-
【网站架构】一招搞定90%的分布式事务,实打实介绍数据库事务、分布式事务的工作原理应用场景

大家好,欢迎来到停止重构的频道。本期,我们来聊一下数据库事务以及分布式事务。
大家都在强调事务的重要性,而分布式事务也说是微服务必备的。但又说事务会影响性能,分布式事务更是很复杂的东西。使得大家都很迷茫什么时候才该用事务,也不清楚什么场景下,分布式事务才是必要的。
接下来我们将会实打实地讨论实际项目当中,数据库事务、分布式事务的工作原理以及相关的应用场景。事务说白了就是把多次数据操作打包成一次操作。要么操作都成功,要么都不执行。而事务也分为两种,我们也将对这两种事务分别讨论。
1、数据库事务,一般指的是单个数据库的事务
2、分布式事务,一般指的是多个数据库的事务数据库事务
首先是数据库事务,数据库事务是保证单个数据库下多个数据表的数据一致性问题。也就是不会出现A表更新了数据而B表没更新的状况(要么都更新,要么都回滚)。
数据库事务的工作原理是这样的。请求端发送“开启事务的SQL语句(begin)”到数据库以开启事务。事务开启期间,请求端可发送多条SQL语句以操作数据。数据库会根据事务等级及相关的数据表或数据行阻塞其他数据操作(直到事务结束)。
操作完毕后,请求端可根据数据操作是否成功以及自身业务要求。决定发送“提交或回滚事务(commit/rollback)”的SQL语句,以告诉数据库是否将之前操作成功的数据进行回滚。
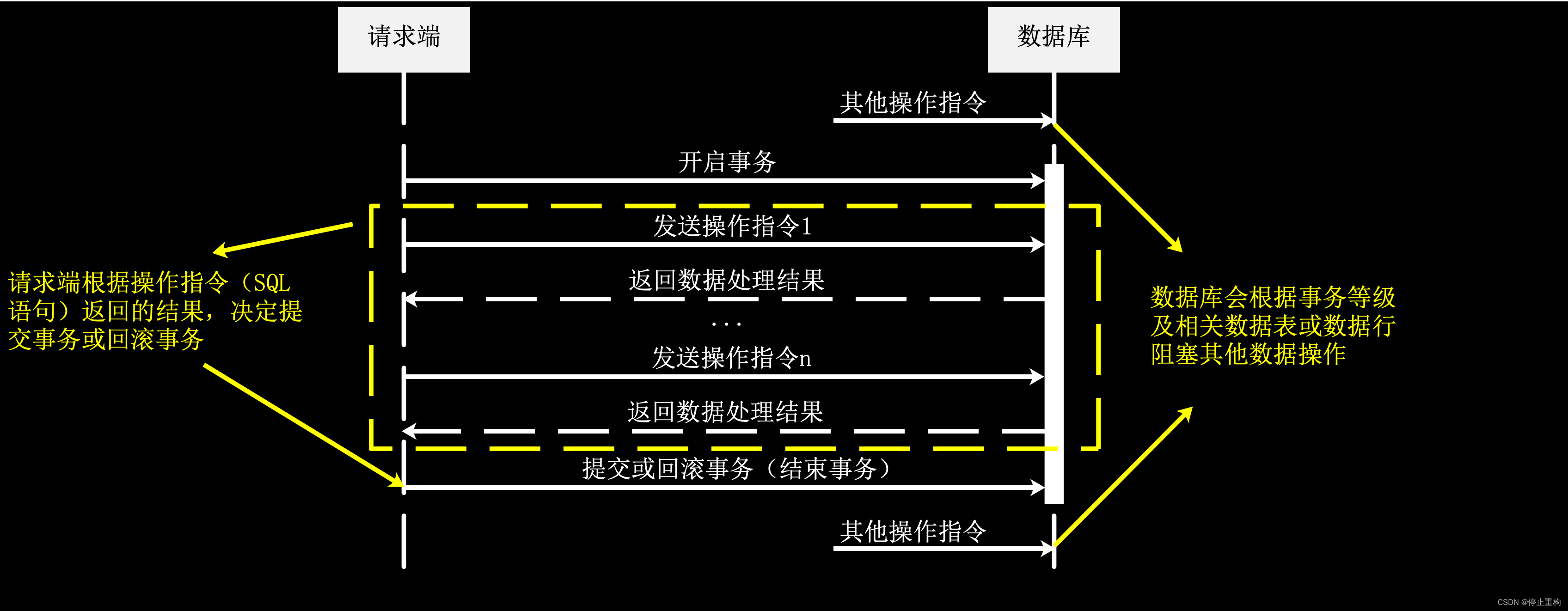
数据库事务影响数据库性能的原因有两个:-
事务操作期间,可能会阻塞其他数据操作,具体需要根据事务等级、相关数据表或数据行而定;
-
若事务需要回滚,则一般会锁表,阻塞所有操作相关表的数据操作。
数据库事务虽然看上去很复杂,但是在实际开发过程中是简单的。以Spring框架为例,在Service函数中添加事务注解即可,框架会根据数据操作是否出现exception(说明该次数据操作失败)而决定是否回滚。

另外,事务等级是可以选择的。但除非数据的读一致性要求非常强,如账号余额检验等场景。一般情况下,事务等级保持默认就可以了。
那么什么时候使用数据库事务呢,我们的推荐如下:-
需要多次数据更新操作的接口,一般需要添加数据库事务
-
查询与只更新一次数据的接口,且查询的数据读一致性要求非常强,如账号余额校验等场景。则一般添加数据库事务,且事务等级需要调到最高(性能影响也会更高)。
分布式事务
接下来是分布式事务,分布式事务是解决多个数据库的数据一致性问题。但分布式事务的实现方式是复杂的。
很多时候,分布式事务是没有必要的。
例如,交易时需要同时操作余额数据库与优惠券数据库。其实这是一种过度设计,完全没必要分离出这两个系统(合并成一个就可以了)。这也是大多数项目的现状,子系统分得太碎了以至于出现很多的分布式事务问题。
又例如,博客编写后,自动推送到某个活动专栏或者论坛。这种情况,也是没有必要做分布式事务的。因为如果推送活动或论坛失败,博客仍应该更新,而不能回滚。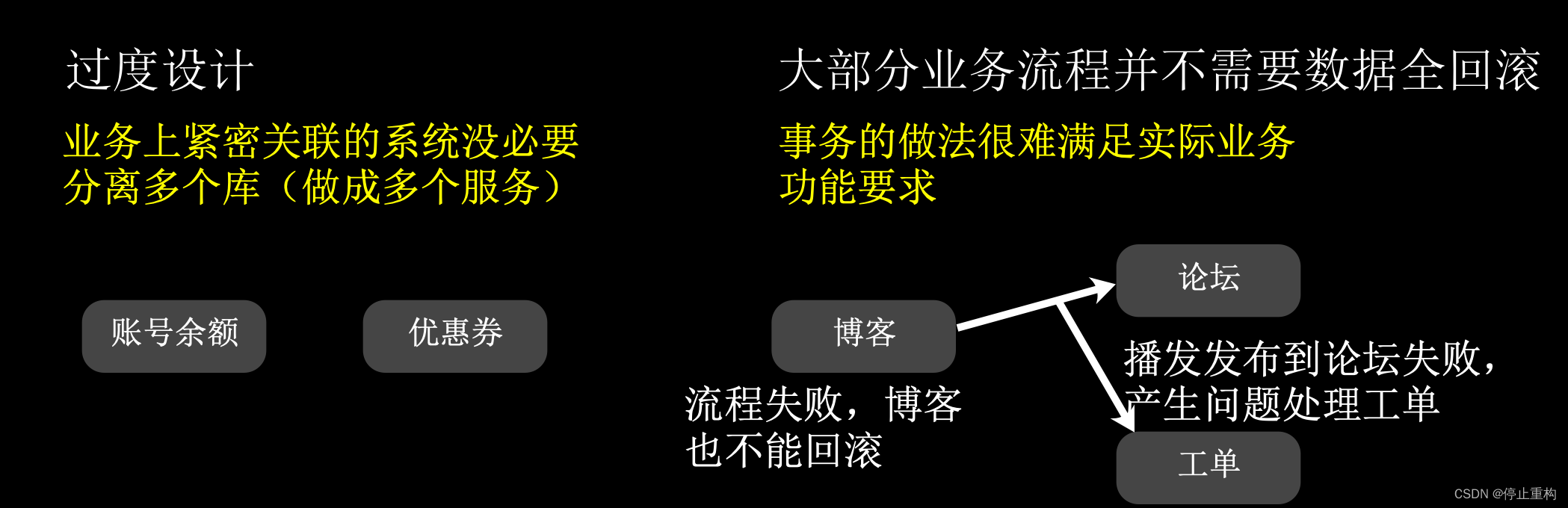
其实这也说明了一个问题,数据库事务与分布式事务的区别。除了单个数据库与多个数据库的区别,还有一个更加重要的区别:业务上的区别。一个数据库内的表是业务关联性较强的,所以数据库事务是频繁的。但是多个数据库间由于所属的业务子系统是不一样的,所以业务关联性是不强的(数据不一致的要求不高)。自然需要分布式事务的场景其实也不多(过度设计除外)。
所以,大多数场景下,需要同时操作多个数据库的话。一般前端整合多个子系统的API即可,或者由一个后端程序调用其他系统的API。
当然,分布式事务的场景仍然是存在的。例如,订单与库存系统等。
下面我们开始介绍分布式事务的具体方法,分布式事务的理论做法有很多(如2PC、3PC、TCC、本地消息表等)。我们不一一介绍这些理论做法,只介绍实际项目中比较常用的几种具体方法。-
XA事务
-
Seata分布式事务框架
-
我们常用的流程方式
分布式事务方法:XA事务
首先是XA事务,XA事务是数据库原生支持的分布式事务(MySQL、Oracle都支持)。
XA事务的工作原理如图所示,可以简单地理解为同时执行多个数据库的数据库事务。XA事务也有相关的操作框架,如JTA等。

XA事务在实现上是相对简单的(不需要使用其他中间件辅助),但在大型网站系统中,这种方式是不被提倡的。因为它同时阻塞了多个数据库(同时浪费多个数据库性能)。
同时,XA事务也意味着一个后端程序需要同时操作多个数据库。除非是这多个数据库。存储的是相同类型的数据(数据分片存储),如由于用户信息太多而存储在多个数据库中,不然XA事务的应用场景其实不多。
分布式事务方法:Seata框架
接下来是Seata分布式事务框架,Seata的大致工作原理如图所示(工作模式实际上有4种,不同模式有所区别)。Seata需要额外部署事务协调服务(TC)作为全局监控的中间件,后端程序需要嵌入Seata的事务管理器(TM)、资源管理器(RM)等代码。各个后端程序向事务协调服务报告其执行的结果,并根据全局事务的结果决定是否回滚已经操作成功的数据。
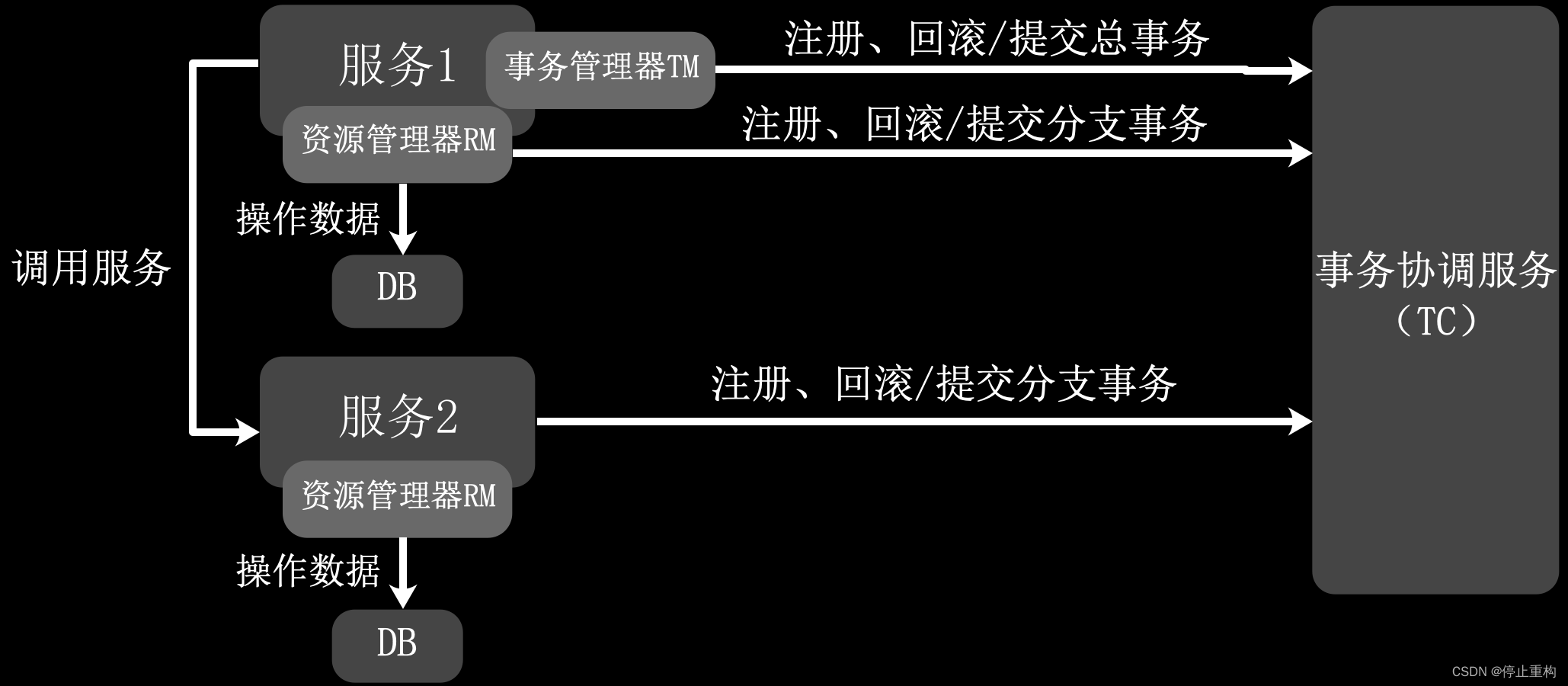
由于我们没有在实际项目中应用过这个框架,就不做过多解释了。没有使用的理由并不是它不优秀,之前有个项目也是决定使用的,但是最终没用是因为大多数工程师没弄懂(囧)。
对于这种技术团队理解上存在门槛的技术,我们一直是慎用的,而且也推动我们设计出了一种更加简单有效流程方式。分布式事务方法:流程方式
我们常用的分布式事务方法其实是一种流程的思维。因为在实际项目当中,分布式的事务的做法需要符合实际业务流程,而不能简单粗暴地有一条数据操作不成功就全局回滚。
比如订单与库存的分布式事务,当订单正常生成后,但库存不足(数据操作失败)。一般情况下,并不要求订单回滚(用户会很奇怪),而是应该把订单关闭,并记录库存异常,且通知采购。
其实大多数的分布式事务场景都是一种流程,所以我们做了一个流程中心(以后会开源)。流程中心的数据库记录了各个流程(包含各异常流程),其他后端程序与流程中心之间通过API调用。由于调度中心是独立子系统,所以即使某个业务子系统宕机,也能记录异常,以方便运营管理员通知运维人员修复。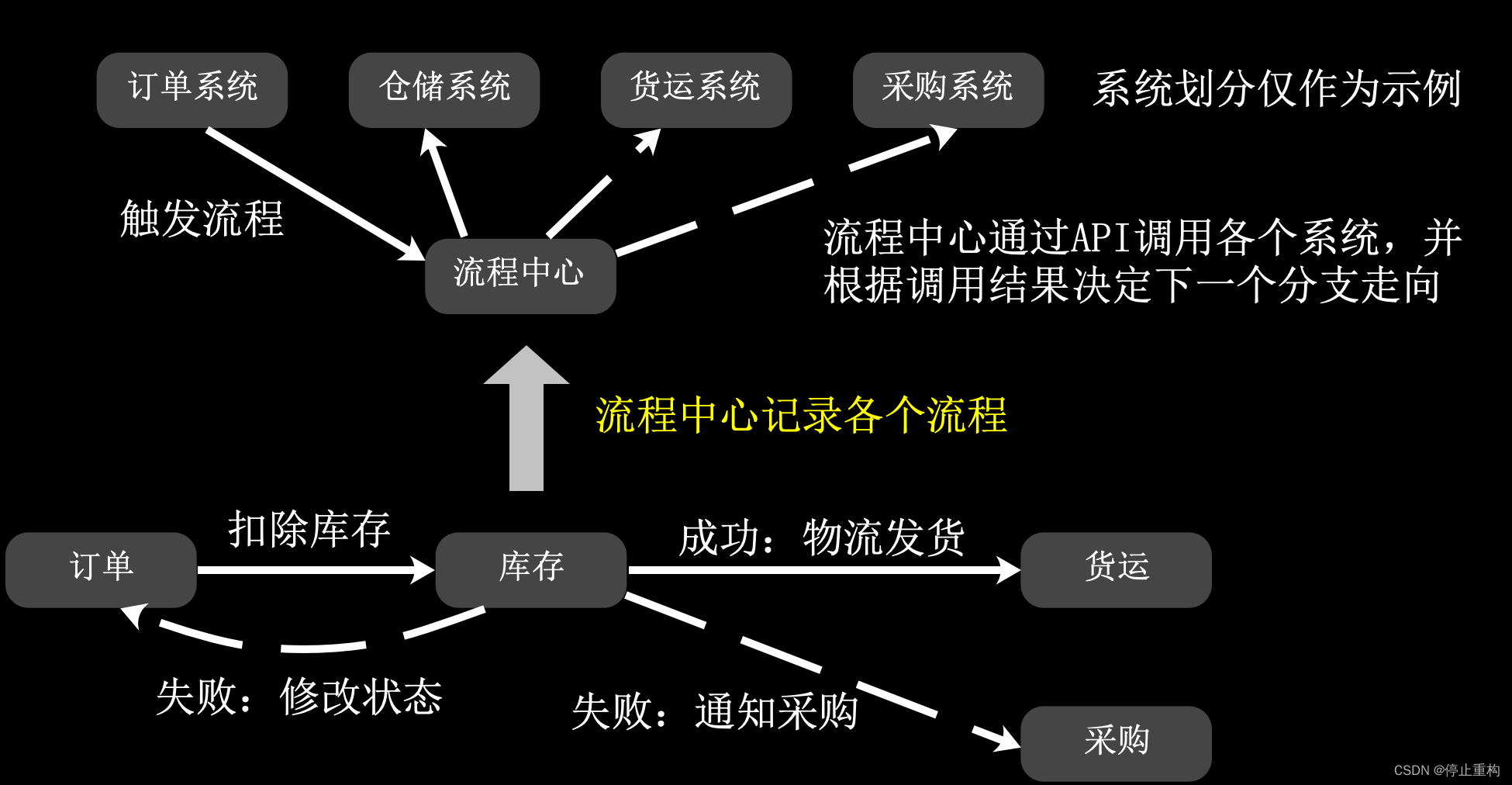
这种流程中心的做法不仅能解决大多数分布式事务场景,而且能切断子系统与子系统的直接联系。通过流程中心作为调度中心,既能保证各子系统的独立性,也能对一些复杂流程进行统一管理。而不会出现子系统间有缕不清的关系。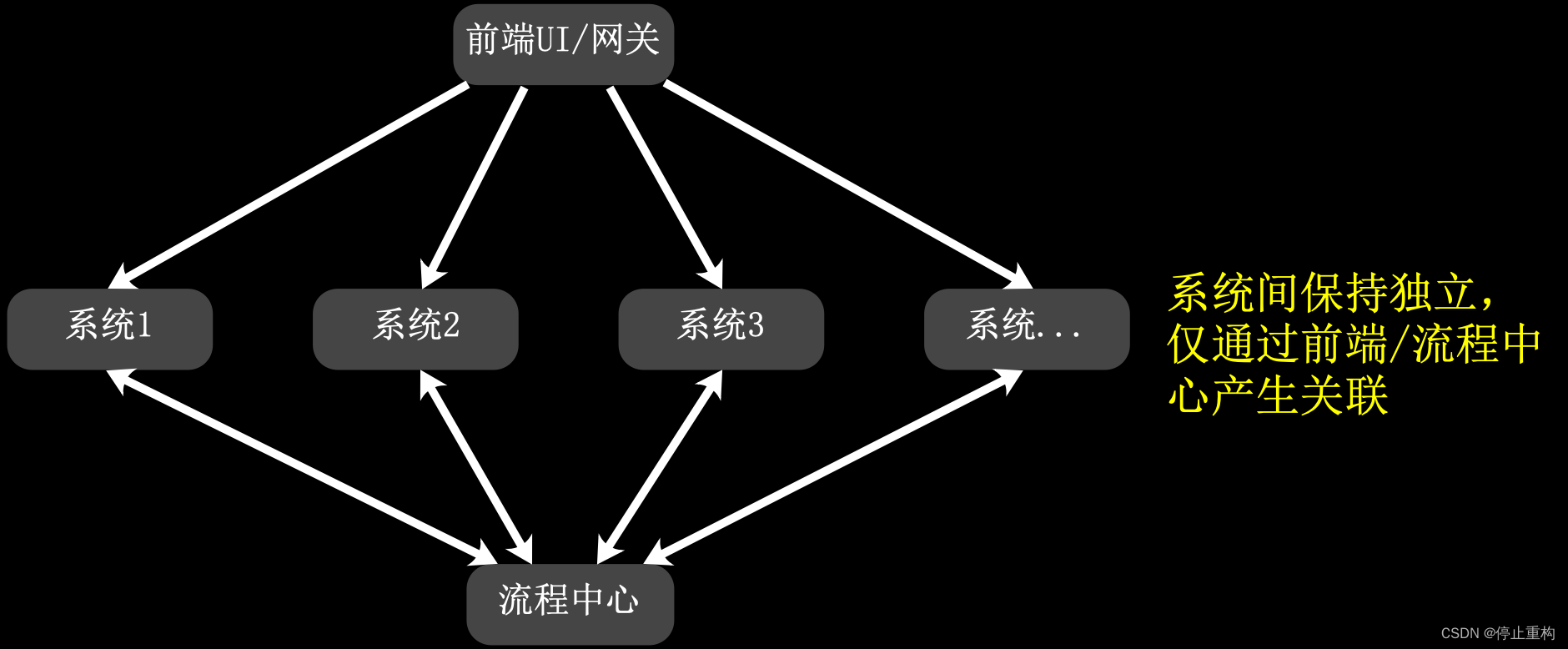
当然,这种流程的方式有一种场景是不合适的。就是同类数据分库分区记录的场景(数据分片存储),如两个用户记录在不同区域的不同数据库,A用户向B用户转账。对于这种场景,还是XA事务或者使用Seata框架比较合适。总结
数据库事务或者分布式事务,都只是在防止一些极端情况和某些未发现的bug。很多时候,发生的概率很低,且在测试阶段很难发现。
但是,这是系统健壮性的保险机制。如果开发时不注意事务的添加,只会徒增运营成本(很多投诉),且给用户留下各种不稳定的坏印象。 -
-
相关阅读:
深入流行推荐引擎3:Spotify音乐推荐系统
Stream流的使用详解(持续更新)
那种输出全部组合的List<List<Integer>>题
推荐一个stable-diffusion-webui的升级项目stable-diffusion-webui-forge
图像Star特征提取
基于springboot的海鲜特产商城
美国访问学者申请|签证需要哪些材料?
Python 函数方法的类型注解
进程调度的基本过程——请各位不要当渣男~
Springboot+vue的船舶监造系统(有报告)。Javaee项目,springboot vue前后端分离项目。
- 原文地址:https://blog.csdn.net/Daniel_Leung/article/details/125476254