-
WebAssembly中simd使用调研
背景
目前对WebAssembly的使用主要是做计算密集型的工作,比如软解播放通过WebAssembly计算提供解码能力,WebAssembly执行完全依赖CPU计算,不能借助GPU硬件加速,所以需要尽量挖掘CPU执行提升程序效率的手段。目前两个主要优化手段为多线程和SIMD。
对于多线程能力的使用,从WebAssembly指令支持层面、编译工具链、线程间内存共享方式、浏览器对WASM标准的实现方面都有相应的支持
而SIMD是另一种能显著提升程序执行效率的方式,需要调研下使用到SIMD特性的源代码编译成WASM的可行性
技术原理
SIMD概念
-
SIMD(单指令多数据流)即一条指令可以一次处理多个数据,属于数据级并行优化手段。非常适用于对大量数据进行相同操作的计算任务,例如图片、音视频编解码处理场景。SIMD在X86、ARM CPU架构下都有相应的指令集实现。
-
-
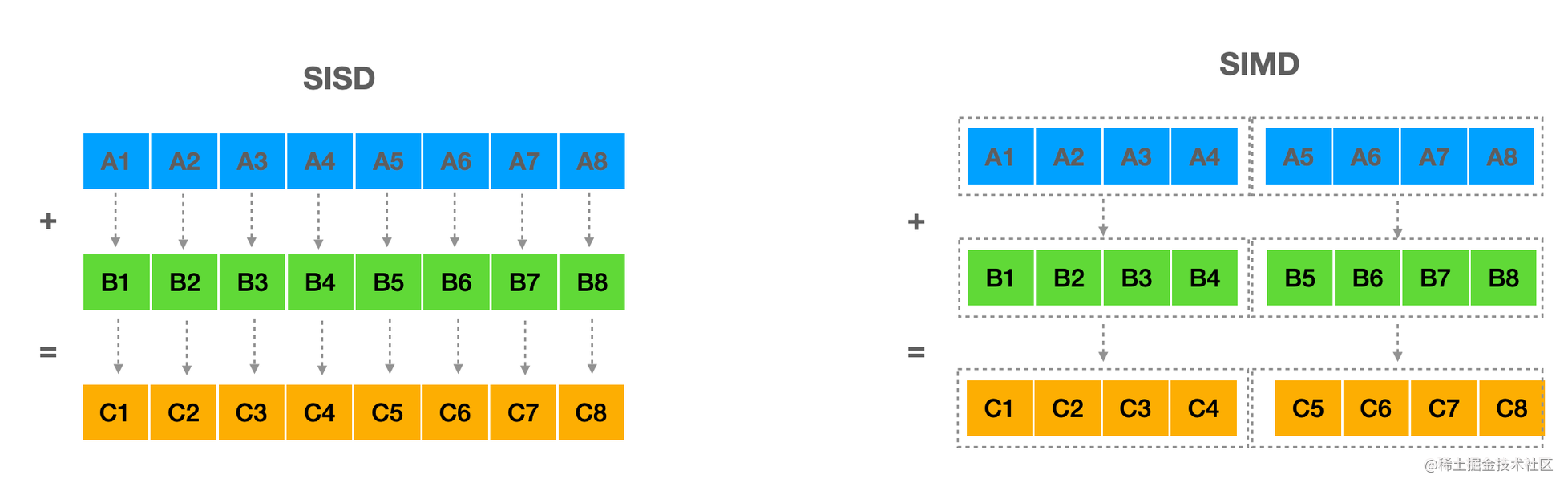
如图所示,从宏观的角度看SISD(单指令单数据流)和SIMD(单指令多数据流),对数组A、B中对应下标位置的数据进行相加,结果存到数组C中。对于SISD,N次循环操作,每次对一对数据进行处理。对于SIMD,一次操作可以同时处理四对数据,只需要 N/4次循环。两者的主要区别是单次指令执行处理的数据容量不同。
-
-
组成原理基础
-
在继续介绍之前需要先补充一些计算机组成原理的知识。- 1
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sU393gDG-1656511217139)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/5497bab8bd084a6d8e3c83bd894df0e6~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
-
CPU的基本任务就是执行指令,有三个主要部件,CU(控制单元) 、 ALU(算术逻辑单元)、寄存器(存储单元)- 1
-
**控制单元**- 1
-
由指令寄存器(Instruction Register)、指令计数器(Program Counter)、指令译码器(Instruction Decoder)和 操作控制器(Operation Controller) 等组成。对指令进行读取解析,控制执行。指令计数器中存放下一条指令在内存中的地址,控制单元根据地址读取指令,放入指令寄存器中,通过指令译码器对指令分析,确定应该进行什么操作,然后通过操作控制器生成控制信号,告诉运算逻辑单元(ALU)和寄存器如何运算、对什么数据进行运算以及对结果进行怎样的处理。- 1
-

-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wz3pkgVm-1656511217140)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/029c4fdb42eb4386a894c96035abb889~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
-
**算术逻辑单元**- 1
-
-
执行+ - \* / 等算术运算,位移等逻辑运算。由控制单元发出的控制电信号控制运算- 1
-
-
**寄存器**- 1
-
-
CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果以及一些CPU运行需要的信息。主要包括通用寄存器、专用寄存器。每个寄存器都有一个特定编号- 1
-
-
-
通用寄存器: 最基础的寄存器,程序执行过程中,绝大部分时间都是在操作这些寄存器来实现指令功能,从内存中读数据至寄存器,ALU运算临时结果存至寄存器等- 1
-
-
专用寄存器: 指令寄存器、SIMD指令专用的128bit,256bit寄存器等- 1
-
CPU单个指令执行一个特定操作,所有指令的集合代表了CPU的处理能力。从功能上分,指令主要分数据传输指令(读写)、算术运算指令(+ - \* / 等)、比较指令(> <)、逻辑运算指令(& | !)等- 1
-
高级语言代码编译成指令的合集由CPU来执行,对于存储在内存中的数据,没有数据类型的概念,全都是0101bit序列,例如连续的四个字节可能表示一个int数据,也可能表示float类型数据。对数据类型的区分是通过指令完成的。- 1
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTJ3kXN9-1656511217140)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/5693d4e0087246be8cc8a7b7b026abf8~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
-
[c9x.me/x86/](https://link.juejin.cn/?target=https%3A%2F%2Fc9x.me%2Fx86%2F "https://c9x.me/x86/")- 1
-
对不同数据类型进行相同的操作在所使用的指令上是有区分的。以X86指令为例,同样是加法指令,对整数进行运算使用ADD指令,对float数据进行运算使用ADDSS。在编译器对源代码进行编译时,根据我们的不同类型数据声明选择不同的指令。- 1
-

-
标量指令vs向量指令
-
在SIMD出现之前,cpu基本指令集支持的操作只能处理单个数据(单指令单数据流),属于标量指令,所处理的数据属于标量数据类型。以c语言为例,c语言中支持 char、short int、int、long、long long 、float、double数据类型,在x86\_64位CPU上所占的内存空间从1字节到8字节不等。作用于不同数据类型操作的代码编译成机器码后,会选择如上图 ADD、ADDSD、ADDSS、MOVSD、MOVSS等标量指令进行操作- 1
-
SIMD扩展指令属于向量指令。SIMD在 x86、arm cpu架构下都有相应的指令集实现。- 1
-
x86: SSE指令(一次处理128bit数据)、AVX(一次处理256bit数据)、AVX-512(一次处理512bit数据),相应的128bit寄存器、256bit寄存器、512bit寄存器- 1
-
arm: NEON指令(一次处理128bit数据),相应的128bit寄存器- 1
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3coEC4sL-1656511217140)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/e32eb420fb424e0aafb7c8bf7ce1b383~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
-
以SSE指令为例,一个[MOVAPS](https://link.juejin.cn/?target=https%3A%2F%2Fc9x.me%2Fx86%2Fhtml%2Ffile_module_x86_id_180.html "https://c9x.me/x86/html/file_module_x86_id_180.html")指令一次从内存中读取连续的128bit数据,并把这些数据看作4个连续的float类型标量数据。[ADDPS](https://link.juejin.cn/?target=https%3A%2F%2Fmudongliang.github.io%2Fx86%2Fhtml%2Ffile_module_x86_id_7.html "https://mudongliang.github.io/x86/html/file_module_x86_id_7.html")指令可以把两个128bit寄存器中数据当做4个float数据并且分别执行加法运算。- 1
-

-
SIMD编程
CPU提供了SIMD指令集,如何借助这些指令进行编程来提升程序执行效率?第一步需要向量数据类型定义。
还是以SSE指令为例,一次操作128bit数据,可以看做2xdouble、4xfloat、4xint、2xlong long。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3XcCsNZ-1656511217141)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/7bc8353eb7b344c986653a6ff7c109a8~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
typedef int v4si __attribute__ ((vector_size (16))); typedef unsigned int __v4su __attribute__((__vector_size__(16))); typedef float __m128 __attribute__((__vector_size__(16), __aligned__(16))); typedef double __m128d __attribute__((__vector_size__(16), __aligned__(16))); typedef long long __m128i __attribute__((__vector_size__(16), __aligned__(16)));- 1
- 2
- 3
- 4
- 5
通过以上形式定义向量数据类型,之后在代码中可以和使用int,float一样 使用 v4si,__m128类型。如下定义 __customtpe类型,看做4个int类型数据,源代码编译成汇编后使用对应的MOVDQA,PADDD执行完成操作

目前Clang、GUN等编译器内置了一些向量类型和工具函数,叫做 SIMD Intrinsics Function。高级语言代码中可以直接使用这些类型和函数,和普通函数的区别是这些SIMD内置函数直接由编译器使用SIMD指令实现。只要引入相应的头文件就可以使用这些函数
- <xmmintrin.h> : SSE, 支持同时对4个32位单精度浮点数的操作。
- <emmintrin.h> : SSE 2, 支持同时对2个64位双精度浮点数的操作。
- <pmmintrin.h> : SSE 3, 支持对SIMD寄存器的水平操作(horizontal operation)
- <tmmintrin.h> : SSSE 3, 增加了额外的instructions。
- <smmintrin.h> : SSE 4.1, 支持点乘以及更多的整形操作。
- <nmmintrin.h> : SSE 4.2, 增加了额外的instructions。
- <immintrin.h> : AVX, 支持同时操作8个单精度浮点数或4个双精度浮点数。
每一个头文件都包含了之前的所有头文件,所以如果你想要使用SSE4.2以及之前SSE3, SSE2, SSE中的所有函数就只需要包含<nmmintrin.h>头文件。
另一种方式是直接写汇编代码,使用SIMD指令操作寄存器,高级语言中嵌入汇编代码。目前 ffmpeg 中对编解码计算任务比较重的功能都采用的硬编码汇编的方式。

WASM对SIMD的支持
WASM标准目前定义了对128bit SIMD指令集的支持规范。emscripten编译工具也支持对使用了simd能力的源代码编译成wasm(只支持通过 simd内置函数方式写的源代码),chrome从 v91版本开始支持对WASM SIMD指令的解析。
这里比较影响 SIMD优化代码能否编译成WASM的主要点是只有通过SIMD内置函数方式写的SIMD源代码才能编译成WASM 对应的 SIMD指令。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O5t9TMwm-1656511217142)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/532b6a4cd326463cab96c0e416977aa8~tplv-k3u1fbpfcp-zoom-in-crop-mark:1956:0:0:0.image)]
示例demo
对两个float数组a、b 对应下标元素进行乘法运算,结构保存在数组c中
#include <stdio.h> #include <stdlib.h> #include <time.h> #include "sys/time.h" // simd内置函数 头文件 #include <immintrin.h> #define N 178257920 // 170M #define SEED 0x1234 float *a, *b, *c; #if defined(NORMAL) // 为3个float数组分配内存,每个数组包含 170 * 1024 * 1024 个元素 void gen_data(void) { unsigned i; a = (float*) malloc(N*sizeof(float)); b = (float*) malloc(N*sizeof(float)); c = (float*) malloc(N*sizeof(float)); srand(SEED); for(i=0; i<N; i++) { a[i] = b[i] = (float)(rand() % N); } } void free_data(void) { free(a); free(b); free(c); } void multiply(void) { unsigned i; for(i=0; i<N; i++) { c[i] = a[i] * b[i]; } } #elif defined(USE_SSE) void gen_data(void) { unsigned i; a = (float*) _mm_malloc(N*sizeof(float), 16); b = (float*) _mm_malloc(N*sizeof(float), 16); c = (float*) _mm_malloc(N*sizeof(float), 16); srand(SEED); for(i=0; i<N; i++) { a[i] = b[i] = (float)(rand() % N); } } void free_data(void) { _mm_free(a); _mm_free(b); _mm_free(c); } void multiply(void) { unsigned i; __m128 A, B, C; // 向量类型 __m128 = 4xfloat for(i=0; i<(N & ((~(unsigned)0x3))); i+=4) { A = _mm_load_ps(&a[i]); B = _mm_load_ps(&b[i]); C = _mm_mul_ps(A, B); _mm_store_ps(&c[i], C); } for(; i<N; i++) { c[i] = a[i] * b[i]; } } #elif defined(USE_AVX) void gen_data(void) { unsigned i; a = (float*) _mm_malloc(N*sizeof(float), 32); b = (float*) _mm_malloc(N*sizeof(float), 32); c = (float*) _mm_malloc(N*sizeof(float), 32); srand(SEED); for(i=0; i<N; i++) { a[i] = b[i] = (float)(rand() % N); } } void free_data(void) { _mm_free(a); _mm_free(b); _mm_free(c); } void multiply(void) { unsigned i; __m256 A, B, C; for(i=0; i<(N & ((~(unsigned)0x7))); i+=8) { A = _mm256_load_ps(&a[i]); B = _mm256_load_ps(&b[i]); C = _mm256_mul_ps(A, B); _mm256_store_ps(&c[i], C); } for(; i<N; i++) { c[i] = a[i] * b[i]; } } #endif void print_data(void) { printf("%f, %f, %f, %f\n", c[0], c[1], c[N-2], c[N-1]); } gettimeofday(); int main(void) { double start=0.0, stop=0.0, msecs; struct timeval before, after; printf("gen data start... \n"); gen_data(); printf("gen data end... \n"); gettimeofday(&before, NULL); multiply(); gettimeofday(&after, NULL); msecs = (after.tv_sec - before.tv_sec)*1000.0 + (after.tv_usec - before.tv_usec)/1000.0; print_data(); printf("Execution time = %2.3lf ms\n", msecs); free_data(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
default_target: normal normal: clang main.c -D NORMAL -o demo sse: clang main.c -D USE_SSE -o demo avx: clang main.c -D USE_AVX -mavx -o demo sse_os: clang main.c -D USE_SSE -Os -o demo wasm: emcc main.c \ -s ALLOW_MEMORY_GROWTH=1 \ -D NORMAL \ -o wasm.html wasm_sse: emcc main.c \ -s ALLOW_MEMORY_GROWTH=1 \ -msimd128 \ -msse \ -D USE_SSE \ -o wasm_sse.html wasm_os: emcc main.c \ -s ALLOW_MEMORY_GROWTH=1 \ -Os \ -D NORMAL \ -o wasm_os.html wasm_sse_os: emcc main.c \ -s ALLOW_MEMORY_GROWTH=1 \ -Os \ -msimd128 \ -msse \ -D USE_SSE \ -o wasm_sse_os.html- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
benchmark
c normal c sse c avx c sse + Os 660 ms 500 ms 400 ms 360 ms wasm normal wasm + sse wasm + Os wasm + sse + Os 1800 ms 1000 ms 750 ms 480 ms 结论
-
SIMD是CPU硬件层面支持的用于对数据进行并行操作的指令集
-
X86平台下对SIMD的实现为SSE、AVX指令集,ARM平台下对SIMD的实现为NEON指令集
-
编程语言对SIMD能力使用主要有两种方式。
- 汇编硬编码,直接操作SIMD指令和寄存器,高级语言中嵌入汇编代码,极致的性能优化。FFmpeg对simd的使用采用这种方式
- SIMD内置函数,高级语言中类似调用普通函数一样使用simd,函数的具体实现定义在编译器中
-
WebAssembly规范定义了128bit的SIMD指令集,高版本Chrome、Firefox支持 WASM SIMD实现
-
Emscripten编译工具只支持SIMD内置函数使用形式的源代码编译到WASM。能否使用上源代码SIMD优化能力取决于源代码对SIMD的使用形式。
-
-
相关阅读:
Win11校园网无法连接怎么办?Win11连接不到校园网的解决方法
猿创征文|date-fns 秒助手函数
BRAM/URAM资源介绍
[附源码]Python计算机毕业设计Django飞越青少儿兴趣培训机构管理系统
【C++入门到精通】C++入门 —— 红黑树(自平衡二叉搜索树)
mybatis拦截器实现数据权限
Ubuntu22.04 LTS+NVIDIA 4090+Cuda12.1+cudnn8.8.1
web:[极客大挑战 2019]Knife
ArcObjects SDK开发 010 FeatureLayer
设计模式-代理模式
- 原文地址:https://blog.csdn.net/pfourfire/article/details/125530419