-
JVM笔记(一)内存模型
该笔记基于hotspot虚拟机
什么是JVM?
java程序的运行环境(java二进制字节码的运行环境)
好处:
- 一次编写,到处使用
- 自动内存管理,垃圾回收功能
- 数组下标越界检查
- 多态(使用虚方法调用的机制实现了多态)
jvm jdk jre比较:
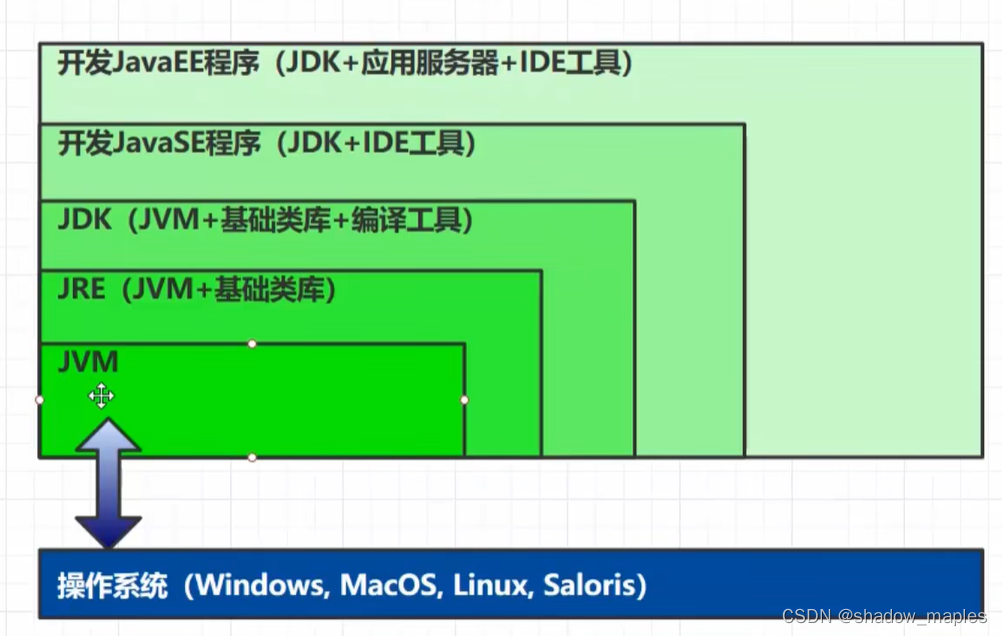
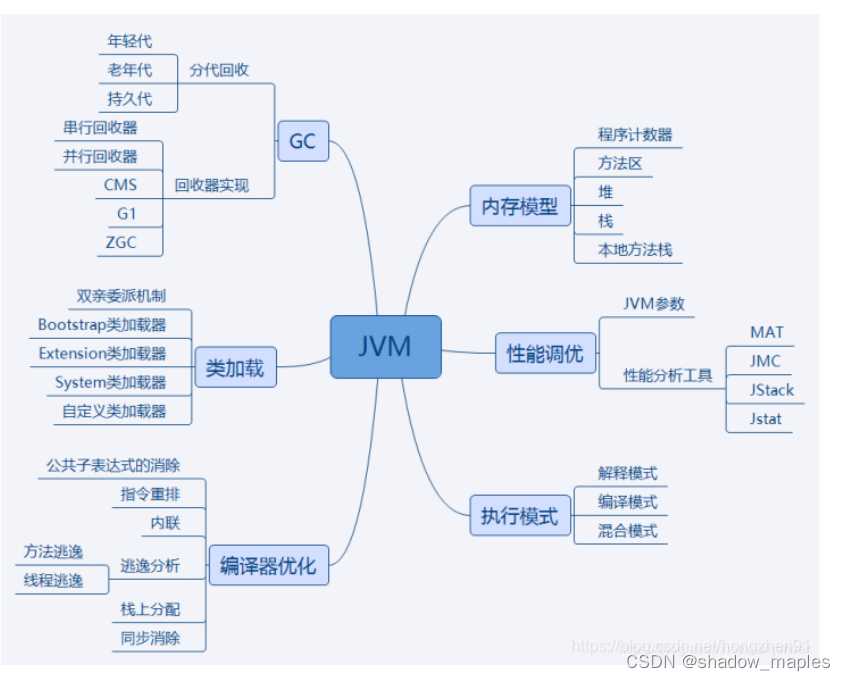
其中内存模型,类加载机制,GC是重点方面.性能调优部分更偏向应用,重点突出实践能力.编译器优化
和执行模式部分偏向于理论基础,重点掌握知识点.先学习一下:
- 内存模型各部分作用,保存哪些数据.
- 类加载双亲委派加载机制,常用加载器分别加载哪种类型的类.
- GC分代回收的思想和依据以及不同垃圾回收算法的回收思路和适合场景.
学习顺序:JVM内存结构------>垃圾回收机制-------->类的字节码结构------>类加载器----->运行期的一些优化
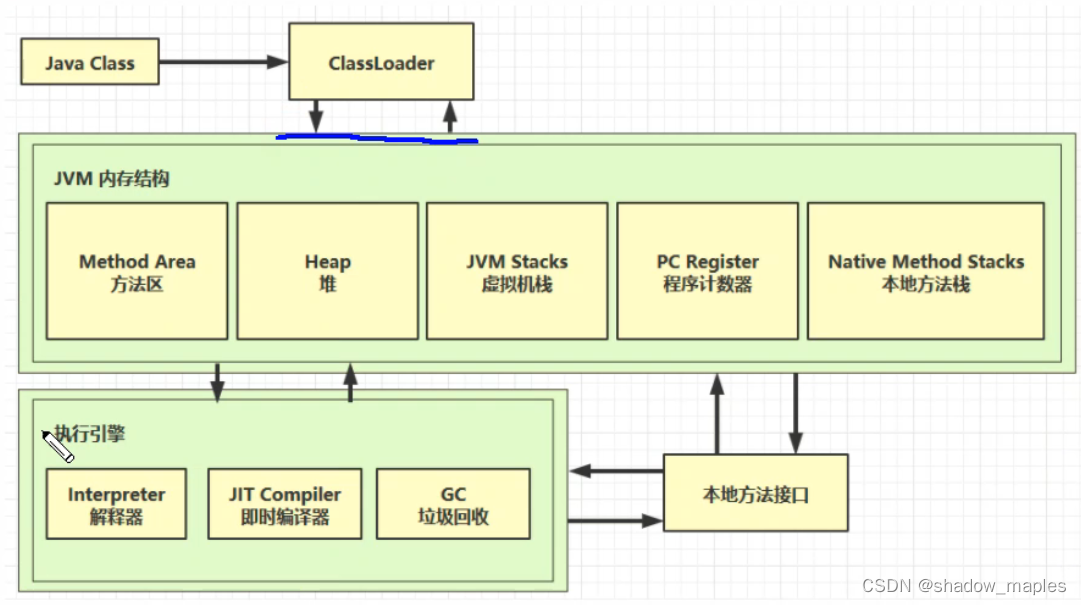
类放在方法区,类创建的实例对象放在堆中,堆中的实例对象调用方法时会用到虚拟机栈、程序计数器和本地方法栈
方法执行时,每行代码是由解释器进行逐行执行的
JVM内存结构
线程(私有)独占:栈、本地方法栈、程序计数器
程序共享:堆、方法区
1.程序计数器
程序计数器是执行速度最快的内存区域,它相当于交通警察,当jvm将class文件信息加载进运行时数据区后,它负责告诉线程下一步执行的地址,但这仅限于java代码,如果执行了本地方法(native method),(本地方法是java调用的C/C++的方法),那程序计数器存储的值为undefined(毕竟交通警察也不是万能的)。
1.1 作用:
保存着当前线程执行的字节码位置,每个线程工作时都有独立的计数器,只为执行Java方法服务,执行
Native方法时,程序计数器为空.1.2 特点:
- 线程私有的
- java虚拟机规范中 唯一一个不会存在内存溢出的区
2.栈
2.1 栈的定义:
栈是线程私有的,每个线程都有自己的栈,每个线程中的每个方法在执行的同时会创建一个栈帧用于存局部变量表、操作数栈、动态链接、方法返回地址等信息。
- 每个线程运行时所需要的内存,称为虚拟机栈
- 每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧(当前栈顶部的栈帧),对应着当前正在执行的方法
2.2 问题辨析:
1.垃圾回收是否涉及栈内存?
不涉及。因为对于栈内存来说其内部都是栈帧,而当方法执行结束后,会自动弹出栈帧,也就会被回收,不需要使用垃圾回收。- 1
2.栈内存分配越大越好吗?
栈内存可以在运行代码时通过虚拟机参数指定,即“-Xss”这个参数,他是给我们栈内存指定大小,如果不指定,Linux、macOS、Solaris等系统默认每个栈的大小都是1024KB(一兆),Windows比较特殊,他是Windows的虚拟内存影响栈的大小。栈内存设置的越大,反而会让线程数变得更少,因为物理内存的大小是一定的,比如说我一个线程使用的是一个栈内存,那一个线程假如用了一兆内存,假如总共的物理内存假设有500兆,那理论上可以有五百个线程同时运行,但假如把每个线程的栈内存设置了2M内存,那么理论上只能同时运行250个线程。所以栈内存并不是划分的越大越好。把他设置大了,通常只是能够进行更多次的方法递归调用,而不会增强运行的效率,反而会影响到线程数目的变少。所以不建议设置为太大,一般采用系统默认的即可。- 1
3.方法内的局部变量是否线程安全?
不一定 * 如果方法内局部变量没有逃离方法的作用范围(没有将局部变量作为返回值返回),它是线程安全的。 * 如果是局部变量引用了对象(引用的是对象的话存在被其他线程共享的问题,如果是基本类型的变量也可以保证是安全的),并逃离了方法的作用范围(比如方法内局部变量当作返回值返回了,就会逃离出方法的作用范围),需要考虑线程安全问题。 所以判断一个变量是否是安全的,不仅要看它是否是方法内的局部变量,还要看它是否逃离了方法的作用范围。- 1
- 2
- 3
- 4
- 5
- 6
2.3 栈内存溢出
- 栈帧过多导致栈内存溢出-----递归调用
- 栈帧过大导致内存溢出(不太容易出现这种情况)
- 一些第三方库也可能导致栈内存溢出(比如一些类的循环引用)
2.4 线程诊断—cpu占用过多
定位
- 用top定位哪个进程对cpu的占用过高
- ps H -eo pid,tid,%cpu |grep 进程id(用ps命令进一步定位是哪个线程引起的cpu占用过高)
- jstack 进程id 可以根据线程id找到有问题的线程,进一步定位到问题代码的源码行数(jstack中显示的线程(tid)是以16进制显示的)
3.本地方法栈
与栈类似,也是用来保存执行方法的信息.执行Java方法是使用栈,执行Native方法时使用本地方法栈.
给本地方法的运行,提供一个内存空间
4.堆
4.1 定义
JVM内存管理最大的一块,堆被线程共享,目的是存放对象的实例,几乎所有的对象实例都会放在这里,当堆没有可用空间时,会抛出OOM异常.根据对象的存活周期不同,JVM把对象进行分代管理,由垃圾回收器进行垃圾的回收管理。
通过new关键字,创建对象都会使用堆内存
特点:
- 它是线程共享的,堆中对象都需要考虑线程安全问题。
- 有垃圾回收机制
4.2 堆内存
Xmn、Xms、Xmx、Xss都是JVM对内存的配置参数,我们可以根据不同需要区修改这些参数,以达到运行程序的最好效果。 -Xms 堆内存的初始大小,默认为物理内存的1/64 -Xmx 堆内存的最大大小,默认为物理内存的1/4 -Xmn 堆内新生代的大小。通过这个值也可以得到老生代的大小:-Xmx减去-Xmn -Xss 设置每个线程可使用的内存大小,即栈的大小。- 1
- 2
- 3
- 4
- 5
堆内存诊断工具:
- jps工具
- 查看当前系统中有哪些java进程
- jmap工具
- 查看堆内存占用情况(只能查询某一时刻,不能连续查询)
- jmap -heap 进程号
- jconsole工具
- 图形界面的,多功能的检测工具
- jvisualvm工具
- 图形界面,比jconsole更强大的工具
5.方法区
5.1 定义
又称非堆区,用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器优化后的代码等数据。jdk1.8之前的永久代(用堆内存的一部分作为方法区)和1.8之后的元空间(不再使用堆内存,用的是操作系统内存)都是方法区的一种实现
方法区是一种规范
永久代:方法区在hotspot jdk1.8之前的一种实现
元空间:方法区在hotspot jdk1.8之后的一种实现
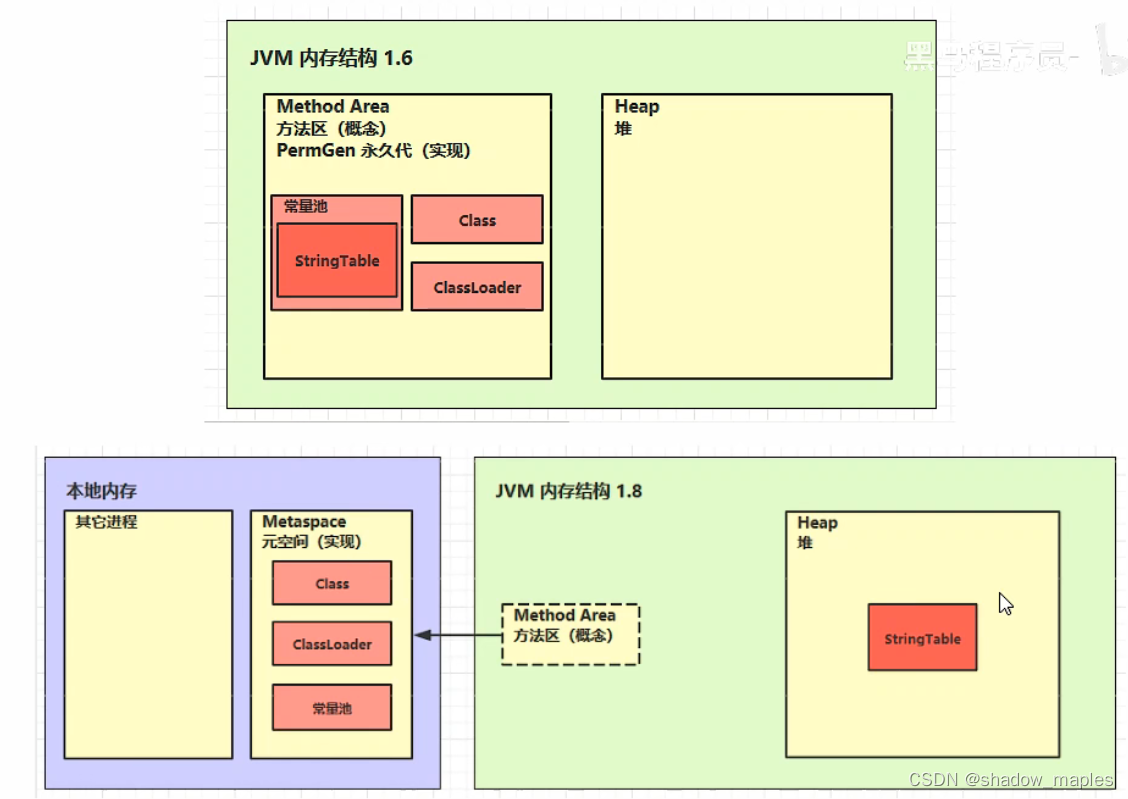
5.2 内存溢出
- 1.8以前会导致永久代内存溢出
演示永久代内存溢出 java.lang.OutOfMemoryError:PermGen space -XX:MaxPermSize=8m- 1
- 2
- 1.8之后会导致元空间内存溢出
演示元空间内存溢出:java.lang.OutOfMemoryError:Metaspace -XX:MaxMetaspaceSize=8m- 1
- 2
5.3 常量池
就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
5.4 运行时常量池
常量池是*.class文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
5.5 字符串常量池StringTable(串池)
5.5.1 StringTable特性
- 常量池中的字符串仅是符号,只有在被用到时才会转化为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder
- 字符串常量拼接的原理是编译器优化
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池中
intern方法:
作用就是尝试将一个字符串放入StringTable中,如果不存在就放入StringTable并返回StringTable中的地址,如果存在的话就直接返回StringTable中的地址。这是jdk1.8版本中intern方法的作用。
jdk1.6版本中有所不同,1.6中intern尝试将字符串对象放入StringTable,如果有则并不会放入,如果没有会把此对象复制一份,放入StringTable, 再把StringTable中的对象返回。
5.5.2 StringTable位置
jdk7以前,字符串常量池存放在永久代。
jdk7开始字符串常量池的位置调整到java堆中。
jdk8去除了永久代,开始使用元空间,字符串常量池存放于堆中。
5.5.3 StringTable垃圾回收
垃圾回收(gc)只有在内存紧张时才会触发
可以在vm options:中添加条件
- -Xmx10m :指定堆内存最大值为10m
- -XX:+PrintStringTableStatistics :打印字符串常量池信息
- -XX:+PrintGCDetails :在控制台输出详细的GC情况
- -verbose:gc :在控制台输出GC情况
5.5.4 StringTable性能调优
-
调整 -XX:StringTableSize=桶个数
因为StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少哈希碰撞的几率,从而增加查找速度。
-
考虑将字符串对象是否入池
可以通过 intern 方法减少重复入池
5.5.5 StringTable面试题
public class Demo1_21 { public static void main(String[] args) { String s1 = "a"; String s2 = "b"; String s3 = "ab"; //new StringBuilder().append("a").append("b").toString() //StringBuild对象调用toString()时会new一个新对象:new String("ab") //是运行期间动态拼接的 String s4 = s1 + s2; //因为s5是两个常量拼接的,跟s4不同,是javac在编译期间的优化,结果已经在编译期间确定为ab String s5 = "a" + "b"; String s6 = s4.intern(); System.out.println(s3 == s4); //false System.out.println(s3 == s5); //true System.out.println(s3 == s6); // String x2 = new String("c") + new String("d"); // x2是堆中数据 new String("cd") String x1 = "cd"; // 常量池中的数据 "cd" x2.intern(); // 尝试将堆中的x2放入常量池,但常量池中已经存在,所以入池失败 // 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢? System.out.println(x1 == x2);//false //如果调换22跟23行位置结果为true //如果是在jdk1.6的环境下,即便调换22跟23行代码,结果仍为false //因为1.6环境下x2是复制进池的,池中是副的,跟堆中的cd是两个不同的对象 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
相关阅读:
【axios网络请求库】认识Axios库;axios发送请求、创建实例、创建拦截器、封装请求
竞赛选题 深度学习手势识别 - yolo python opencv cnn 机器视觉
vue 更新规则
QT之QListView的简介
「前端进阶」从多线程角度来看 Event Loop
云计算基础技术
2022/7/20
力扣练习——51 搜索二维矩阵
ICG作为染料和CY有哪些区别了?同时ICG-PEG-NHS相关性质分享!
12.神经网络模型
- 原文地址:https://blog.csdn.net/weixin_50342605/article/details/125524656
