-
ZooKeeper 7:数据读写——原子广播协议ZAB
ZAB协议
ZAB(ZooKeeper Atomic Brocadcast)协议,ZooKeeper原子广播协议,是一个分布式一致性算法,让ZooKeeper拥有了崩溃恢复和原子广播的能力,保证集群中的数据一致性。
上一篇文章介绍了CAP理论和BASE理论,ZAB协议是BASE理论的具体实现,是Paxos算法的变种实现。基于该协议,ZooKeeper实现了Master/Slave架构下集群各节点副本数据的最终一致性。
主要通过实现两种模式:- 正常运行时的消息广播模式
- Leader故障时的崩溃恢复模式
Zab 协议的特性:
- Zab 协议需要确保那些已经在Leader服务器上Commit的事务最终被所有的服务器提交和保存。也就是说,在leader上保存的事务,需要被所有的机器记录和保存。
- Zab 协议需要确保丢弃那些只在 Leader 上被提出而没有被提交的事务。也就是说,对于没有commit的事务,ZooKeeper没有义务进行保存。
简单而言,我们设计这个算法/协议的目的,就是保证客户端连接到任意的机器(leader/follower/observer)后,进行一定的数据操作申请,数据操作进行之后,需要让集群所有的机器都同步。
消息广播模式
数据写入
在正常的消息广播模式,ZooKeeper需要采取一定策略,来保证在分布式场景下事务的一致性。
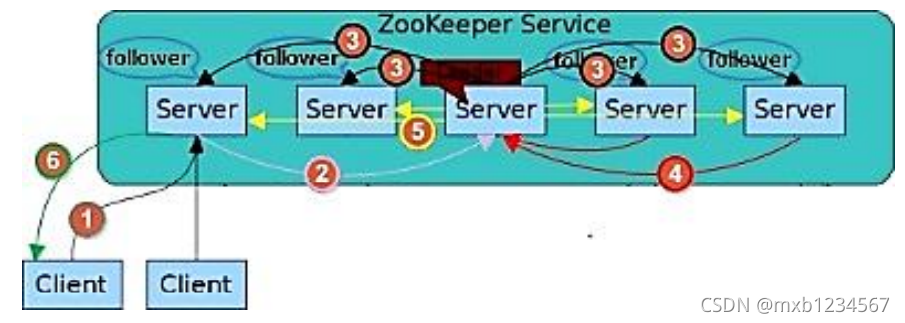
- Follwer接收客户端写请求,并将其转发给Leader
- Leader接收写请求,为其分配一个全局唯一的事务ID,Zxid(64位/单调递增)
- Leader生成一个形如(Zxid, data)的事务提案Proposal(data是事务体),并将其放入各Follower对应的FIFO队列中(通过TCP协议实现),再按照FIFO策略把Proposal广播出去
- Follower接收Proposal后,先以事务日志的形式落盘,再向Leader发送ack
- 当Leader接收到超过半数的ack之后(包括Leader自己),会向Follower发送commit命令,要求提交事务,同时自己在本地commit
- Follower收到commit命令后提交事务,同时向客户端反馈结果
这里的全局性事务ID zxid是leader生成的,
可以表示为一对整数(epoch,count):/** * 版本:ZooKeeper 3.8.0 * org.apache.zookeeper.server.util * ZxidUtils.java * 29行 */ public static long makeZxid(long epoch, long counter) { return (epoch << 32L) | (counter & 0xffffffffL); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以看出,其数据结构为一个long类型的数字(64位):
- 高32位为epoch,可以理解为leader的标识,每次更新
- 低32位为counter,是一个计数器
举个银行的例子:
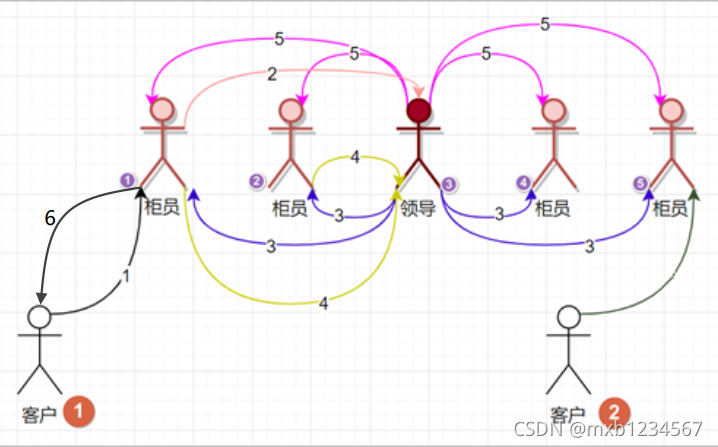
客户来银行存款:
- 客户①找到柜员①,说:昨天少给我存了1000,现在要加回来
- 柜员①说:对不起先生,我没权决定,请稍等,向领导柜员③汇报一下
- 柜员③收到消息后,经查账发现是搞错了,但按照规定必须向柜员①②④⑤征求意见(广播Proposal)
- 柜员①②反馈同意,柜员④⑤还在忙其他事情,但因为已经过半数的柜员(包括Leader)同意,所以Leader做出决定同意补钱(事务Commit)
- 柜员③告知所有下属,登记此事并生效
- 柜员①答复客户①,给您账号里加了1000
这里注意:只要有一个节点完成了commit,那么就可以告诉client事务完成。(只要有一个业务员完成登记,就可以告诉客户钱整好了)
此时需要可以思考:
如果Leader把某个Proposal广播给所有Follwer之后宕机,数据该怎么处理?
数据应该丢弃,因为该条数据并没有commit,不需要(没这个义务)进行保留。数据读取
客户端直接从Follower或Observer读取数据,如果要确保读到最新数据,应该先调用sync()进行强制同步。
崩溃恢复模式
在leader崩溃后,或者集群中超过半数服务器和leader无法正常通信,需要采取一定的策略进行恢复。进行选主时,选的就是能力强,数据新的服务作为leader,之前的内容写过选主的策略:ZooKeeper 5:集群模式
在选主完成后,进行数据同步,将最新的消息传播给所有的服务。参考
-
相关阅读:
golang gin ShouldBindUri数据绑定: `uri:“id“ binding:“required,uuid“`
Unity与IOS⭐Unity接入IOS SDK的流程图
【牛客网-前端笔试题】——vue专项练习
记录uniapp切换主题色能在抖音小程序上无效问题
【矩阵乘法】C++实现外部矩阵乘法
数据仓库:分层设计详解
自己学习Cesium的笔记简介
进程理论和实操
校内评奖评优|基于Springboot+Vue实现高校评优管理系统
【安全狗】Linux后渗透常见后门驻留方式分析
- 原文地址:https://blog.csdn.net/mxb1234567/article/details/125524278