-
HTTP协议知识点总结-DX的笔记
认识HTTP
什么是HTTP协议?
浏览器和web服务器数据通信格式的规范
HTTP协议的内容
请求内容
- 请求行:第一行
- 请求头:第二行开始(键值对形式),空白行结束
- 请求体:空白行的下一行到最后
GET / HTTP/1.1 --- 请求行 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 -- 告诉web服务器我能接收的数据的格式 Accept-Encoding: gzip, deflate, br -- 告诉web服务器我能接收的数据的压缩格式 Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6 Connection: keep-alive -- 长链接 Cookie: BIDUPSID=C89CDDC42430280A02A8B3A69D1F1F44; PSTM=1649580859; COOKIE_SESSION=65028_0_9_9_16_10_1_0_9_8_1_5_65054_0_50_0_1655781073_0_1655781023%7C9%23428923_4_1653121298%7C2; BDRCVFR[sOxo1TgcNNt]=I9fPaKsGu1_UgP8QhP8; BD_HOME=1; H_PS_PSSID=; BDSVRTM=17 --- 客户端存储技术 Host: www.baidu.com -- 这次请求访问的主机 Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: none Sec-Fetch-User: ?1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44 sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows" --- 浏览器所在客户机的运行环境 --- 空白行 表示请求头的结束 --- 请求体(GET方法请求体为空)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
响应内容
- 响应行
- 响应头
- 响应体
HTTP/1.1 200 OK --- 响应行 Bdpagetype: 1 Bdqid: 0xb6aa1b7800000b3d Cache-Control: private Connection: keep-alive Content-Encoding: gzip Content-Type: text/html;charset=utf-8 Date: Tue, 21 Jun 2022 07:36:32 GMT Expires: Tue, 21 Jun 2022 07:36:24 GMT Server: BWS/1.1 Set-Cookie: BDSVRTM=0; path=/ Set-Cookie: BD_HOME=1; path=/ Set-Cookie: H_PS_PSSID=36560_36461_36597_36454_31254_36453_36422_36166_36570_36265_36520_36345_26350_36467_36316; path=/; domain=.baidu.com Strict-Transport-Security: max-age=172800 Traceid: 1655796992269915828213162363063153724221 X-Frame-Options: sameorigin X-Ua-Compatible: IE=Edge,chrome=1 Transfer-Encoding: chunked Location: 指定浏览器地址栏地址,浏览器就会访问这个新地址,主要是配合重定向 Refresh: 告诉浏览器多久刷新这个资源,值是一个正整数 --- 空白行 --- 响应体- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
HTTP请求
请求行
http协议版本 请求资源的地址 请求方式
GET /hello/login.do?user=admin&pass=123 HTTP/1.1- 1
http协议版本
-
http1.0版本: 浏览器和web服务器通讯过程中一次链接只能请求一次(短链接)
http1.1版本: 浏览器和web服务器通讯过程中一次链接能请求多次
目前来讲,都是采用1.1版本(长链接)
-
http与https有什么关系?
http是没有加密的协议,https是加密的http协议,所以https协议相对安全一些,所以一些对 安全性较高的网站已经升级为https协议了.比如12306,baidu等等
请求资源
-
http://localhost:8080/hello/login.do?user=admin&pass=123- 1
-
http:协议
-
localhost:8080:访问的主机和端口号
-
8080:端口号
-
/hello:tomcat部署的项目名
-
/login.do:项目中的资源名
-
?user=admin&pass=123:请求参数
-
URI:统一资源标识符,用来标识网络资源
-
URL:统一资源定位符,是uri的子集,用来标识网络资源.url除了提供uri的信息之外,还给出了访问方式
请求方式
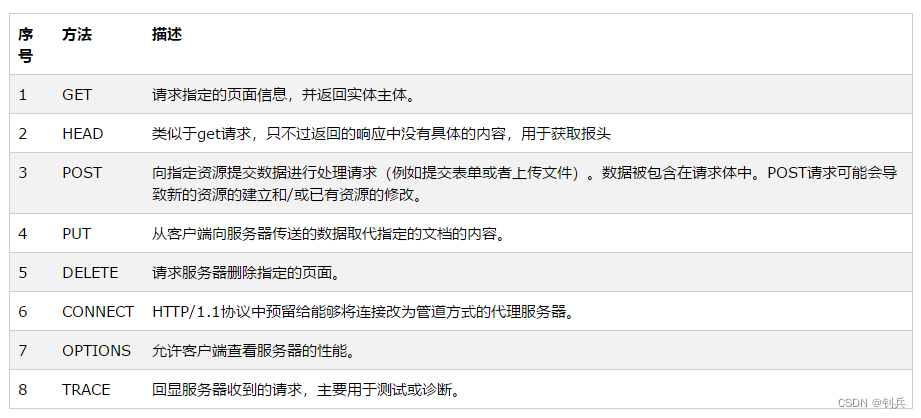
- get方式
- 浏览器输入地址直接访问默认为get方式
- 表单的method属性默认为get方式
- 超链接使用get方式
- post方式
- 表单的method属性设置为post
- get与post的区别
- get的请求特征
- 请求参数使用?跟在网址后
- 请求参数明码显示在地址栏中,不安全
- 请求参数的长度受到url长度的限制
- post的特征
- 请求参数保存在请求体中
- 地址栏看不到,安全
- 参数大小不受限制,所以上传文件一定是post方式
- get的请求特征
请求头
包含了浏览器的运行环境以及返回数据的要求,以键值对的形式出现
请求体
get请求的请求体是空的
post请求的请求体使用流的方式传输
HttpServletRequest对象
web服务器解析请求内容,并将其封装在一个HttpServletRequest对象中
常用的方法
- String getMethod(): 获取请求方式
- String getRequestURI(): 获取访问资源的uri地址
- StringBuffer getRequestURL(): 获取访问资源的url地址
- String getProtocol(): 获取请求的协议
- String getHeader(String name) : 根据请求头名称获取请求头的值
- Enumeration getHeaderNames(): 获取所有请求头名称的集合
- InputStream getInputStream() : 获取输入流读取请求体中的内容
- String getQueryString(): 获取get请求的请求参数
- String getParameter(String paramName) : 根据参数名获取参数值
- String[] getParameterValues(String paramName):获取复选框参数值
- Void setCharacterEncoding(“utf-8”): 设置请求字符集
- String getContextPath(): 获取项目的contextPath路径
service 和 doXX方法区别
- service方法是servlet的入口方法.
- 如果没有重写service方法,servlet执行的时候就会默认使用父类的service方法,父类的service方法中会根据请求方式的不同,调用不同的doxx方法
- 如果重写了service方法,没有显式的调用doxx方法,doxx方法就不会执行
- doxx方法是处理不同类型请求的方法.
- service方法能处理所有类型的请求,service方法优先级高于doxxx方法,如果同时存在,service方法先执行,doxx方法就不执行了.
获取请求参数
-
get请求的请求参数使用getQueryString() 获取,格式: key1=value1&key2=value2…
-
post请求的请求参数使用getInputStream() 获取, 格式: key1=value1&key2=value2…
-
这种方法获取到的参数都拼接在一起,不方便使用
-
servlet提供了一种通用的方式获取请求参数
req.setCharacterEncoding("utf-8"); //设置编码,解决中文乱码问题 String pass = req.getParameter("pass"); String[] love = req.getParameterValues("love"); String user = req.getParameter("user"); System.out.println("参数名是:love,参数值是:" + Arrays.toString(love));- 1
- 2
- 3
- 4
- 5
请求参数编码问题
-
get请求
- 程序使用的字符集是utf-8
- tomcat 8以前版本url使用的字符集是:iso-8859-1
- tomcat 8以后版本url使用的字符集是:utf-8
- 使用tomcat 8前的版本会出现中文乱码问题
- 解决方法:new String(param.getBytes(“iso-8859-1”),”utf-8”)
-
post请求
-
tomcat里面使用的字符集是:iso-8859-1
-
解决办法:在获取请求参数之前,设置请求中的字符集,否则无效
req.setCharacterEncoding("utf-8"); //设置编码(Post请求默认编码就是utf-8,可以不用设置)- 1
-
post方式中文处理更方便
-
HTTP响应
响应行
-
协议 响应状态码 状态码的描述信息
-
HTTP/1.1 200 OK- 1
响应状态码
- 1xx:请求未结束
- 2xx:正常的响应 200 一切正常
- 3xx:重定向 302 临时重定向
- 4xx:客户端异常 404 资源找不到或者资源是受保护的
- 5xx:服务端异常 500 服务端程序抛异常
设置响应状态码
- setStatus(int num) : 通用的设置响应状态码
- SendError(int num): 设置错误状态码
- SendError(int num,String msg): 设置错误状态码,并给出错误提示信息
响应头
- Content-Type:回送数据的类型
- Location:配合302状态码使用,重定向
- Refresh:设置刷新事件
- Content-Disposition:以附件的形式下载资源
HttpServletResponse对象
- 这个对象可以设置响应头和响应体
- 常用的方法
- setStatus(int num) : 通用的设置响应状态码
- sendError(int num): 设置错误状态码
- sendError(int num,String msg): 设置错误状态码,并给出错误提示信息
- setHeader(String name,String value): 设置响应头
- getOutputStream(): 获取响应输出流
- sendRedirect(String sources): 重定向资源的地址
重定向
-
作用:返回一个事先写好的页面
-
实现方法一 (配置响应头)
-
//设置响应状态码,302表示临时重定向 resp.setStatus(302); //设置访问的新资源的地址 resp.setHeader("Location","/hello/success.html";- 1
- 2
- 3
- 4
-
-
实现方法二(简化方式)
-
//使用简化方式实现重定向 resp.sendRedirect(req.getContextPath() + "/success.html");- 1
- 2
-
-
注意事项
- 重定向的资源可以是项目内的,也可以是项目外的,所以路径前需要加上项目名称
- 重定向一共发起2次请求
- 重定向后不能再写代码了
定时刷新(refresh)
//每隔1秒钟刷新一次当前资源 resp.setHeader("Refresh","1"); //访问本资源3秒钟后,访问新资源 resp.setHeader("Refresh","3;url=http://www.baidu.com")- 1
- 2
- 3
- 4
设置响应的数据类型
//设置返回数据的类型 resp.setHeader("Content-Type","text/html;charset=utf-8"); //使用简化版的方式设置返回数据类型 resp.setContentType("text/html;charset=utf-8");- 1
- 2
- 3
- 4
-
思考两种编码方式的区别?
-
//通过设置响应头,告诉浏览器我要发的编码格式 resp.setContentType("text/html;charset=utf-8"); //直接将发送的数据流设置为utf-8格式 resp.setCharacterEncoding("utf-8");- 1
- 2
- 3
- 4
实现下载功能
-
Content-Type: 服务器告诉客户端返回的数据类型和字符集
-
数据类型的描述方式:大的数据类型/小的数据类型,比如 text/html,image/png
-
servlet提供了一个相对简单的方法:setContentType(String type)
-
实现下载的功能来体现Content-Type和Content-Disposition的效果
// 下载的实现本质就是将下载的文件内容使用响应输出流输出到浏览器 // 1.设置返回数据类型 resp.setContentType("image/webp"); // 2.设置下载文件后的处理方式(不要直接使用浏览器打开,以附件的形式下载并另存为) //值的格式: attachment; filename=foobar.pdf resp.setHeader("Content-Disposition","attachment;filename=haha.webp"); // 3.使用输入流读取本地磁盘图片内容,使用响应输出流输出到浏览器 InputStream is = new FileInputStream("D:\\4.webp"); OutputStream os = resp.getOutputStream(); byte[] bs = new byte[1024]; int length = 0; while ((length = is.read(bs)) != -1){ os.write(bs,0,length); } // 4.关闭流 is.close(); os.close(); achment;filename=haha.webp"); // 3.使用输入流读取本地磁盘图片内容,使用响应输出流输出到浏览器 InputStream is = new FileInputStream("D:\\4.webp"); OutputStream os = resp.getOutputStream(); byte[] bs = new byte[1024]; int length = 0; while ((length = is.read(bs)) != -1){ os.write(bs,0,length); } // 4.关闭流 is.close(); os.close();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
-
相关阅读:
1.2.OpenCV技能树--第一单元--OpenCV安装
《QT+PCL第六章》点云配准icp系列5
Tomcat开发配置教程
Python入门笔记
java毕业设计——基于java+Eclipse+jsp的网上手机销售系统设计与实现(毕业论文+程序源码)——网上手机销售系统
多机器人仓储巡逻路径规划问题的A*算法实现(附带MATLAB代码)
js第八章
2022跨境电商新战场:海外社交电商发展前景分析
深度学习学习笔记-模型的修改和CRUD
基于vue项目的代码优化
- 原文地址:https://blog.csdn.net/qq_43528471/article/details/125509842
