每个字符乘上131. size_t hash = 0; for (size_t i = 0; i < key.size(); i++) { hash *= 131; hash += key[i];//这个字符串转换成一个整形了就.. } return hash; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
插入
- 扩容时:新建一个同类型的vector数组,找桶插入,置空,就不会泄露和野指针了。
bool Insert(const T& kv) { KeyofT kot;//获取K if (findk(kot(kv))) { return false; } HashFunc hf;//转整形 if (_tabarry.size()==_n) //负载因子等于1,满了进行扩容 { size_t newsize = GetNextPrime(_tabarry.size()); vector<Node*> newtabarry; newtabarry.resize(newsize,nullptr); for (size_t i = 0; i < _tabarry.size(); i++) { Node* cur = _tabarry[i]; while (cur) { Node* next = cur->_next; size_t index = hf(kot(cur->_data)) & newsize; cur->_next = newtabarry[index];//头插 newtabarry[index] = cur; cur = next; } _tabarry[i] = nullptr;//数组的每个元素置空。 } newtabarry.swap(_tabarry);// newarry 出了作用域自动析构...start,finsh,endof } size_t index = hf(kot(kv)) % _tabarry.size(); Node* cur = _tabarry[index]; while (cur) //单链表 { if (kot(cur->_data)==kot(kv)) //如果有存在的就返回 { return false; } else { cur = cur->_next; } } Node* newnode = new Node(kv); newnode->_next = _tabarry[index]; _tabarry[index] = newnode; ++_n; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
查找、删除
- 获取K值的哈希地址
Node* findk(const K& key) { HashFunc hf;//转整形 KeyofT kot;//获取K if (_n==_tabarry.size()) { return nullptr; } size_t index = hf(key) % _tabarry.size(); Node* cur = _tabarry[index]; while (cur) { if (kot(cur->_data)==key) { return cur; } cur = cur->_next; } return nullptr; } --- bool Erase(const K& key) { if (_tabarry.size()==0) { return false; } KeyofT kot; HashFunc hf; size_t del = hf(key) % _tabarry.size(); Node* cur = _tabarry[del]; Node* prev = nullptr; while (cur) { if (kot(cur->_data) == key) { //相等可能是头节点。也可能是中间 if (prev==nullptr) { _tabarry[del] = cur->_next; } else { prev->_next = cur->_next; } delete cur; --_n; return true; } else { prev = cur; cur = cur->_next; } } return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
迭代器
- 开散列的
iterator - 当前桶(一个坐标下面的链表)走完了,要走向下一个桶,所以需要一个哈希表类型
- 需要用到哈希表中的私有成员,将迭代器类设置成哈希表的友元。
- 一生之敌。。
template<class K, class T, class HashFunc, class KeyofT> class HashTable;//前置声明 template<class K, class T, class HashFunc = HashFunc<K>, class KeyofT = KeyofT<K, T>> struct Hashiterator { typedef HashData<T> HD; typedef HashTable<K, T, HashFunc, KeyofT> HT; typedef Hashiterator<K, T, HashFunc, KeyofT> Self; HD* _node; HT* _ht; Hashiterator(HD* node, HT* ht)//用一个数据类型的指针初始化,这里还需要哈希表 :_node(node) ,_ht(ht) { } Self& operator++() { KeyofT kot; HashFunc hf; size_t index = hf(kot(_node->_data)) % _ht->_tabarry.size(); HD* cur = _ht->_tabarry[index]; if (_node->_next) { _node = _node->_next; } else { ++index;//跳过当前桶 _node = nullptr; while (index < _ht->_tabarry.size())//小于数组的长度 { if (_ht->_tabarry[index]) { _node = _ht->_tabarry[index]; break; } else { ++index; } } if (index == _ht->_tabarry.size())//后面没桶了 { _node = nullptr; } } return *this; } bool operator!=(const Self& s) const { return _node != s._node; } T& operator*() { return _node->_data; } T* operator->() { return &_node->_data; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
iterator begin() //找第一个桶,构造迭代器 { for (size_t i = 0; i < _tabarry.size(); i++) { if (_tabarry[i]) { return iterator(_tabarry[i], this); } } return end(); } iterator end() { return iterator(nullptr, this); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
封装成 unordered_map 、unordered_set
- 底层是用的哈希表,和红黑树的封装类似。
- 需要自己写一个
keyofT来获取K的类型。 - 经典迭代器重载
[]在这里额
编者寄语
还是稳一点吧…
Come cheer up, my lads.Come cheer up, my lads.
振作起来吧,小伙子们.振作起来吧,小伙子们'Tis better to have loved and lost
纵然曾经爱过却落空 -
相关阅读:
Windows原理深入学习系列-Windows内核提权
TorchDrug教程--逆合成
招投标系统简介 企业电子招投标采购系统源码之电子招投标系统 —降低企业采购成本
Linux环境变量总结
实战SpringMVC之CRUD
文献学习-14-一种用于高精度微创手术的纤维机器人
【实现100个unity特效之12】Unity中的冲击波 ——如何使用ShaderGraph制作一个冲击波着色器
壹基金为爱同行到余村,以一步步健行换一滴滴净水
Linux 中的 chpasswd 命令及示例
Windows基本命令学习
- 原文地址:https://blog.csdn.net/WTFamer/article/details/125495517
