-
【NLP】预训练模型——GPT1
背景
废话不多说,先把三篇论文链接放出来:GPT1:Improving Language Understanding by Generative Pre-Training、GPT2:Language Models are Unsupervised Multitask Learners、GPT3:Language Models are Few-Shot Learners。李沐老师也在B站上放了介绍GPT模型的视频:GPT,GPT-2,GPT-3 论文精读【论文精读】.
首先我们理一下Transformer出现后一些语言模型出现的时间段:Transformer:2017/06,GPT1:2018/06,BERT:2018/10,GTP2:2019/02,GPT3:2020/05. 从模型出现的时间先后顺序来看,真是竞争激烈呀。
GPT1
我们知道在NLP领域中包含了很多任务,如问答,语义相似度,文本分类等。尽管大量的无标记文本语料库非常丰富,但用于学习这些特定任务的有标记数据却很少,那么在进行模型训练时就比较难了。GTP1这篇论文就是说,其通过在不同的无标签文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区别性微调,可以在这些任务上获得很好的效果。与以前的方法相比,GPT1在微调期间使用任务感知的输入转换,以实现有效的转换,同时对模型架构进行最小的更改。在这里我们可以想到word2vec,虽然其也是预训练模型,但是我们依然会根据任务类型去构造一个神经网络,而GPT1就不需要。GPT1在自然语言理解的广泛基准上的效果说明了这种方式的有效性。GTP1在通用任务不可知模型优于使用为每个任务专门制作的架构的区别训练模型,在研究的12个任务中有9个显著提高了技术水平。
在此之前,最成功的的预训练模型当然还是word2vec。文中提出了2个主要问题,1.如何在给定未标注的语料该选择什么样的损失函数呢?当然这时也会有一些任务如语言模型,机器翻译等,但是却没有一个损失函数在所有任务都表现的好;2.怎么把学到的文本表示 有效地传递到下游任务中?
GPT1的做法是在大量的无标签语料上使用半监督(semi-supervised)的方法学习一个语言模型,然后在下游任务进行微调。截止目前,语言模型中我们能够想到较好的就是RNN和Transformer相关的内容了。相比于RNN,Transformer学到的特征更加稳健,文中解释说,与循环网络等替代方案相比,这种模型选择为我们提供了更有结构的内存,用于处理文本中的长期依赖关系,从而在不同的任务中产生了健壮的传输性能(This model choice provides us with a more structured memory for handling long-term dependencies intext, compared to alternatives like recurrent networks, resulting in robust transfer performance acrossdiverse tasks. )以及在进行迁移的时候用的是一个任务相关的输入表示(During transfer, we utilize task-specific input adaptations derived from traversal-styleapproaches, which process structured text input as a single contiguous sequence of tokens)
模型结构
模型训练包括两个阶段。第一阶段是在大型语料库上学习高容量的语言模型。接下来是微调阶段,在此阶段,调整模型以适应带有标记数据的判别任务。
无监督的预训练
现有无监督语料数据 U = { u 1 , ⋯ , u n } {\mathcal U} = \{ u_1,\cdots,u_n \} U={u1,⋯,un},文中使用了一个标准的语言模型去最小化如下的似然函数:
L 1 ( U ) = ∑ ⋅ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_{1}(\mathcal{U})=\sum_{\cdot_{i}} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1(U)=⋅i∑logP(ui∣ui−k,…,ui−1;Θ)
其中 Θ \Theta Θ就是GPT1模型,然后就是用前 k k k个token去预测第 i i i个token的概率,也就是窗口大小,是一个超参数。那么从第0个位置开始到最后得到所有的结果加起来就得到了目标函数 L 1 L_1 L1,选择log函数也是为了避免概率相乘到最后值就没有了。换句话说就是使得模型能够最大概率化语料信息。文中使用的是多层的Transformer decoder。在Transformer的decoder由于掩码的存在提取特征的时候只能看到当前字符前面的内容,后面的内容在计算注意力机制时都是0.
在预测的过程中,加入给定上下文 U = ( u k , ⋯ , u − 1 ) U=(u_{_k},\cdots,u_{-1}) U=(uk,⋯,u−1)是上下文token的向量, n n n表示transformer decoder的层数, W e W_e We是token embedding矩阵, W p W_p Wp则是位置向量的embedding矩阵。那么预测上下文为 U U U的下一个词的过程如下:
h 0 = U W e + W p h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) , ∀ i ∈ [ 1 , n ] P ( u ) = s o f t m a x ( h n W e T ) h_0 = UW_e+W_p \\ h_l = transformer\_block(h_{l-1}),\forall { i\in[1, n]}\\ P(u)=softmax(h_nW_e^{T}) h0=UWe+Wphl=transformer_block(hl−1),∀i∈[1,n]P(u)=softmax(hnWeT)基于监督的微调(fine-tuning)
使用 L 1 L_1 L1目标函数公式训练出一个模型后,我们就可以用这个模型的参数去进行supervised的任务了。这个训练后的模型就是我们所说的预训练模型。假设我们有标记的语料 C C C,每一个样本是一段序列 x 1 , ⋯ , x m x^1,\cdots,x^m x1,⋯,xm,其对应的标签是 y y y。输入数据经过我们的预训练模型之后就得到一个 h l m h_l^m hlm。这个 h l m h_l^m hlm就是根据任务增加的一个线性输出层的输入,预测结果为 y y y。如下公式:
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right) P(y∣x1,…,xm)=softmax(hlmWy)
微调模型的损失函数如下:
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , … , x m ) L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right) L2(C)=(x,y)∑logP(y∣x1,…,xm)
论文中还说,如果加入给你一个序列预测序列的下一个词的损失,即 L 1 L_1 L1,加入到损失函数中,效果会更好,即有了如下损失函数:
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda * L_{1}(\mathcal{C}) L3(C)=L2(C)+λ∗L1(C)
其中 λ \lambda λ是一个超参数。总的来说,在微调人中只需要额外的参数 W y W_y Wy。那么如何将NLP中任务输入使用预训练模型表示和处理呢?先看一下这个图:
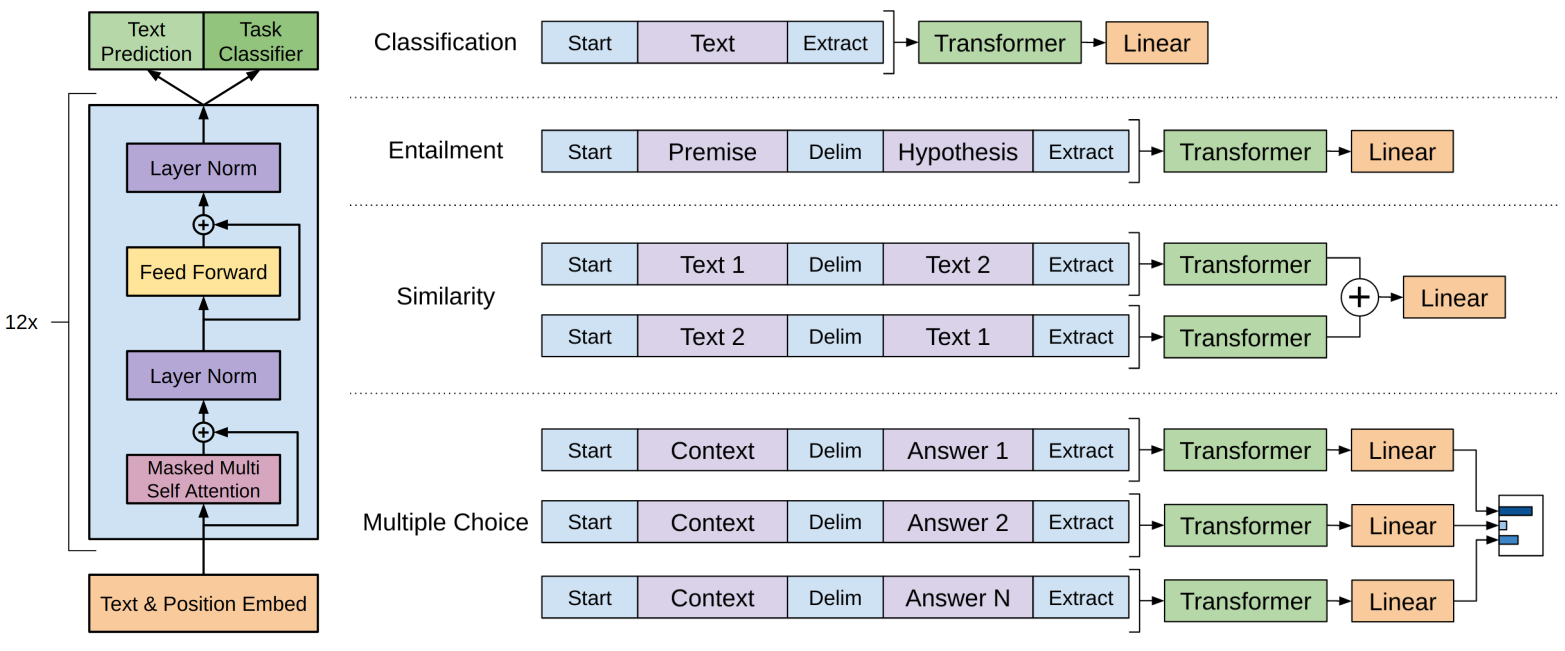
以文本分类任务为例,为文本的收尾添加指定的delimiter,然后送入到Transformer,紧接着一个Linear即可。第二个任务就是Entailment(蕴含),也就是之前我们介绍的NIU任务。其他的任务则是按照上面的图形进行拼接就行了。总的来说,通过构造不同类型的预训练模型的输入,去完成多项NLP任务,预训练模型本身是不会变的。
-
相关阅读:
Elastic实战:canal自定义客户端,实现mysql多表同步到es
【数据结构-树】哈夫曼树及其应用
Java WebSocket 获取客户端 IP 地址
负载均衡四层和七层的区别
字符串匹配值Sunday算法
Mybatisplus真实高效批量插入附容错机制
npm 命令
在spring boot中调用第三方接口时重试问题
机器学习笔记之最优化理论与方法(六)无约束优化问题——最优性条件
时序预测 | Matlab实现CNN-XGBoost卷积神经网络结合极限梯度提升树时间序列预测
- 原文地址:https://blog.csdn.net/meiqi0538/article/details/125475958