-
Linux 进程管理
Linux内核

Linux内核子系统之间关系

进程概念
操作系统作为硬件的使用层,提供使用硬件资源的能力,进程作为操作系统使用层,提供使用操作系统抽象出的资源层的能力。进程:是指计算机中已运行的程序。进程本身不是基本的运行单位,而是线程的容器。程序本身只是指令、数据及其组织形式的描述,进程才是程序(那些指令和数据)的真正运行实例使用ps 命令可以查看Linux的进程信息进程的四要要素
(1)有一段程序供其执行,即使是和其他进程共用;
(2)有进程专用的系统堆栈空间;
(3)有task_struct数据结构,也就是进程控制块。有了这个数据结构,进程才能成为内核调度的一个基本单位,从而接受内核的调度。但同时,该数据结构也记录着进程所占用的各项资源;
(4)有独立的存储空间,即用户空间堆栈。这四条都是必要条件,缺一不可,如果仅仅具备前三条则就只能称作是线程了。如果完全没有用户空间,就称作是“内核线程”;而共享用户空间就称作是“用户线程”。也统称线程。
另外,在linux系统中“进程”和“任务”是同一个意思,主要是因为linu想源自Unix和i376系统结构。而Unix中的进程在Intel的技术资料中则称为“任务”。
进程生命周期
Linux操作系统属于多任务操作系统,系统中的每个进程能够分时复用 CPU 时间片,通过有效的进程调度策略实现多任务并行执行。而进程在被 CPU 调度运行,等待 CPU 资源分配以及等待外部事件时会属于不同的状态。进程之间的状态关系:运行: 该进程此刻正在执行。等待: 进程能够运行,但没有得到许可,因为 CPU 分配给另一个进程。调度器可以在下一次任务切换时选择该进程。睡眠: 进程正在睡眠无法运行,因为它在等待一个外部事件。调度器无法在下一次任务切换时选择该进程。
task_struct数据结构
Linux内核涉及进程和程序的所有算法都围绕一个名为 task_struct 的数据结构建立,该结构定义在 include/linux/sched.h 中。这是系统中主要的一个结构。在阐述调度器的实现之前,了解一下 Linux 管理进程的方式是很有必要的。task_struct包含很多成员,将进程与各个内核子系统联系, task_struct 定义如下:



进程优先级
并非所有进程都具有相同的重要性。除了大多数我们所熟悉的进程优先级之外,进程还有不同的关键度类别,以满足不同需求。进程系统调用
讨论fork 和 exec 系列系统调用的实现。通常这些调用不是由应用程序直接发出的,而是通过一个中间层调用,即负责与内核通信的C标准库。从用户状态切换到核心态的方法,依不同的体系结构而各有不同。系统调用(System Call)是操作系统为在用户态运行的进程与硬件设备(如CPU、磁盘、打印机等)进行交互提供的一组接口。当用户进程需要发生系统调用时,CPU 通过软中断切换到内核态开始执行内核系统调用函数。

linux系统调用_One Piece&的博客-CSDN博客_linux 系统调用
Linux 下三种发生系统调用的方法:linux系统调用的三种方法_赶路人儿的博客-CSDN博客_linux系统调用
1、进程复制
传统的UNIX 中用于复制进程的系统调用是 fork 。但它并不是 Linux 为此实现的唯一调用,实际上 Linux 实现了 3 个。(1) fork是重量级调用,因为它建立了父进程的一个完整副本,然后作为子进程执行。为减少与该调用相关的工作量, Linux 使用了写时复制(copy-on-write )技术。(2) vfork类似于 fork ,但并不创建父进程数据的副本。相反,父子进程之间共享数据。这节省了大量 CPU 时间(如果一个进程操纵共享数据,则另一个会自动注意到)。(3) clone产生线程,可以对父子进程之间的共享、复制进行精确控制【写时复制】内核使用了写时复制( Copy-On-Write , COW )技术,以防止在 fork 执行时将父进程的所有数据复制到子进程。在调用 fork 时,内核通常对父进程的每个内存页,都为子进程创建一个相同的副本。 【执行系统调用】fork 、 vfork 和 clone 系统调用的入口点分别是 sys_fork 、 sys_vfork 和 sys_clone 函数。其定义依赖于具体的体系结构,因为在用户空间和内核空间之间传递参数的方法因体系结构而异。【do_fork实现】所有 3 个 fork 机制最终都调用 kernel/fork.c 中的 do_fork (一个体系结构无关的函数),其代码流程如图所示。do_fork代码流程图:
【执行系统调用】fork 、 vfork 和 clone 系统调用的入口点分别是 sys_fork 、 sys_vfork 和 sys_clone 函数。其定义依赖于具体的体系结构,因为在用户空间和内核空间之间传递参数的方法因体系结构而异。【do_fork实现】所有 3 个 fork 机制最终都调用 kernel/fork.c 中的 do_fork (一个体系结构无关的函数),其代码流程如图所示。do_fork代码流程图:
2、内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上,也并行于内核自身的执行)。内核线程经常称之为(内核)守护进程。它们用于执行下列任务。• 周期性地将修改的内存页与页来源块设备同步(例如,使用 mmap 的文件映射)。• 如果内存页很少使用,则写入交换区。• 管理延时动作(deferred action )。• 实现文件系统的事务日志。3 退出进程
进程必须用exit 系统调用终止。这使得内核有机会将该进程使用的资源释放回系统。见kernel/exit.c------>do_exit 。简而言之, 该函数的实现就是将各个引用计数器减1 ,如果引用计数器归 0 而 没有进程再使用对应的结构,那么将相应的内存区域返还给内存管理模块
调度器
调度器分析
调度器及其功能
内核中用来安排进程执行的模块称为调度器(scheduler),它可以切换进程状态 (process state)。例如执行、可中断睡眠、不可中断睡眠、退出、暂停等。 调度器是CPU中央处理器的管理员,主要负责完成做两件事情:一、选择某些就绪进程来执行,二是打断某些执行的进程让它们变为就绪状态。
调度器分配CPU时间的基本依据就 是进程的优先级。上下文切换(context switch):将进程在CPU中切换执行的过程,内核承担此任务,负责重建和存储被切换掉之前的CPU状态。
调度类sched_class结构体
sched_class结构体表示调度类,定义在kernel/sched/sched.h

Linux调度类:stop_sched_class, dl_sched_class、rt_sched_class、fair_sched_class及idle_sched_class等。



调度类


优先级
task_struct结构体中采用三个成员表示进程的优先级:
prio和normal_prio表示动态优先级
static_prio表示进程的静态优先级。
内核将任务优先级划分,实时优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139)。
Linux内核源码:/include/linux/sched/prio.h


调度策略
linux内核调度策略源码:/include/uapi/linux/sched.h


完全公平调度器CFS
1、完全公平调度CFS算法基本原理
完全公平调度算法体现在对待每个进程都是公平的,让每个进程都运行一段相同的时间片,这就是基于时间片轮询调度算法。 CFS定义一种新调度模型,它给cfs_rq(cfs的run queue)中的每一个进程都设置一个虚 拟时钟virtual runtime(vruntime)。如果一个进程得以执行,随着执行时间的不断增长,其 vruntime也将不断增大,没有得到执行的进程vruntime将保持不变。

2、调度器结构分析

3、完全公平调度器CFS数据结构
CFS完全公平调度器的调度器类叫fair_sched_class。
Linux内核源码目录: kernel/sched/fair.c,
struct sched_class调度器类类型,将我们的CFS调度器和一些特定的函数关联 起来

4、完全公平调度器CFS就绪队列
调度管理是各个调度器的职责。CFS的顶级调度就队列 struct cfs_rq,Linux内核源码目 录:kernel/sched/sched.h。
CFS调度运行队列, 每一个CPU的rq会有一个cfs_rq,每个组掉调度的sched_entity也会有一个cfs_rq.

Linux内核的三种调度策略

1.SCHED_OTHER 分时调度策略2.SCHED_FIFO 实时调度策略,先到先服务。一旦占用cpu则一直运行。一直运行直到有更高优先级任务到达或自己放弃
3.SCHED_RR实 时调度策略,时间片轮转。当进程的时间片用完,系统将重新分配时间片,并置于就绪队列尾。放在队列尾保证了所有具有相同优先级的RR任务的调度公平。
Linux线程优先级设置:
首先,可以通过以下两个函数来获得线程可以设置的最高和最低优先级,函数中的策略即上述三种策略的宏定义:int sched_get_priority_max(int policy);
int sched_get_priority_min(int policy);
注意:SCHED_OTHER 是不支持优先级使用的,而 SCHED_FIFO 和 SCHED_RR 支持优先级的使用,他们分别为1和99,数值越大优先级越高。
设置和获取优先级通过以下两个函数:
int pthread_attr_setschedparam(pthread_attr_t *attr, const struct sched_param *param);
int pthread_attr_getschedparam(const pthread_attr_t *attr, struct sched_param *param); param.sched_priority = 51; //设置优先级
系统创建线程时,默认的线程是 SCHED_OTHER。所以如果我们要改变线程的调度策略的话,可以通过下面的这个函数实现。
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
上面的param使用了下面的这个数据结构:
struct sched_param {
int __sched_priority; // 所要设定的线程优先级
};
我们可以通过下面的测试程序来说明,我们自己使用的系统的支持的优先级:
设置和获取线程优先级:
- #include <stdio.h>
- #include <pthread.h>
- #include <sched.h>
- #include <assert.h>
- static int api_get_thread_policy (pthread_attr_t *attr)
- {
- int policy;
- int rs = pthread_attr_getschedpolicy (attr, &policy);
- assert (rs == 0);
- switch (policy)
- {
- case SCHED_FIFO:
- printf ("policy = SCHED_FIFO\n");
- break;
- case SCHED_RR:
- printf ("policy = SCHED_RR");
- break;
- case SCHED_OTHER:
- printf ("policy = SCHED_OTHER\n");
- break;
- default:
- printf ("policy = UNKNOWN\n");
- break;
- }
- return policy;
- }
- static void api_show_thread_priority (pthread_attr_t *attr,int policy)
- {
- int priority = sched_get_priority_max (policy);
- assert (priority != -1);
- printf ("max_priority = %d\n", priority);
- priority = sched_get_priority_min (policy);
- assert (priority != -1);
- printf ("min_priority = %d\n", priority);
- }
- static int api_get_thread_priority (pthread_attr_t *attr)
- {
- struct sched_param param;
- int rs = pthread_attr_getschedparam (attr, ¶m);
- assert (rs == 0);
- printf ("priority = %d\n", param.__sched_priority);
- return param.__sched_priority;
- }
- static void api_set_thread_policy (pthread_attr_t *attr,int policy)
- {
- int rs = pthread_attr_setschedpolicy (attr, policy);
- assert (rs == 0);
- api_get_thread_policy (attr);
- }
- int main(void)
- {
- pthread_attr_t attr; // 线程属性
- struct sched_param sched; // 调度策略
- int rs;
- /*
- * 对线程属性初始化
- * 初始化完成以后,pthread_attr_t 结构所包含的结构体
- * 就是操作系统实现支持的所有线程属性的默认值
- */
- rs = pthread_attr_init (&attr);
- assert (rs == 0); // 如果 rs 不等于 0,程序 abort() 退出
- /* 获得当前调度策略 */
- int policy = api_get_thread_policy (&attr);
- /* 显示当前调度策略的线程优先级范围 */
- printf ("Show current configuration of priority\n");
- api_show_thread_priority(&attr, policy);
- /* 获取 SCHED_FIFO 策略下的线程优先级范围 */
- printf ("show SCHED_FIFO of priority\n");
- api_show_thread_priority(&attr, SCHED_FIFO);
- /* 获取 SCHED_RR 策略下的线程优先级范围 */
- printf ("show SCHED_RR of priority\n");
- api_show_thread_priority(&attr, SCHED_RR);
- /* 显示当前线程的优先级 */
- printf ("show priority of current thread\n");
- int priority = api_get_thread_priority (&attr);
- /* 手动设置调度策略 */
- printf ("Set thread policy\n");
- printf ("set SCHED_FIFO policy\n");
- api_set_thread_policy(&attr, SCHED_FIFO);
- printf ("set SCHED_RR policy\n");
- api_set_thread_policy(&attr, SCHED_RR);
- /* 还原之前的策略 */
- printf ("Restore current policy\n");
- api_set_thread_policy (&attr, policy);
- /*
- * 反初始化 pthread_attr_t 结构
- * 如果 pthread_attr_init 的实现对属性对象的内存空间是动态分配的,
- * phread_attr_destory 就会释放该内存空间
- */
- rs = pthread_attr_destroy (&attr);
- assert (rs == 0);
- return 0;
- }
编译 g++ test.cc -o test. -lpthread
输出:

RCU机制
RCU英文全称为Read-Copy-Update,顾名思义就是 “读 - 拷贝-更新”,是内核中重要的同步机制。Linux内核已有原子操作、读写信号量等等锁机制,为何会单独设计一个比较复杂的新机制?
读写信号量通过加锁来实现,性能较差;且只允许多个读者同时存在 ,读者和写者不能同时存在;RCU机制希望同步开销变得很小,不需要使用原子操作指令。
RCU原理
RCU记录所有指向共享数据的指针的使用者,当要修改该共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开读临界区之后 ,指针指向新的修改后副本的指针, 并且删除旧数据。


链表操作
RCU能保护的不仅仅是一般的指针。内核也提供标准函数,使得能通过RCU机制保护双链表,这是RCU机制在内核内部最重要的应用。 有关通过RCU保护的链表,好消息是仍然可以使用标准的链表元素。只有在遍历链表、修改和删除链表元素时,必须调用标准函数的RCU变体。函数名称很容易记住:在标准函数之 后附加_rcu后缀。
RCU标准:内核源码分析:/include/linux/rculist.h
- static inline void list_add_rcu(struct list_head *new, struct list_head *head) static inline void list_add_tail_rcu(struct list_head *new,struct list_head *head) static inline void list_del_rcu(struct list_head *entry)
- static inline void list_replace_rcu(struct list_head *old,struct list_head *new)


RCU层次架构
RCU根据CPU数量的大小按照树形结构来组成其层次结构,称为RCU Hierarchy。
内核源码分析:/kernel/rcu/tree.h


优化内存屏障
优化屏障
在编程时,指令一般不按照源程序顺序执行,原因是为提高程序执行性能,会对它进行优化,主要为两种:编译器优化和CPU执行优化。 优化屏障避免编译的重新排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
Linux使用宏barrier实现优化屏障,如gcc编译器的优化屏障宏定义如: linux内核源码:include/linux/compiler-gcc.h。

上述定义中,“__asm__”表示插入了汇编语言程序,“__volatile__”表示阻止编译器对该值进行优化,确保变量使用了用户定义的精确地址,而不是装有同一信息的一些别名。“memory”表示指令修改了内存单元。
内存屏障
软件可通过读写屏障强制内存访问次序。读写屏障像一堵墙,所有在设置读写屏障之前发起的内存访问,必须先于在设置屏障之后发起的内存访问之前完成,确保内存访问按程序的顺序完成。
读写屏障通过处理器构架的特殊指令mfence(内存屏障)、lfence(读屏障)和sfence(写屏障)完成,见《x86-64构架规范》一章。另外,在x86-64处理器中,对硬件进行操作的汇编语言指令是“串行的”,也具有内存屏障的作用,如:对I/O端口进行操作的所有指令、带lock前缀的指令以及写控制寄存器、系统寄存器或调试寄存器的所有指令(如:cli和sti)。
Linux内核提供的内存屏障API函数说明如表2。内存屏障可用于多处理器和单处理器系统,如果仅用于多处理器系统,就使用smp_xxx函数,在单处理器系统上,它们什么都不要。
内存屏障作用:无锁数据结构
内核内存布局
64位Linux一般使用48位来表示虚拟地址空间,43位表示物理地址, 通过命令:cat /proc/cpuinfo
debian 系统使用36位表示物理地址
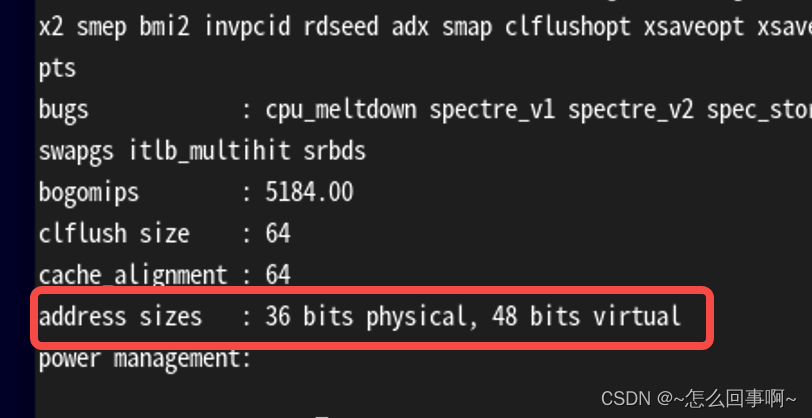
ARM64架构处理器采用48位物理寻址机制,最大可寻找256TB的物理地址空间。对于 目前应用完全足够,不需要扩展到64位的物理寻址。虚拟地址也同样最大支持48位寻址,所以 在处理器架构设计上,把虚拟地址空间划分为两个空间,每个空间最大支持256TB,linux内核 在大多数体系结构上都把两个地址划分为:用户空间和内核空间。
用户空间:0x0000_0000_0000_0000至0x0000_ffff_ffff_ffff。 内核间:0xffff_0000_0000_0000至0xffff_ffff_ffff_ffff。




堆管理
堆是进程中主要用于动态分配变量和数据 的内存区域,堆的管理对应程序员不是直接可见 的。因为它依赖标准库提供的各个辅助函数(其中最重要的是malloc)来分配任意长度的内存区。 malloc和内核之间的经典接口是brk系统调用,负责扩展/收缩堆。
堆是一个连续的内存区域,在扩展时自下至上增长。其中mm_struct结构,包含堆在虚拟地 址空间中的起始和当前结束地址(start_brk和brk)。


brk系统调用用于指定堆在虚拟地址空间中新的结束地址(如果堆将要收缩,当然可以 小于当前值)。brk系统调用通过do_brk增长动态分配区(内核源码分析mm/mmap.c):
-
相关阅读:
linux 发行版中在容器内访问热插拔 U 盘的分区内容
星宸科技SSC369G 双4K高性价比AI IPC方案
双目3D感知(一):双目初步认识
文本分析,组间插入汇总值
综合电商商城小程序的作用是什么
Python import module package 相关
QTday05(TCP的服务端客户端通信)
【AI视野·今日NLP 自然语言处理论文速览 第五十二期】Wed, 11 Oct 2023
list
Tmux 简单使用
- 原文地址:https://blog.csdn.net/LIJIWEI0611/article/details/125473704
