-
文本匹配——【NAACL 2022】GPL
论文地址:https://arxiv.org/abs/2112.07577
《文本匹配——【EMNLP 2021】TSDAE》中的自适应预训练的一大缺点是计算开销高,因为必须首先在语料库上运行预训练,然后在标记的训练数据集上进行监督学习。标记的训练数据集可能非常大。
GPL(用于密集检索的无监督域自适应的生成伪标记)克服了上述问题:它可以应用于微调模型之上。因此,可以使用其中一种预训练模型并将其调整到特定领域:

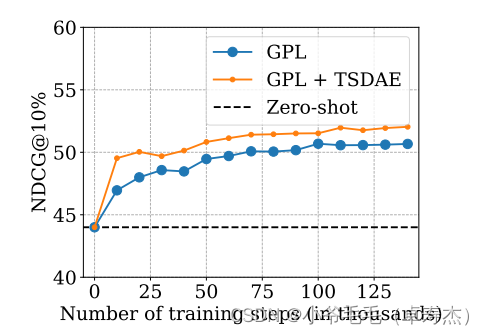
训练的时间越长,你的模型就越好。在 V100-GPU 上训练模型大约 1 天。GPL 可以与自适应预训练相结合,从而进一步提升性能。
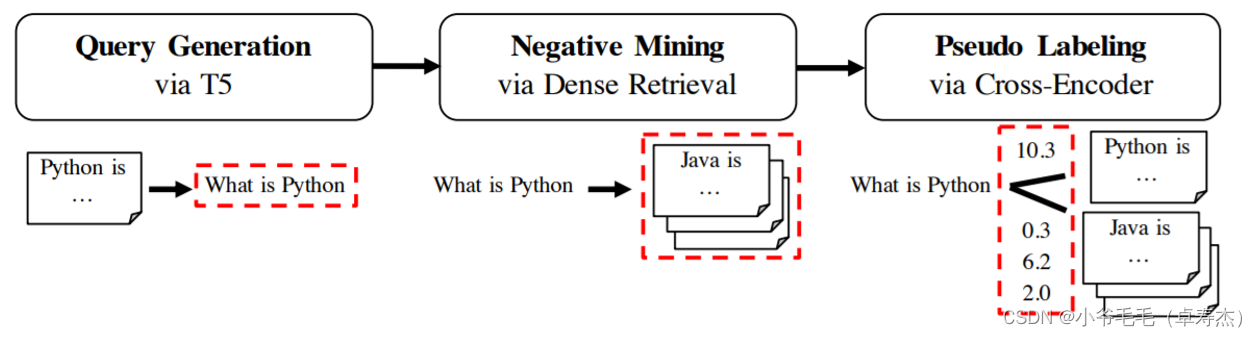
GPL 分三个阶段工作:
-
query 生成:对于我们域中的给定文本,我们首先使用 T5 模型为给定文本生成可能的query。例如,当你的文本是“Python is a high-level general-purpose programming language”时,模型可能会生成类似“What is Python”这样的query。中文T5 Doc2Query 预训练模型地址 :https://huggingface.co/doc2query/msmarco-chinese-mt5-base-v1
-
负例挖掘:接下来,对于生成query “What is Python”,我们从语料库中挖掘负例passage,即与query 相似但用户认为不相关的 passage。这样的负例 passage 可能是“Java is a high-level, class-based, object-oriented programming language.”。. 我们使用密集检索进行这种挖掘,即我们使用现有的文本嵌入模型之一并检索给定query 的相关passage。
-
伪标签:在负例挖掘步骤中,我们检索到与query 实际相关的passage(如 “What is Python” 的另一个定义)。为了克服这个问题,我们使用 Cross-Encoder 对所有(query、passage)对进行评分。
训练:一旦我们有了三元组 (generated query, positive passage, mined negative passage) 和对 (query, positive) 、 (query, negative) 的评分的Cross-Encoder,我们就可以开始使用MarginMSELoss训练文本嵌入模型:
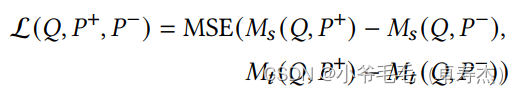
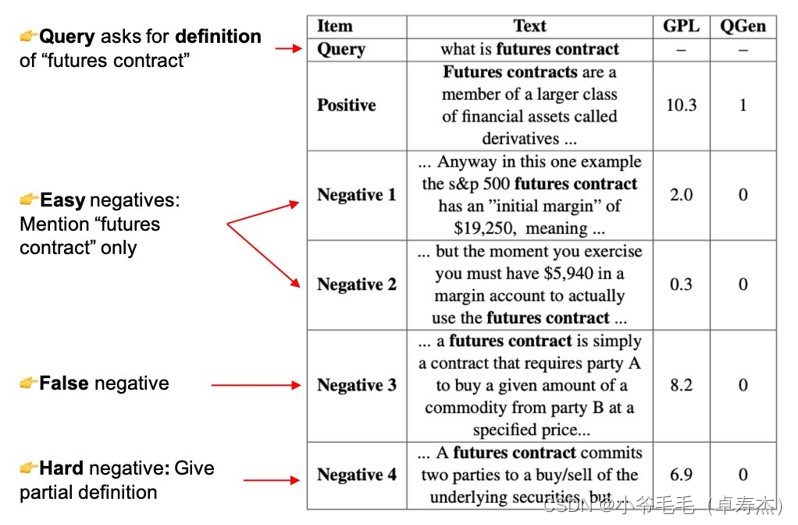
伪标记步骤非常重要,与之前的方法 QGen(《文本匹配——【NeurIPS 2021】BEIR》) 相比,它提高了性能,QGen 将 passages 视为正(1)或负(0)。正如我们在下图中看到的,对于生成query (“what is futures conrtact”),负例挖掘步骤检索与生成query 部分或高度相关的passages。使用 MarginMSELoss 和Cross-Encoder,我们可以识别这些 passages 并教导文本嵌入模型这些段落也与给定查询相关。
下表概述了 GPL 与自适应预训练(MLM 和 TSDAE)的比较。如前所述,GPL 可以与自适应预训练相结合:

-
-
相关阅读:
【源码分析】Spring的循环依赖(setter注入、构造器注入、多例、AOP)
SM4分组密码算法
git学习笔记
C++万字自学笔记
day05_流程控制语句
纳米/聚合物/化合物/无机材料/多肽/多糖修饰聚苯乙烯微球的研究
算法总结-最短距离和问题
C语言实现各类排序算法
华为Atlas 200I DK A2开发者套件--基础使用配置
机房服务器远程维护解决方案,解决机房安全问题刚刚好
- 原文地址:https://blog.csdn.net/u011239443/article/details/125101215