-
Azkaban Flow 1.0 的使用
一、简介
Azkaban 主要通过界面上传配置文件来进行任务的调度。它有两个重要的概念:
- Job: 你需要执行的调度任务;
- Flow:一个获取多个 Job 及它们之间的依赖关系所组成的图表叫做 Flow。
目前 Azkaban 3.x 同时支持 Flow 1.0 和 Flow 2.0,本文主要讲解 Flow 1.0 的使用,下一篇文章会讲解 Flow 2.0 的使用。
二、基本任务调度
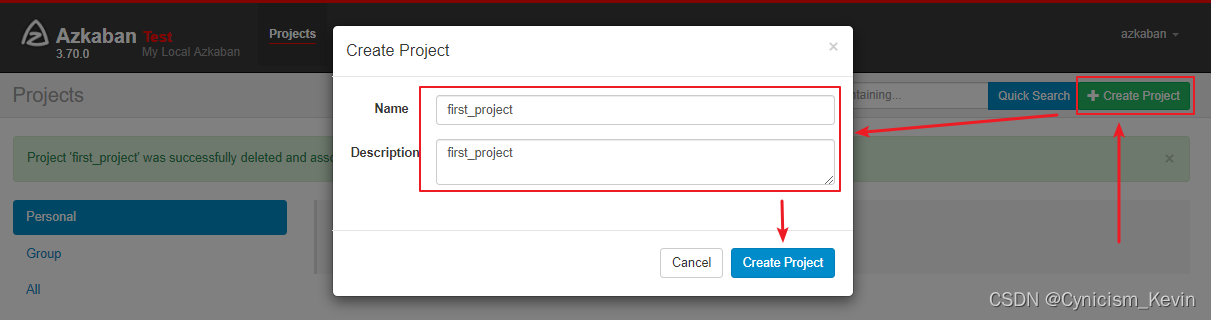
2.1 新建项目
在 Azkaban 主界面可以创建对应的项目:
2.2 任务配置
新建任务配置文件
Hello-Azkaban.job,内容如下。这里的任务很简单,就是输出一句'Hello Azkaban!':#command.job type=command command=echo 'Hello Azkaban!'- 1
- 2
- 3
2.3 打包上传
将
Hello-Azkaban.job打包为zip压缩文件:
通过 Web UI 界面上传:

上传成功后可以看到对应的 Flows:
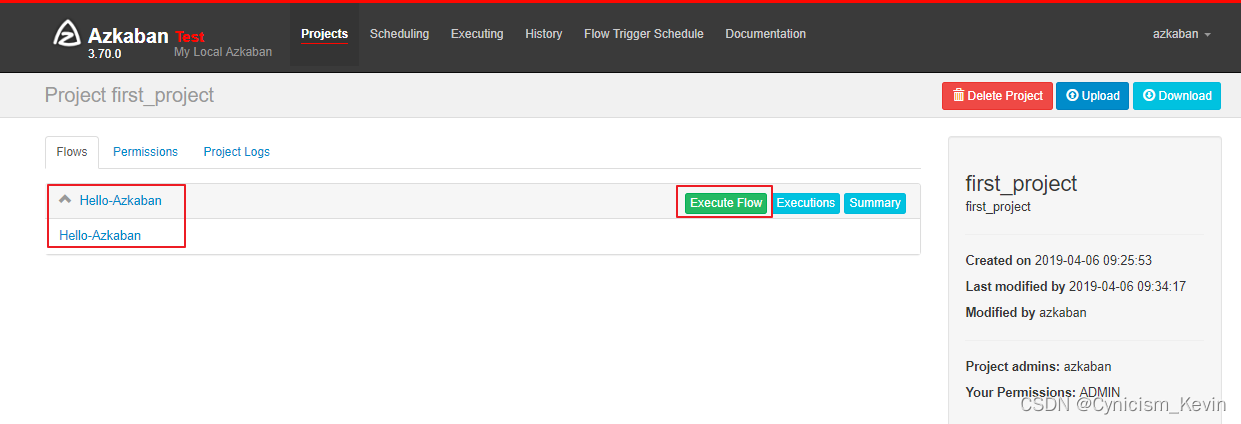
2.4 执行任务
点击页面上的
Execute Flow执行任务:
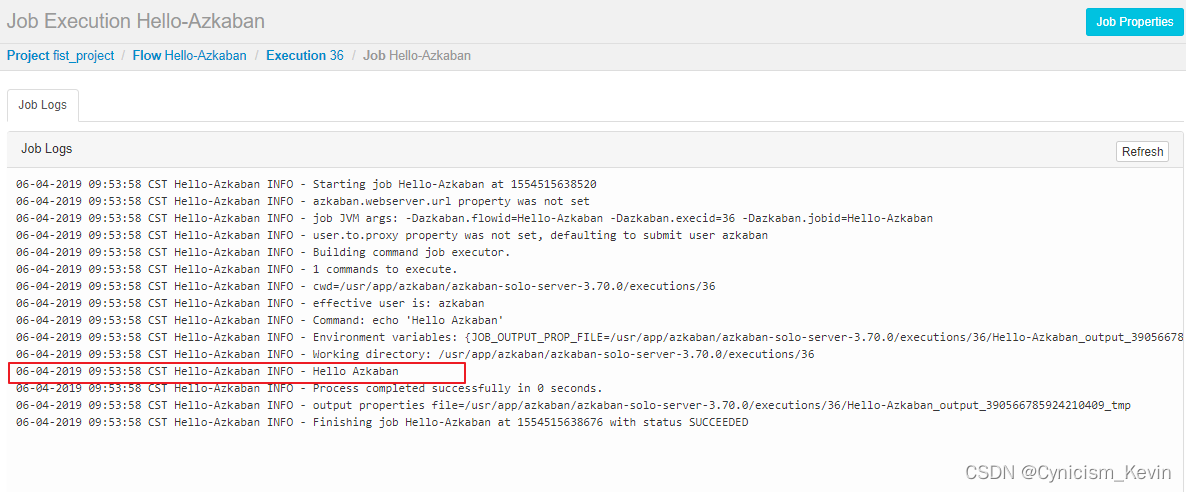
2.5 执行结果
点击
detail可以查看到任务的执行日志:
三、多任务调度
3.1 依赖配置
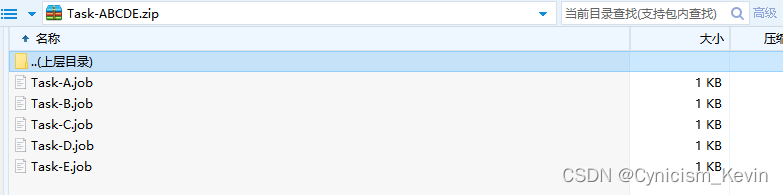
这里假设我们有五个任务(TaskA——TaskE),D 任务需要在 A,B,C 任务执行完成后才能执行,而 E 任务则需要在 D 任务执行完成后才能执行,这种情况下需要使用
dependencies属性定义其依赖关系。各任务配置如下:Task-A.job :
type=command command=echo 'Task A'- 1
- 2
Task-B.job :
type=command command=echo 'Task B'- 1
- 2
Task-C.job :
type=command command=echo 'Task C'- 1
- 2
Task-D.job :
type=command command=echo 'Task D' dependencies=Task-A,Task-B,Task-C- 1
- 2
- 3
Task-E.job :
type=command command=echo 'Task E' dependencies=Task-D- 1
- 2
- 3
3.2 压缩上传
压缩后进行上传,这里需要注意的是一个 Project 只能接收一个压缩包,这里我还沿用上面的 Project,默认后面的压缩包会覆盖前面的压缩包:
3.3 依赖关系
多个任务存在依赖时,默认采用最后一个任务的文件名作为 Flow 的名称,其依赖关系如图:
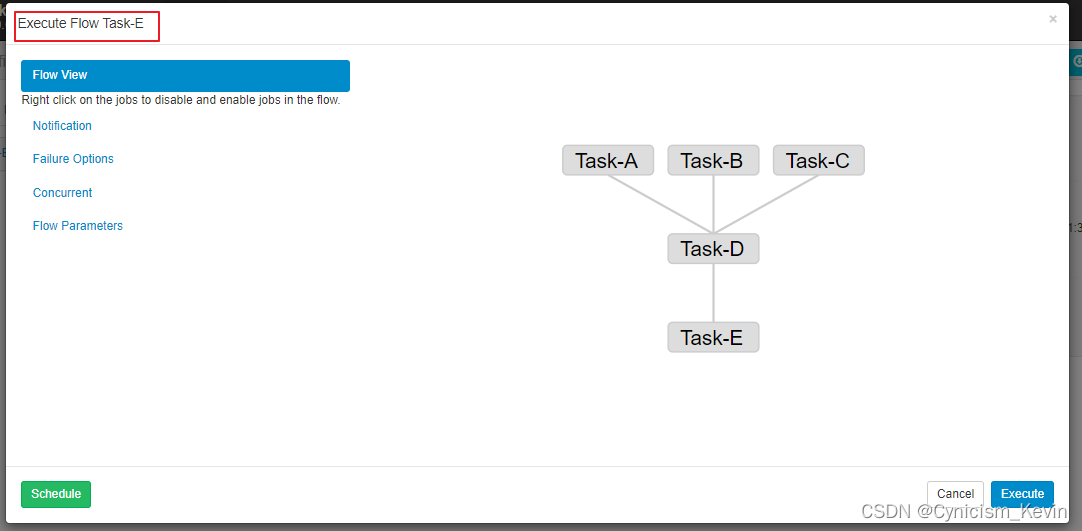
3.4 执行结果
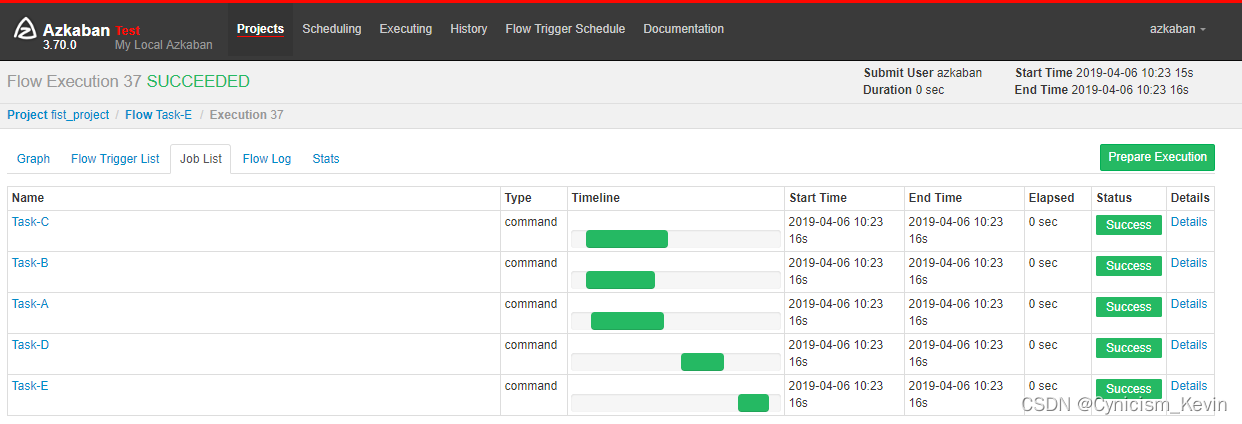
从这个案例可以看出,Flow1.0 无法通过一个 job 文件来完成多个任务的配置,但是 Flow 2.0 就很好的解决了这个问题。
四、调度HDFS作业
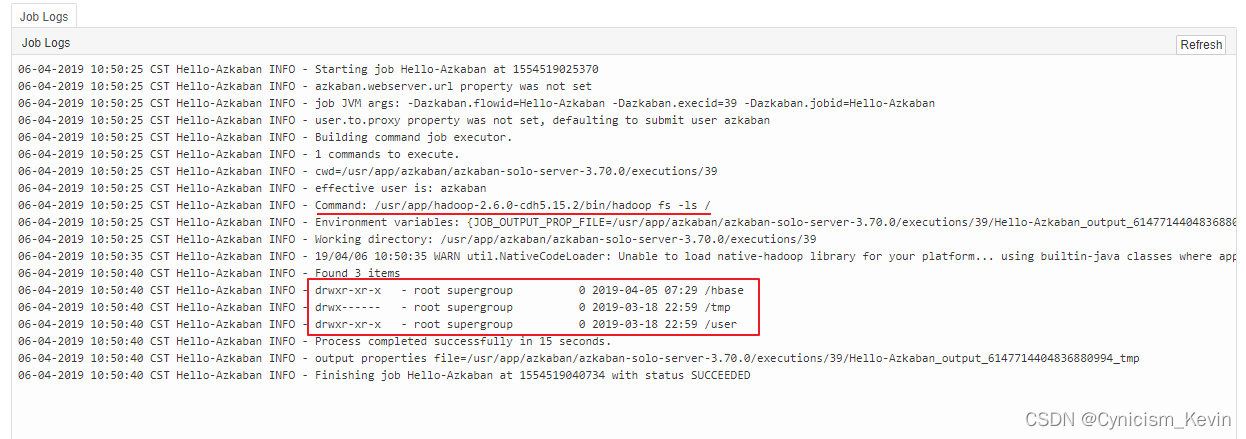
步骤与上面的步骤一致,这里以查看 HDFS 上的文件列表为例。命令建议采用完整路径,配置文件如下:
type=command command=/usr/app/hadoop-2.6.0-cdh5.15.2/bin/hadoop fs -ls /- 1
- 2
执行结果:
五、调度MR作业
MR 作业配置:
type=command command=/usr/app/hadoop-2.6.0-cdh5.15.2/bin/hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3- 1
- 2
执行结果:

六、调度Hive作业
作业配置:
type=command command=/usr/app/hive-1.1.0-cdh5.15.2/bin/hive -f 'test.sql'- 1
- 2
其中
test.sql内容如下,创建一张雇员表,然后查看其结构:CREATE DATABASE IF NOT EXISTS hive; use hive; drop table if exists emp; CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- 查看 emp 表的信息 desc emp;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
打包的时候将
job文件与sql文件一并进行打包:
执行结果如下:
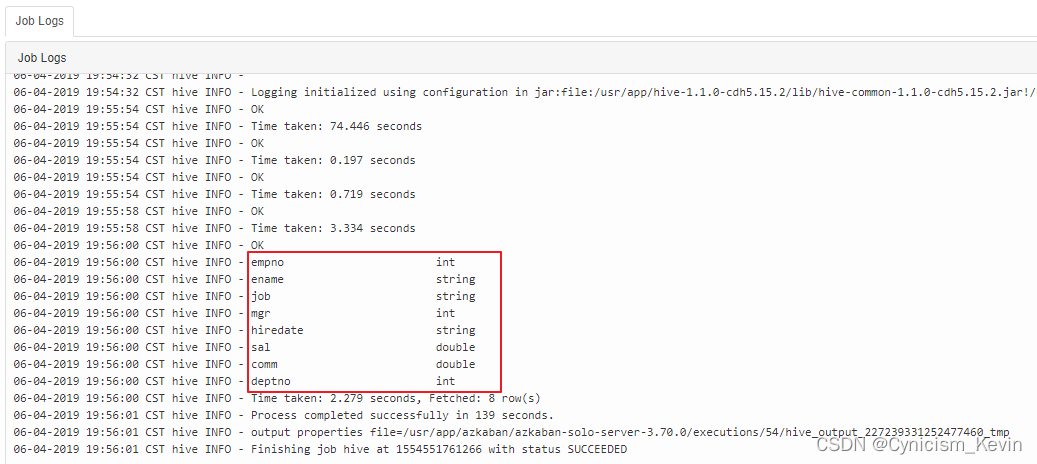
七、在线修改作业配置
在测试时,我们可能需要频繁修改配置,如果每次修改都要重新打包上传,这会比较麻烦。所以 Azkaban 支持配置的在线修改,点击需要修改的 Flow,就可以进入详情页面:

在详情页面点击
Eidt按钮可以进入编辑页面:
在编辑页面可以新增配置或者修改配置:
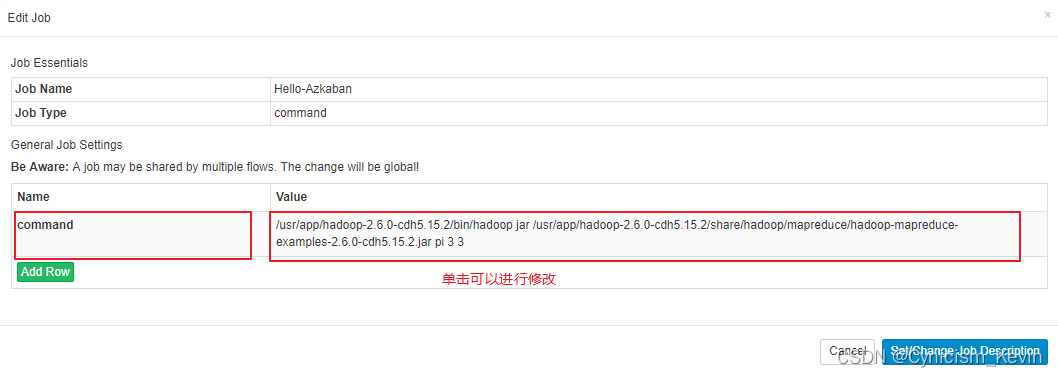
附:可能出现的问题
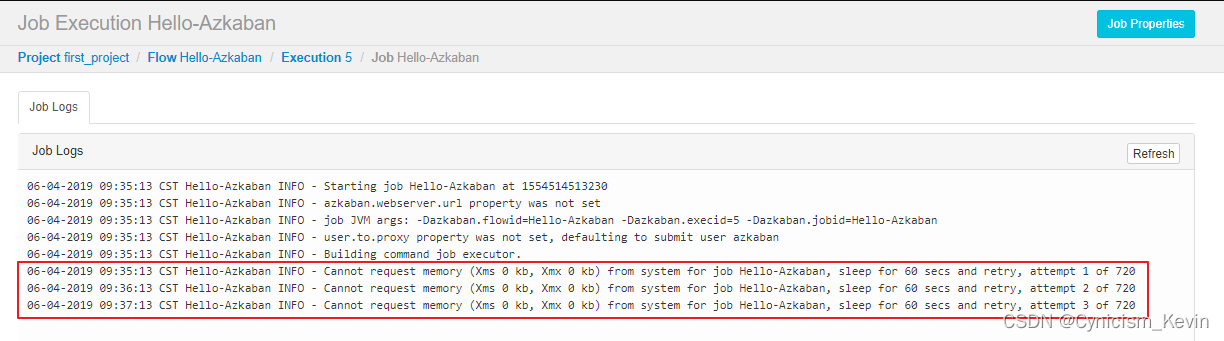
如果出现以下异常,多半是因为执行主机内存不足,Azkaban 要求执行主机的可用内存必须大于 3G 才能执行任务:
Cannot request memory (Xms 0 kb, Xmx 0 kb) from system for job- 1
如果你的执行主机没办法增大内存,那么可以通过修改
plugins/jobtypes/目录下的commonprivate.properties文件来关闭内存检查,配置如下:memCheck.enabled=false- 1
-
相关阅读:
Android 11.0 Launcher3去掉抽屉模式 双层改成单层(二)
一个用于翻译 CSV 文件的 Python 脚本,适用于将英文内容批量翻译成中文(或其他语言),并解决文件编码导致的中文乱码和无法翻译的问题。
Linux虚拟机部署与发布项目(Windows版本)
STM32SDIO外设详解
LeetCode 87 双周赛
终于等来了这本用Rust进行系统编程的实践指南
Abbexa丨Abbexa 脱落酸 (ABA) ELISA试剂盒方案
『现学现忘』Git基础 — 25、git log命令参数详解
腾讯云南京地域怎么样?南京服务器IP测速Ping值延迟
03大数据技术之Hadoop(HDFS)
- 原文地址:https://blog.csdn.net/mxk4869/article/details/125516859